Hive中HSQL中left semi join和INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN区别
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
sql中的连接查询有inner join(内连接)、left join(左连接)、right join(右连接)、full join(全连接)left semi join(左半连接)五种方式,它们之间其实并没有太大区别,仅仅是查询出来的结果有所不同。
(1)重要的放在前面,union和full join on的区别,“full join on 列合并和 union 行合并”:
1) full join 使用on条件时,select * 相当于把两个表(左表有m列p行和右表有n列q行)的所有列拼接成了一个有m+n列的结果表。
select * from table1 full join table2 on(table1.student_no=table2.student_no);
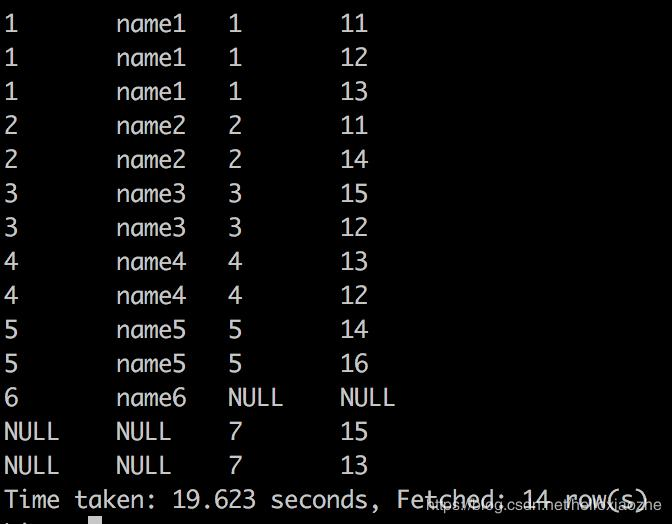
2)而union相当于把 相当于把两个查询结果(左查询结果表有m列p行和右查询结果表有n列q行)的所有行进行了拼接,形成具有p+q行的查询结果。
select student_no tb1_student_no,student_name from table1 union select student_no as tb2_student_no,class_no from table2;
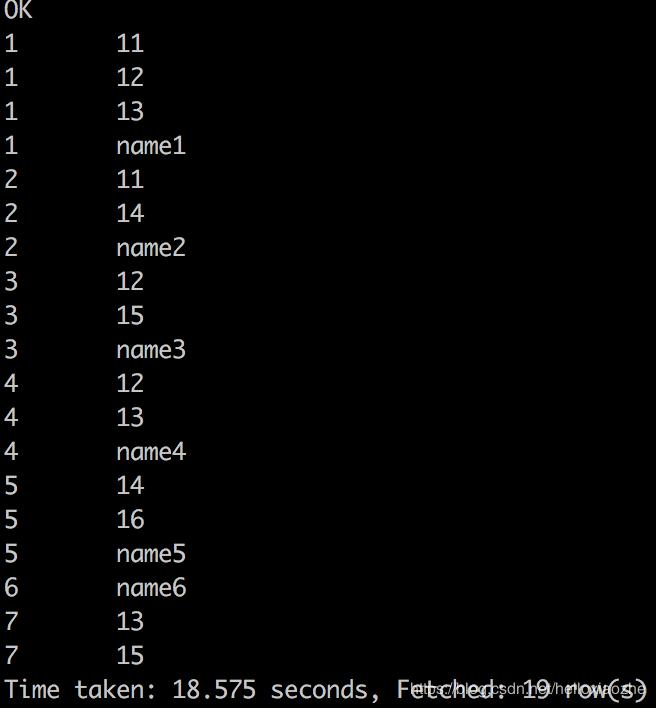
注意此时 ,左查询结果表和右查询结果表,必须有相同的列,即m=q相等,否则会报如下错误:
hive> select student_no tb1_student_no,student_name from table1 union select class_no from table2;
FAILED: SemanticException Schema of both sides of union should match.
(2)Inner join是最简单的关联操作,
1)如果有on 条件的话,则两边关联只取交集。
select * from table1 join table2 on table1.student_no=table2.student_no ;
2)笛卡尔积:如果没有on条件的话,则是左表和右表的列通过笛卡尔积的形式表达出来,下面两个sql就是求笛卡尔积:
select * from table1 join table2;
select * from table1 inner join table2;
比如table1有m行,table2有n行,最终的结果将有 m*n行
(3)outer join分为left outer join、right outer join和full outer join。
left outer join是以左表驱动,右表不存在的key均赋值为null;
right outer join是以右表驱动,左表不存在的key均赋值为null;
full outer join全表关联,即是左外连接和右外连接结果集合求并集 ,左右表均可赋值为null。(而不是将两表完整的进行笛卡尔积操作,这种表述是错误的,注意某些博客的表述)
如果full join不加on过滤条件,计算结果也是笛卡尔积:
select * from table1 a full join table2 b ;
(4)left semi join
semi join (即等价于left semi join)最主要的使用场景就是解决exist in。LEFT SEMI JOIN (左半连接)是 IN/EXISTS 子查询的一种更高效的实现。
注意,在hive 2.1.1版本中,支持子查询,使用in 和 not in关键字,以下两个SQL都是正确的:
SELECT * FROM TABLE1 WHERE table1.student_no NOT IN (SELECT table2.student_no FROM TABLE2);
SELECT * FROM TABLE1 WHERE table1.student_no IN (SELECT table2.student_no FROM TABLE2);
以下为两个测试数据表建表语句:
use test;
DROP TABLE IF EXISTS table1;
create table table1(
student_no bigint comment '学号',
student_name string comment '姓名'
)
COMMENT 'test 学生信息'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
LINES TERMINATED BY ' '
STORED AS TEXTFILE;
DROP TABLE IF EXISTS table2;
create table table2(
student_no bigint comment '学号',
class_no bigint comment '课程号'
)
COMMENT 'test 学生选课信息'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
LINES TERMINATED BY ' '
STORED AS TEXTFILE;
测试数据如下:
[work@ha6-prd-dx rk]$ more data_table1.txt
1 name1
2 name2
3 name3
4 name4
5 name5
6 name6
[work@ha6-prd-dx rk]$ more data_table2.txt
1 11
1 12
1 13
2 11
2 14
3 12
3 15
4 12
4 13
5 14
5 16
7 13
7 15
入库命令如下:
load data local inpath '/home/work/yyz_work/data_table1.txt' overwrite into table table1 ;
load data local inpath '/home/work/yyz_work/data_table2.txt' overwrite into table table2 ;
测试一、测试子查询:证明在Hive 2.1.1版本中,是支持where子句中的子查询 in 和 not in,但是 HSQL常用的exist 子句在Hive中是不支持的。
SELECT table1.student_no, table1.student_name
FROM table1
WHERE table1.student_no in (SELECT table2.student_no FROM table2);

