-- hive的库、表等数据操作实际是hdfs系统中的目录和文件,让开发者可以通过sql语句, 像操作关系数据库一样操作文件内容。
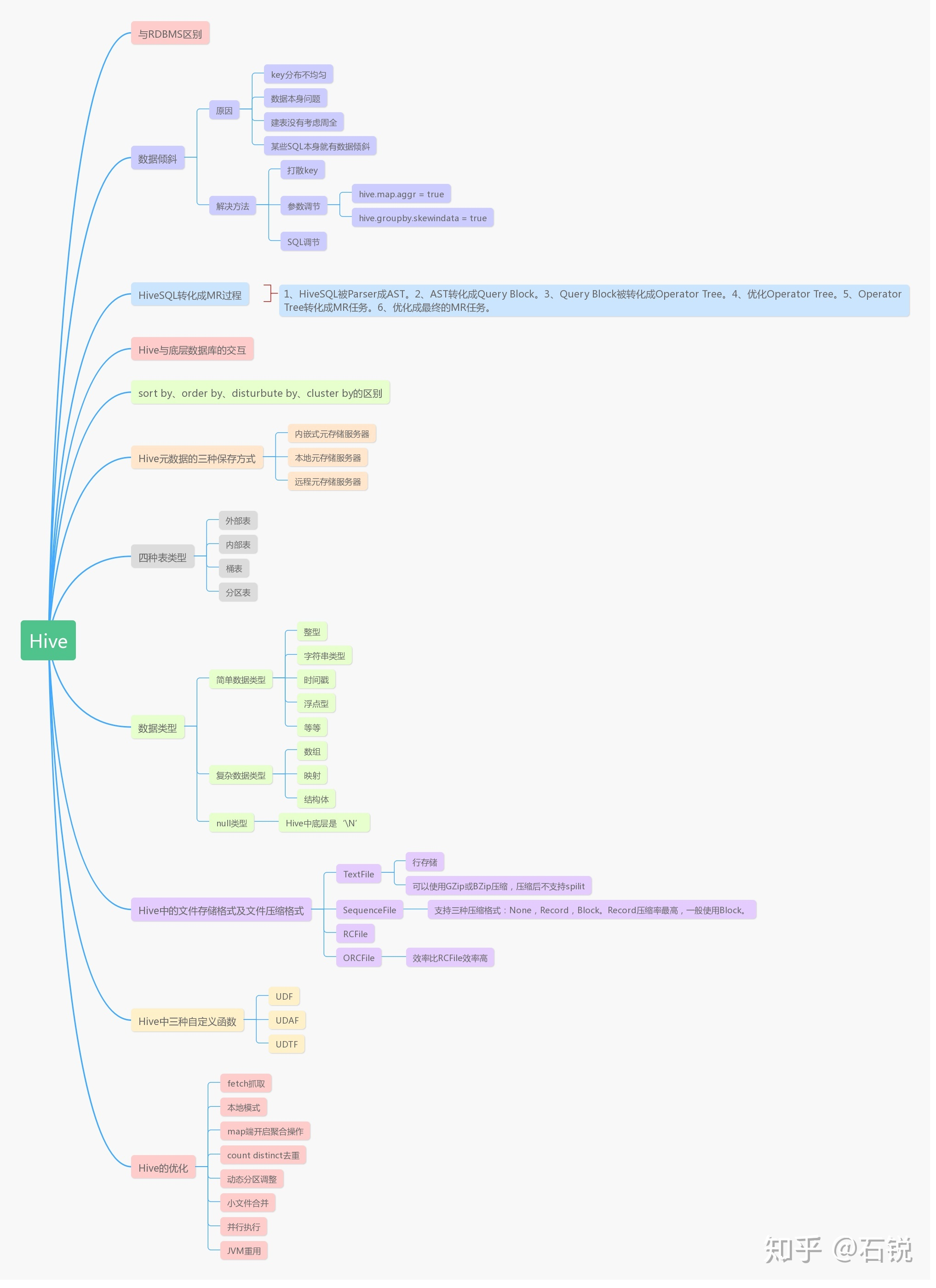
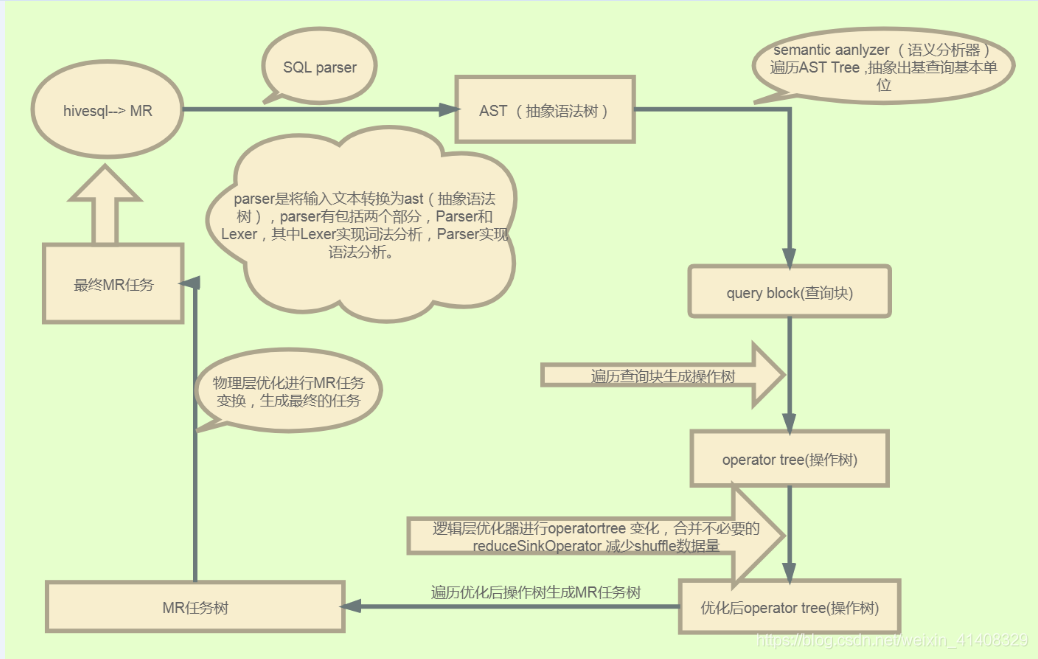
一、hiveSQL转化为MR过程
一直好奇hiveSQL转化为MR过程,好奇hive是如何做到这些的,所以在网上找了几篇相关博客,根据自己理解重新画了一份执行过程图,做笔记。
二、hive 执行过程中数据倾斜问题
1.描述:
数据倾斜主要表现在,MR程序执行过程中,reduce节点大部分执行完毕,但是有一个或者少数几个节点运行很慢,导致整个程序的处理时间很长。这是因为该reduce处理节点对应的key对应数据条数远超于其他key导致该节点处理数据量太大而不能和其他节点同步完成执行。简而言之,解释同一key对应数据条数太多导致。常见有空值key。
2.原因:
2.1、key分布不均匀。
2.2、业务数据本身的原因。
2.3、建表考虑不周。
2.4、某些SQL本身就有数据倾斜。
3.解决方式:
3.1、给key一个随机值,打乱key,进行第一步操作,然后第二步去掉随机值再处理。
3.2、参数调节:
hive.map.aggr = true Map 端部分聚合,相当于Combiner。
hive.groupby.skewindata=true(万能) 。有数据倾斜的时候进行负载均衡,当选项设定为 true,生成的查询计划会有两 个 MR Job。
第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;
第二个MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分 布到同一个 Reduce 中),最后完成最终的聚合操作。
3.3、SQL语句调节:
3.3.1 大小表Join:使用map join让小的维度表(1000条以下的记录条数) 先进内存。在map端完成reduce.
3.3.2 大表Join大表:把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终结果。
3.3.3 count distinct大量相同特殊值:count distinct时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
3.3.4 group by维度过小:采用sum() group by的方式来替换count(distinct)完成计算。
3.3.5 特殊情况特殊处理:在业务逻辑优化效果的不大情况下,有些时候是可以将倾斜的数据单独拿出来处理。最后union回去。
3.4、map和reduce优化。
3.4.1 当出现小文件过多,需要合并小文件。可以通过set hive.merge.mapfiles=true来解决。
