word2vec
word2vec 是Mikolov 在Bengio Neural Network Language Model(NNLM)的基础上构建的一种高效的词向量训练方法。
词向量
词向量(word embedding ) 是词的一种表示,是为了让计算机能够处理的一种表示。 因为目前的计算机只能处理数值, 诸英文,汉字等等它是理解不了的, 最简单地让计算机处理自然语言的方式就是为每个词编号, 每个编号就代表其对应的词, 这就是one-hot编码(或称one-hot前身,因为one-hot 一般以向量形式呈现, 向量维度是词典的词数量, 每个词的one-hot词向量只在编号位置取1,其余维度只取0)。但很明显,one-hot编码是不能表示词与词之间的(隐含)关系的。 基于Markov 性质构建的n-gram模型,随着 n 的增大,词与词之间的关系的表达更清晰,但计算量却呈可怕的指数级增长。除了巨无霸企业,很少有公司或个人用得来。 所以需要一种可以表示词与词之间内在联系的并且获得还相对容易的词向量。
在此方向做出努力的人有很多, 但真正给人留下印象的首推NNLM。
NNLM
Bengio的NNLM如下图所示, 是这样的一种三层网络结构: 第一层是投影层, 即将每个词投影成一个具有固定维度的向量,一个序列的所有词向量都进入下一层, 所有的词向量首尾顺次相接构成一个大的向量, 最后经过一个全连接层再加上softmax 来预测下一个词的词向量(图上的虚线表示第一层的数据与第三层也是连通)。
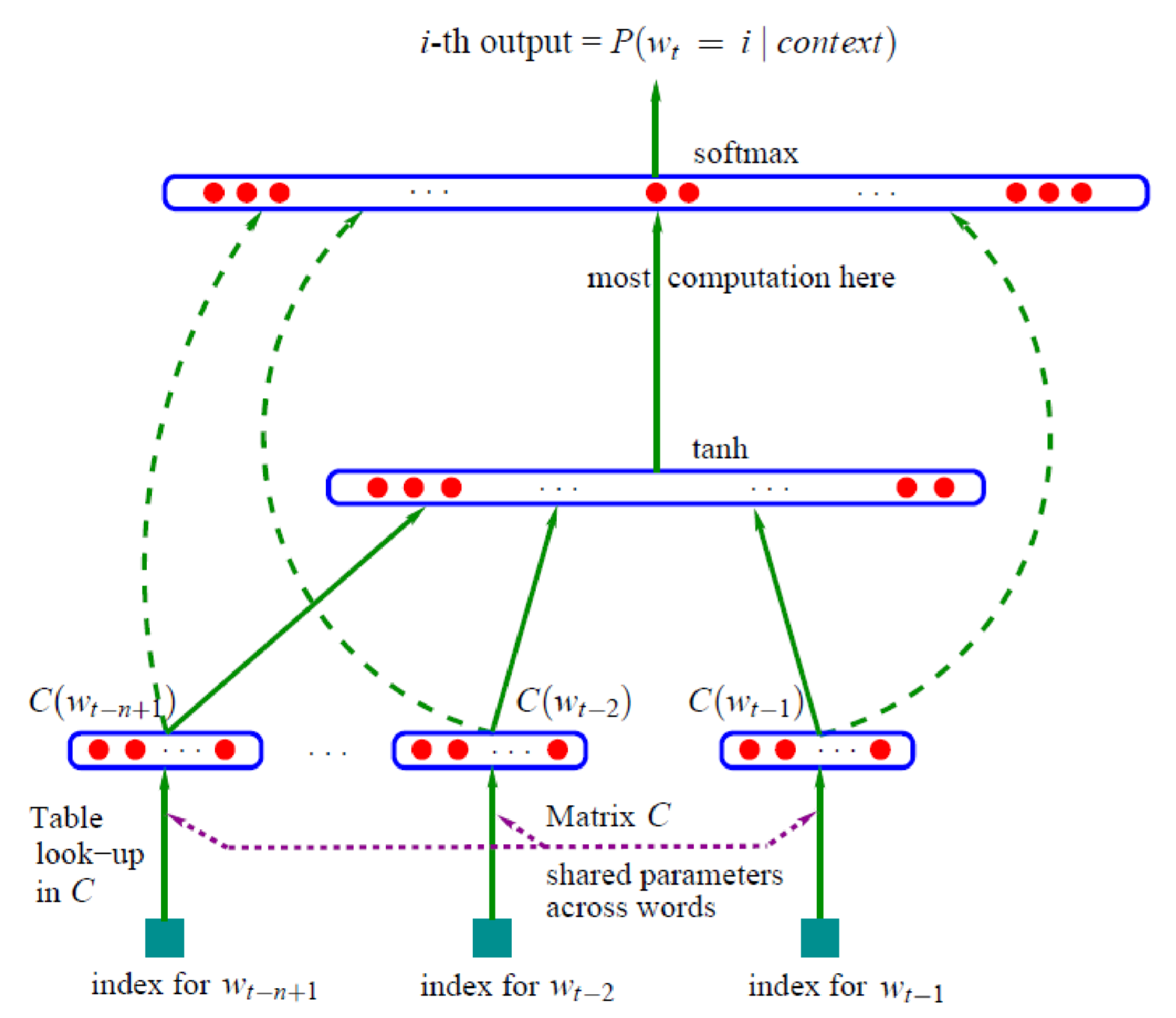
公平的说,这样的结构已经够简单,够高效了。但竟还有优化空间,而且还是更加高效的优化。这就是Mikolov的word2vec.