测试二、 测试 left semi join
证明在Hive 2.1.1版本中,是支持where子句中的子查询,SQL常用的exist in子句在Hive中是不支持的,但可以使用一个更高效的实现方式---- semi join最主要的使用场景就是解决exist in。

SQL1:
SELECT table1.student_no, table1.student_name FROM table1 LEFT SEMI JOIN table2 on ( table1.student_no =table2.student_no);
SQL2:
SELECT * FROM table1 LEFT SEMI JOIN table2 on ( table1.student_no =table2.student_no);
SQL1和SQL2等价,只输出左表包含的那些列。且输出结果如下:
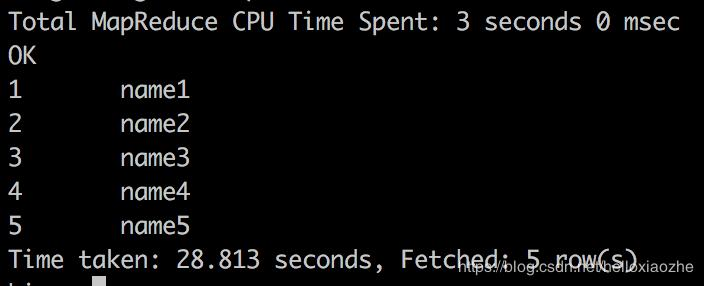
可以看到,只打印出了左边的表中的列,规律是如果主键在右边表中存在,则打印,否则过滤掉了。以上两个测试证明在博客https://blog.csdn.net/AntKengElephant/article/details/83029573中有错。
此外,注意哈,只存在 left SEMI JOIN,不存在SEMI JOIN 和 right SEMI JOIN。
hive> SELECT table1.student_no, table1.student_name FROM table1 SEMI JOIN table2 on (table1.student_no=table2.student_no);
FAILED: SemanticException [Error 10009]: Line 1:79 Invalid table alias 'table1'
此外,注意需要以下几项:
1、left semi join 的限制是, JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行。
hive> SELECT * FROM table1 LEFT SEMI JOIN table2 on ( table1.student_no =table2.student_no) where table2.student_no>3;
FAILED: SemanticException [Error 10004]: Line 1:92 Invalid table alias or column reference 'table2': (possible column names are: student_no, student_name)
对右表的过滤条件只能写在on子句中:
hive> SELECT * FROM table1 LEFT SEMI JOIN table2 on ( table1.student_no =table2.student_no and table2.student_no>3);

