一、EDA(Exploratory Data Analysis)
-
EDA:也就是探索性的分析数据
- 目的:
- 理解每个特征的意义;
- 知道哪些特征是有用的,这些特征哪些是直接可以用的,哪些需要经过变换才能用,为之后的特征工程做准备;
-
1)每个特征的意义、特征的类型:
df.describe() df['Category'].unique()
-
2)看是否存在 missing value(特征数据是否缺失)
df.loc[df.Dates.isnull(),'Dates']
-
3)看每个特征下的数据分布,用 boxplot 或者 hist:
%matplotlib inline import matplotlib.pyplot as plt df.boxplot(column='Fare', by = 'Pclass') plt.hist(df['Fare'], bins = 10, range =(df['Fare'].min(),df['Fare'].max())) plt.title('Fare >distribution') plt.xlabel('Fare') plt.ylabel('Count of Passengers')
- 如果变量是categorical的,想看distribution,则可以:
df.PdDistrict.value_counts().plot(kind='bar', figsize=(8,10))
-
4)看一些 特征之间的联立情况,用 pandas 的 groupby:
temp = pd.crosstab([df.Pclass, df.Sex], df.Survived.astype(bool)) temp.plot(kind='bar', stacked=True, color=['red','blue'], grid=False)
二、Data Preprocessing(数据预处理)
- 目的:将数据处理下,为模型输入做准备;
1)处理 missing value(缺失值)
- 查看数据集中,所有的特征数据有没有缺失;
- 如果 missing value 占总体的比例非常小,那么直接填入平均值或者众数;
- 如果 missing value 所占比例不算小也不算大,那么可以考虑它跟其他特征的关系,如果关系明显,那么直接根据其他特征填入;也可以建立简单的模型,比如线性回归,随机森林等。
- 如果 missing value 所占比例大,那么直接将 miss value 当做一种特殊的情况,另取一个值填入处理;
2)处理 Outlier (异常值)
- 这个就是 EDA 的作用,通过画图,找出异常值
3)categorical feature (类别特征)
-
Categorical 特征常被称为离散特征、分类特征,数据类型通常是 object 类型;
-
机器学习模型通常只能处理数值数据,所以需要对 Categorical 数据转换成 Numeric 特征。
-
categorical feature 有两种分类:
- Ordinal 类型:这种类型的Categorical存在着自然的顺序结构,如果你对Ordinal 类型数据进行排序的话,可以是增序或者降序,比如在学习成绩这个特征中具体的值可能有:
A、B、C、D四个等级,但是根据成绩的优异成绩进行排序的话有A>B>C>D - Nominal 类型:这种是常规的Categorical类型,不能对Nominal类型数据进行排序。比如血型特征可能的值有:
A、B、O、AB,但你不能得出A>B>O>AB的结论。
-
对于Ordinal 和 Nominal 类型数据有不同的方法将它们转换成数字:
- Ordinal 类型数据:使用 LabelEncoder 进行编码处理;
- 例如成绩的
A、B、C、D四个等级进行 LabelEncoder 处理后会映射成1、2、3、4,这样数据间的自然大小关系也会保留下来。
- Nominal 类型数据:使用 OneHotEncoder 进行编码处理;
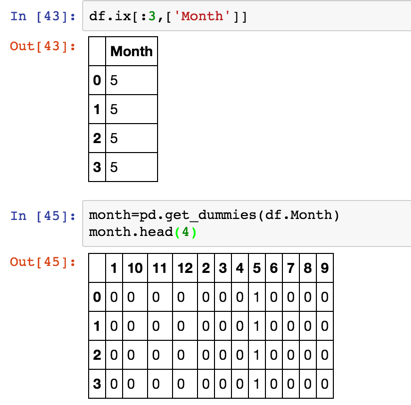
- Pandas 的 get_dummies() 方法,对应每一个虚拟变量,都返回一包含一个新的一列的 DataFrame;
- Use the concat() method to add these dummy columns back to the original DataFrame
- Then drop the original columns entirely using the drop method
4)处理 categorical feature
- 一般就是通过dummy variable的方式解决,也叫one hot encode:
- pandas.get_dummies()
- sklearn 中 preprocessing.OneHotEncoder()
- 例:
将一列的 month 数据展开为了12列,用0、1代表类别
-
另外在处理 categorical feature 有两点值得注意:
- 如果特征中包含大量需要做 dummy variable(虚拟变量)处理的,那么很可能导致得到一个稀疏的dataframe,这时候最好用下PCA做降维处理。
- 如果某个特征有好几万个取值,那么用 dummy variable 就并不现实了,这时候可以用Count-Based Learning.