word2vec
word2vec 是在NNLM的基础上做的大量优化。word2vec的建模方式,有两个版本, 一个是Continuous bag of words (cbow), 另一个是 skip-gram. 实现方式也有两个方式: 一个是 Hierarchical softmax 另一个是Negative Sampling.
word2vec 结构
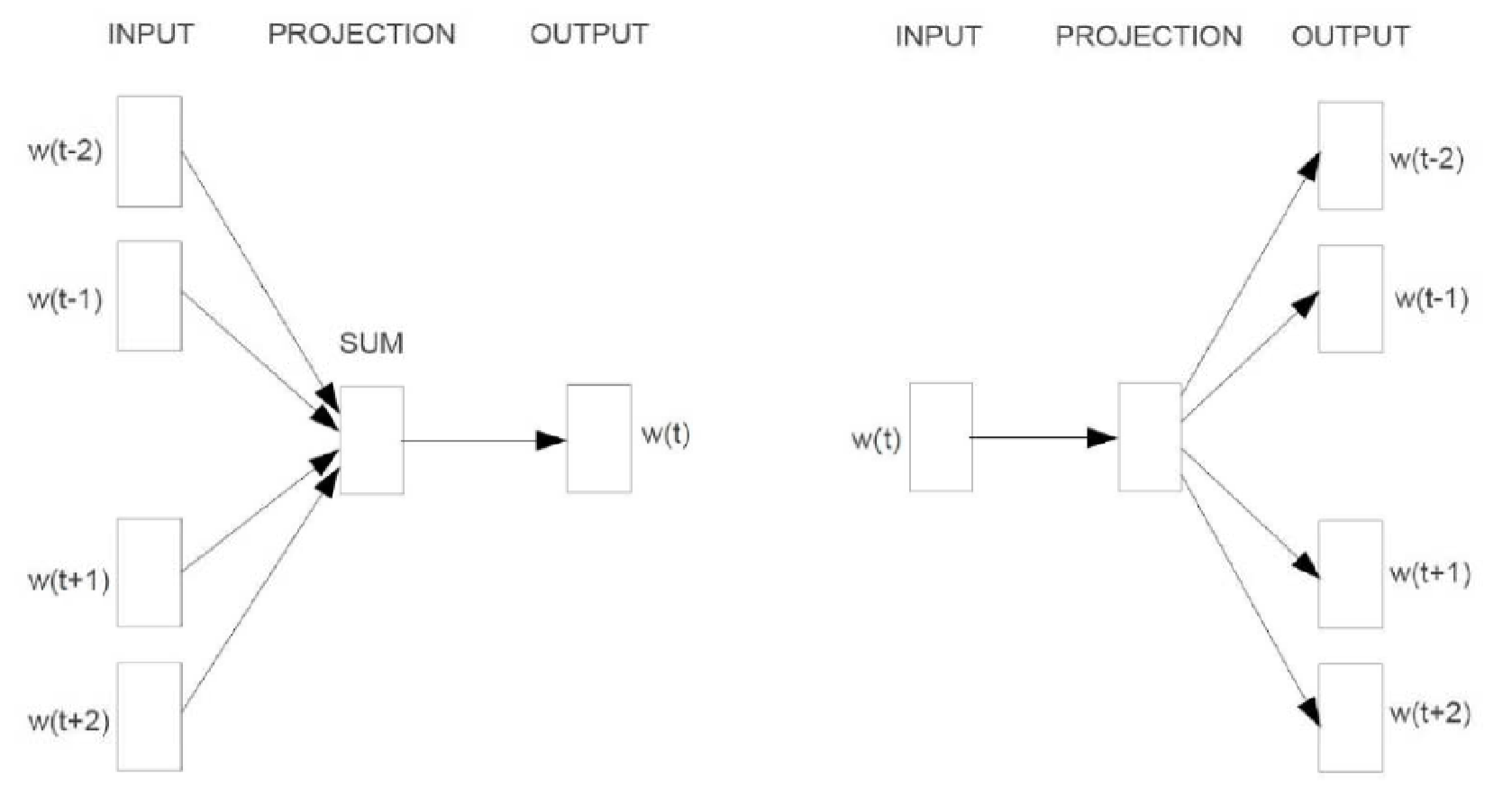
首先来看cbow, 对比NNLM, 可以发现, 其实结构是差不多的,也是三层结构, 只不过, 在第二层中, 序列中的所有词向量不再是首尾顺次相接构成一个大的向量, 而所有向量相加,结果还是一个与每个词向量相同维度的向量。另一个优化即是在预测的方法上, 这个具体在讲实现方式时再说。
然后再看skip-gram, 这个与cbow有点不同, cbow是用(几个)周围词来预测中心词, 而skip-gram则是用中心词来预测周围词。另外,skip-gram严格来说只是两层, 上图其实只为了与cbow的结构类比,skip-gram的第一层与第二层是一样的, 没做任何变化。
实现方式
word2vec的实现方式有两种, 一种是Hierarchical Softmax,另一种是Negative Sampling.
回想word2vec的目的,是找出一种可以表达词与词之间隐含的相互关联的信息的词表示。那如何捕捉这些信息呢? 记得有个人说过:词是没有意义的,除非它在语境之中。 也就是说,我们要找出想要的信息,需要从词及其语境信息中得到。从概率的角度,也就是说我们要建模,使:
或者:
其中(s(a,b)) 表示a,b的某各关系函数。
Hierarchical Softmax
这里用到了一个很重要的概念叫Huffman树,以及Huffman编码。
Huffman 树
在数据结构中, 树是一种很重要的非线性数据结构。二叉树又是其中很重要部分。 下面要介绍的Huffman树是所谓的最优二叉树。
这里带着问题,采用一种反向的方式来了解Huffman树。既然Huffman树是所谓的最优二叉树,那么最优体现在哪里呢? 最优的标准:二叉树的带权路径长度最小。 那什么是带权路径呢?
在树结构中, 从(根)节结点到其子孙结点所经过的分支数量称为路径长度;在树中, 为每个结点赋予某种意义的数值, 称为该结点的权重。带权路径长度为某结点的路径长度与其结点的乘积。对于整棵树来说, 带权路径长度为所有结点的带权路径之和。Huffman为在所有可能的建树方案中,带权路径长度最小的那棵树。
Huffman建树过程,首先是以某种标准为每个数据点分配权值,然后,选出两个权值最小的数据点, 权值相加,构成一个新的(虚拟的)数据点,放回到数据集合中, 重复此组合过程,直到最终数据集只剩下一个点,树即建成。
如果每个数据点是一个词, 并且以每个词出现的频率为权值建树,并且在二叉树中,在左分支标记为1,右分支标记为0,最终每个词都可由0,1 二进制数来编码表示,即为Huffman编码。
HS cbow
从cbow 的结构可知, cbow 是在已知语境的情况下来预测中心词, 则上述优化目标可进一步细化:
在cbow中,(context(w_t)) 所有词的词向量加和:
然后用(x_t) 来预测 (w_t).