2、left semi join 是只传递表的 join key 给 map 阶段,因此left semi join 中最后 select 的结果只许出现左表的那些列(参见SQL1和SQL2区别)。
3、因为 left semi join 是 in(keySet) 的关系,遇到右表重复记录,左表会跳过,而 join 则会一直遍历。这就导致右表有重复值得情况下 left semi join 只产生一条,join 会产生多条,也会导致 left semi join 的性能更高。
参考:https://blog.csdn.net/happyrocking/article/details/79885071 ,(ps.其中给的最后一个例子是错误的,semi join不应该包含右表的列)
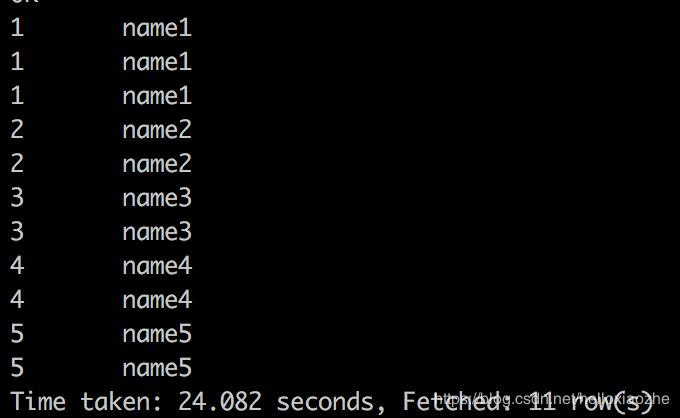
测试三、测试内连接Inner join等价于join,在两张表进行连接查询时,只保留两张表中完全匹配的结果,不存在 inner outer join

select * from table1 inner join table2 on table1.student_no=table2.student_no;
select * from table1 join table2 on table1.student_no=table2.student_no;
测试四:left (outer) join ,在两张表进行连接查询时,会返回左表所有的行,即使在右表中没有匹配的记录。
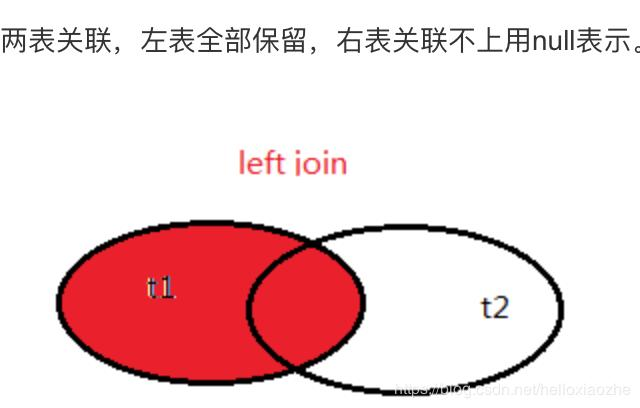
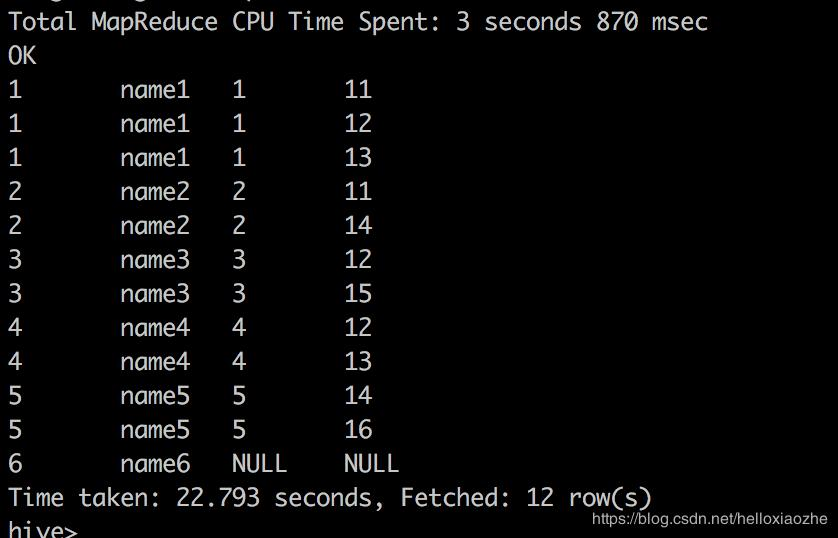
select * from table1 left join table2 on(table1.student_no=table2.student_no);
我用的HIVE版本是hive-2.1.1,是支持直接的left join写法;
测试五:左表独有