- 对于类别特征,在模型中加入tf-idf 有好的效果;
- “Leave-one-out” encoding:可以处理类别特征种类过多的问题;
三、Feature Engineering(特征工程)
- 理论上来说,“特征工程” 属于数据预测。
- 特征工程非常重要,可以说最后结果的好坏,大部分就是由特征工程决定的,剩下部分应该是调参和 Ensemble(集成学习) 决定。
- 特征工程的好坏主要是由 domain knowledge 决定的,但是大部分人可能并不具备这种知识,那么只能尽可能多的根据原来 feature 生成新的 feature ,然后让模型选择其中重要的feature。这里就又涉及到 feature selection(特征选择);
- feature selection 的方法:backward、forward selection 等有很多。我个人倾向于用 random forest 的 feature importance,这里有论文介绍了这种方法。
四、Model Selection and Training
1)Model Selection(模型选择)
- 最常用的模型是 Ensemble Model(集成学习),比如 Random Forest、Gradient Boosting。
- Kaggle 上的项目,开始可以用点简单的模型,一方面是可以作为底线 threshold,另一方面也可以在最后作为Ensemble Model。xgboost
2)Model Training(模型训练)
-
训练模型主要就是调参,每种模型都有自己最关键的几个参数,在 sklearn 中
-
GridSearchCV (网格搜索)设置需要比较的几种参数组合;
-
用 cross validation 选出最优秀的参数组合。
-
大概用法:
from sklearn.grid_search import GridSearchCV from pprint import pprint clf=RandomForestClassifier(random_state=seed) parameters = {'n_estimators': [300, 500], 'max_features':[4,5,'auto']} grid_search = GridSearchCV(estimator=clf,param_grid=parameters, cv=10, scoring='accuracy') print("parameters:") pprint(parameters) grid_search.fit(train_x,train_y) print("Best score: %0.3f" % grid_search.best_score_) print("Best parameters set:") best_parameters=grid_search.best_estimator_.get_params() for param_name in sorted(parameters.keys()): print(" %s: %r" % (param_name, best_parameters[param_name]))
五、Model Ensemble(模型集成)
- Model Ensemble 的方法:Pasting、Bagging、Boosting(增强学习)、Stacking(堆叠);其中 Bagging 和 Boosting 都算是 Bootstraping 的应用。Bootstraping 的概念是对样本每次有放回的抽样,抽样K个,一共抽N次。
-
Bagging:每次从总体样本中随机抽取K个样本来训练模型,重复N次,得到N个模型,然后将各个模型结果合并,分类问题投票方式结合,回归则是取平均值,e.g.Random Forest。
-
Boosting:一开始给每个样本取同样的权重,然后迭代训练,每次对训练失败的样本调高其权重。最后对多个模型用加权平均来结合,e.g. GBDT。
-
Bagging 与Boosting 的比较:在深入理解 Bagging 和 Boosting 后发现,bagging 其实是用相同的模型来训练随机抽样的数据,这样的结果是各个模型之间的 bias(偏差) 差不多,variance(方差) 也差不多,通过平均,使得 variance 降低(由算平均方差的公式可知),从而提高 ensemble model 的表现。而 Boosting 其实是一种贪心算法,不断降低bias。
-
Stacking:训练一个模型来组合其他各个模型。
- 首先先训练多个不同的模型;
- 然后再以之前训练的各个模型的输出为输入来训练一个模型,以得到一个最终的输出。
- stacking很像神经网络,通过很多模型的输出,构建中间层,最后用逻辑回归将中间层训练得到最后的结果。
- 例:
def single_model_stacking(clf): skf = list(StratifiedKFold(y, 10)) dataset_blend_train = np.zeros((Xtrain.shape[0],len(set(y.tolist())))) dataset_blend_test = np.zeros((Xtest.shape[0],len(set(y.tolist())))) dataset_blend_test_list=[] loglossList=[] for i, (train, test) in enumerate(skf): dataset_blend_test_j = [] X_train = Xtrain[train] y_train =dummy_y[train] X_val = Xtrain[test] y_val = dummy_y[test] if clf=='NN_fit': fold_pred,pred=NN_fit(X_train, y_train,X_val,y_val) if clf=='xgb_fit': fold_pred,pred=xgb_fit(X_train, y_train,X_val,y_val) if clf=='lr_fit': fold_pred,pred=lr_fit(X_train, y_train,X_val,y_val) print('Fold %d, logloss:%f '%(i,log_loss(y_val,fold_pred))) dataset_blend_train[test, :] = fold_pred dataset_blend_test_list.append( pred ) loglossList.append(log_loss(y_val,fold_pred)) dataset_blend_test = np.mean(dataset_blend_test_list,axis=0) print('average log loss is :',np.mean(log_loss(y_val,fold_pred))) print ("Blending.") clf = LogisticRegression(multi_class='multinomial',solver='lbfgs') clf.fit(dataset_blend_train, np.argmax(dummy_y,axis=1)) pred = clf.predict_proba(dataset_blend_test)
return pred