在最后一层,以Huffman编码的形式组织所有词。如下图所示:
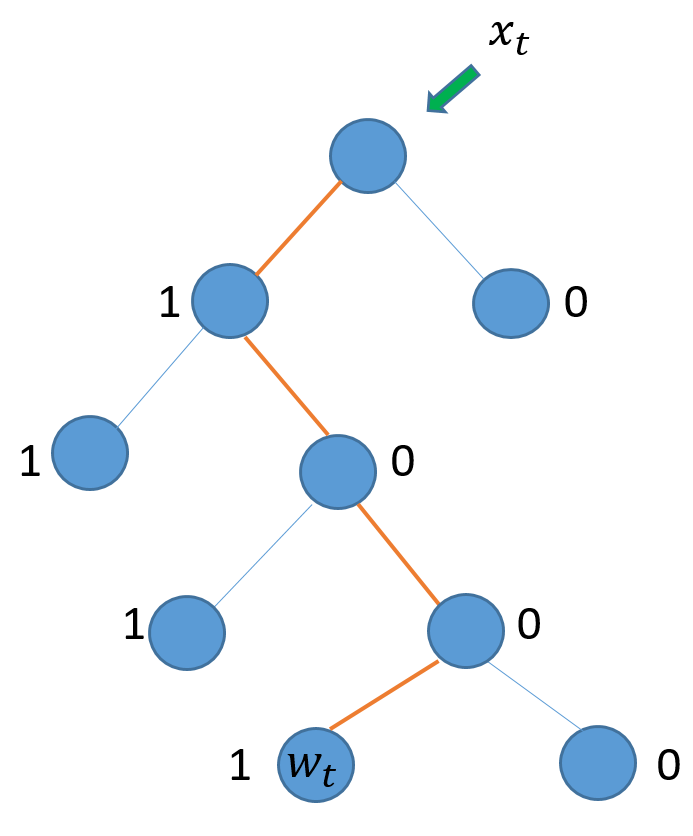
如上图所示, 用(x_t) 来预测(w_t), 要从根结点经过4个分支到达(w_t). 这里因为使用Huffman编码, 原问题的最大化条件概率,转化最大化到达(w_t) 路径的概率.
而且可以发现, 在每个结点向下选择分支时, 无非左右两种, 也即左分支(1), 右分支(0). 完全类似于0,1 分类. 二分类, 最常见, 最简单的,可以说是逻辑回归了.
其中, y表示类别, x是数据, w是权重, b是偏置. 也可知道: (P(y=0|x) = 1 - sigma(x, heta)).
为将上述两个公式合在一起,对于某个结点x:
因此, 最大化路径可考虑成一系列二分类的连续决策过程.如上图的(w_t) 可如下表示:
其中(l_{w_t})表示(w_t)的路径长度, i 表示到达(w_t)路径上面的第 i 个结点(不包括根结点, 但包括(w_t)所在结点).
显然上式是一个典型的最大似然函数. 优化方式就很常规了, 取对数,求偏导(对 (w_t, heta_i)).
HS skip-gram
在最后一层的建树逻辑与cbow是一样的, 唯一的不同还是在于 skip-gram应用中心词来预测周围词(语境):
一样经典的似然函数.
Negative Sampling
另一种更加高效的方式是NCE(Noise Contrastive Estimation). NCE( GUtmann et al.) 被提出,原是为了估计非正则化的概率分布的. Mnih et al 随后把它应用到神经概率语言模型当中. Mikolov把他引入到word2vec之中. NCE 是以二分类的方式将真实分布与负样本分布区分开从而达到求解真实分布的目的, 逻辑其实是与Hierarchical softmax类似, 都是以二分类的形式替代预测问题. Mikolov 把其简化成Negative sampling的方式. Negative sampling即负采样, 负采样如何采呢? 我们知道词的出现频率一般是不一样的,有些几乎总会出现,而且些词在整个语料库内都不见得出现几次.因此,在考查某一个词((w_t))与其语境之间的关系,其负样本应该是那种经常出现却不在(w_t)语境出现的词. 因此从这个逻辑出发, 负采样应该是一个带权采样. 实现方式有多种, Mikolov 选择的是这样的, 上面是基于cbow来介绍的,那么这次就是skip-gram来介绍。
假设对某一词语,负样本集 NEG(w), 可定义如下的示性函数:
其中 ( ilde win NEG(w)cup w) , 可知当 ( ilde w)等于 w 时, 为1, 当 ( ilde w) 属于负样本集时, 为0. 因此,在给定(w, context(w))( context(w)表示w 的语境, 也即其附近词语的集合.) 优化目标为最大化如下:
其中(Neg^{ ilde w}(w))表示在处理( ilde w)时 生成的负样本集, (V( ilde{w})) 表示 w的向量表示. 另外:
上式可改写为:
其中, ( heta) 为一在运算过程中的辅助变量, 我们真正想要的是 ( ilde w). 对于整个语料库C:
对上式取对数, 并将(g(w)) 代入:
接下来即用其对 ( ilde w , heta)求偏导了.
化简, 于是:
也可知:
上面加和符号是因为(mu in Neg^{ ilde w}(w)cup {w}).
有了上面的铺垫,cbow也会很容易:
同理:
代入并写成全语料的形式:
后面的过程如上.