SELECT a.key, a.value FROM a LEFT OUTER JOIN b ON (a.key = b.key) WHERE b.key <> NULL;
select * from table1 left outer join table2 on table1.student_no=table2.student_no where table2.student_no is not null;
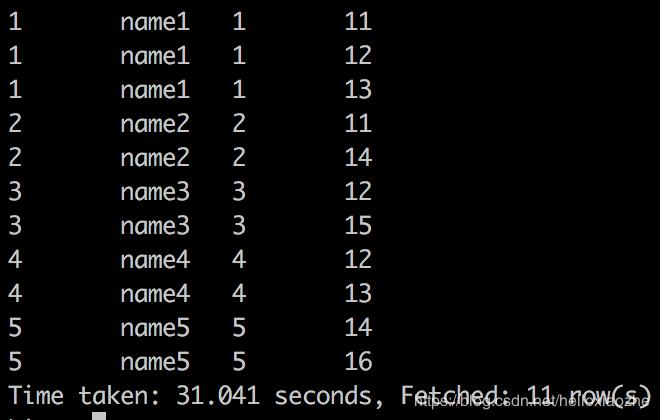
测试六:left (outer) join 在两张表进行连接查询时,会返回右表所有的行,即使在左表中没有匹配的记录。
select * from table1 left outer join table2 on(table1.student_no=table2.student_no);
select * from table1 left join table2 on(table1.student_no=table2.student_no);