3.4.2 单个文件大小稍稍大于配置的block块的大写,此时需要适当增加map的个数。解决方法:set mapred.map.tasks个数
3.4.3 文件大小适中,但map端计算量非常大,如select id,count(*),sum(case when...),sum(case when...)...需要增加map个数。解决方法:set mapred.map.tasks个数,set mapred.reduce.tasks个数
4.Hive的优化:
4.1、配置fetch抓取:修改配置文件hive.fetch.task.conversion为more,修改之后全局查找和字段查找以及limit都不会触发MR任务。
4.2、善用本地模式:大多数的Hadoop Job要求Hadoop提供完整的可扩展性来触发大数据集,不过有时候hive的输入数据量非常的小,这样的情况下可能触发任务的事件比执行的事件还长,我们就可以通过本地模式把小量的数据放到本地上面计算。
4.3、Group by:默认情况下,map阶段同一key的数据会发给一个reduce,当一个key数据过大就会倾斜,并不是所有的聚合操作都需要reduce端完成,很多聚合操作都可以现在map端进行部分聚合,最后在reduce端得出最终结果。
4.3.1 开启在map端聚合:hive.map.aggr = true。
4.3.2 在map端进行聚合操作的条目数:hive.groupby.mapaggr.checkinterval = 100000。
4.3.3 有数据倾斜的时候进行负载均衡:hive.groupby.skewindata = true。
4.4、行列过滤:列处理:只拿自己需要的列,如果有,尽量使用分区过滤。行处理:在分区裁剪的时候,当使用外关联的时候,先完全关联再过滤。
4.5、动态分区调整:(慎用)
4.5.1 开启动态分区:hive.exec.dynamic.partition=true。
4.5.2 设置为非严格模式:hive.exec.dynamic.partiton.mode = nostrict。
4.5.3 实操:创建分区表、加载数据到分区表中、创建目标分区、设置动态分区、查看目标分区表的分区情况。
4.6、小文件进行合并:在map执行之前合并小文件,减少map的数量,设置 set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat。
4.7、调整map的数量和reduce的数量。
4.8、并行执行:在Hive中可能有很多个阶段,不一定是一个阶段,这些阶段并非相互依赖的。然后这些阶段可以并行完成,设置并行:set hive.exec.parallel = true。
4.9、JVM的重用,缺点是task槽会被占用,一直要等到任务完成才会释放。
转载:https://blog.csdn.net/weixin_41408329/article/details/106116543