可以看到left outer join左边表的数据都列出来了,如果右边表没有对应的列,则写成了NULL值。
同时注意到,如果左边的主键在右边找到了N条,那么结果也是会叉乘得到N条的,比如这里主键为1的显示了右边的3条
测试七:测试right (outer) join 在两张表进行连接查询时,会返回右表所有的行,即使在左表中没有匹配的记录
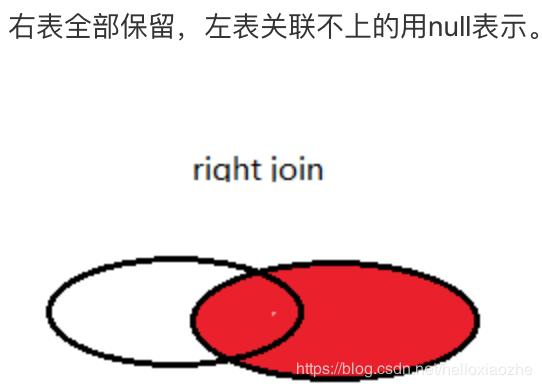
select * from table1 right join table2 on(table1.student_no=table2.student_no);
select * from table1 right outer join table2 on(table1.student_no=table2.student_no);
测试八:右表独有
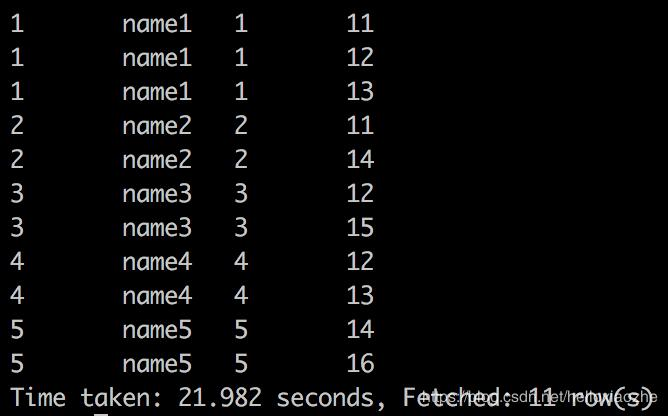
select * from table1 right join table2 on(table1.student_no=table2.student_no) where table1.student_no is not null;
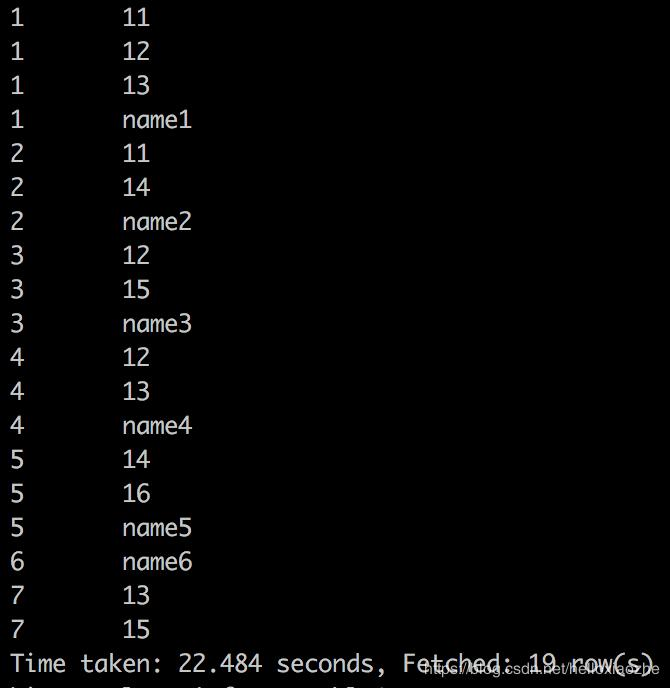
测试九,union 将两个查询结果进行合并一个表,我们可以使用union来达到目的
按列合并两个表,比如第一茬查询结果又6条记录,第二个查询结果又13条记录,那么使用union后的结果将是19条记录。
hive> select student_no tb1_student_no,student_name from table1 union select student_no as tb2_student_no,class_no from table2;

测试十:full join,在两张表进行连接查询时,返回左表和右表中所有没有匹配的行。
查询结果是left join和right join的并集。
select * from table1 full join table2 on(table1.student_no=table2.student_no);

测试:自己全连接自己,使用别名后,也是进行查询:
select * from table1 a full join table1 b on(a.student_no=b.student_no);

如果full join不加on过滤条件,计算结果也是笛卡尔积:
select * from table1 a full join table2 b ;
测试十一:并集去去交集
hive> select * from table1 left outer join table2 on table1.student_no=table2.student_no where table2.student_no is null;

hive> select * from table1 RIGHT outer join table2 on table1.student_no=table2.student_no where table1.student_no is null;

hive> select * from table1 left outer join table2 on table1.student_no=table2.student_no where table2.student_no is null
> UNION
> select * from table1 RIGHT outer join table2 on table1.student_no=table2.student_no where table1.student_no is null;

结论:
-
hive在hive-2.1.1版本时支持’left join’的写法;
-
hive的left outer join:如果右边有多行和左边表对应,就每一行都映射输出;如果右边没有行与左边行对应,就输出左边行,右边表字段为NULL;
-
hive的left semi join:相当于SQL的in语句,比如上面测试3的语句相当于“select * from table1 where table1.student_no in (table2.student_no)”,注意,结果中是没有B表的字段的。
纠正:在hive-2.1.1版本运行命令证实以下文章部分有错:http://www.crazyant.net/1470.html
https://blog.csdn.net/lukabruce/article/details/80568796
http://www.w3school.com.cn/sql/sql_join_full.asp
原文地址:https://blog.csdn.net/helloxiaozhe/article/details/87910386