一、中位数
- 定义/解释:按顺序排列的一组数据中居于中间位置的数,即在这组数据中,有一半的数据比他大,有一半的数据比他小
# 如果观察值有偶数个,通常取最中间的两个数值的平均数作为中位数。

二、方差
- 参考百科:方差
1)定义
方差(variance):是在概率论和统计方差衡量随机变量或一组数据时离散程度的度量
2)应用
1、在统计描述中
- 方差用来计算每一个变量(观察值)与总体均数之间的差异
- 在许多实际问题中,研究方差即偏离程度有着重要意义
- 为避免出现离均差(X -
 )总和为零,离均差平方和受样本含量的影响,统计学采用平均离均差平方和来描述变量的变异程度
)总和为零,离均差平方和受样本含量的影响,统计学采用平均离均差平方和来描述变量的变异程度 - 总体方差计算公式:

 :总体方差
:总体方差 :变量
:变量- :总体均值
 :总体例数
:总体例数
- 实际工作中,总体均数难以得到时,应用样本统计量代替总体参数,经校正后,样本方差计算公式:S2 = ∑(X -
 )2 / (n - 1)
)2 / (n - 1)
- S2:样本方差
- X:变量
- :为样本均值
- n:样本例数。
2、在概率分布中
- 在概率分布中,设X是一个离散型随机变量,若E{[X - E(X)]2}存在,则称E{[X - E(X)]2}为X的方差,记为D(X),Var(X)或DX,其中E(X)是X的期望值,X是变量值,公式中的E是期望值expected value的缩写,意为“变量值与其期望值之差的平方和”的期望值。
- 离散型随机变量方差计算公式:D(X)=E{[X - E(X)]2} = E(X2) - [E(X)]2
三、标准差
# 参考百科:标准差
1)定义
- 标准差(Standard Deviation)又常称均方差,是方差的算术平方根,反映一个数据集的离散程度
2)应用

3)其它
- 简单来说,标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值
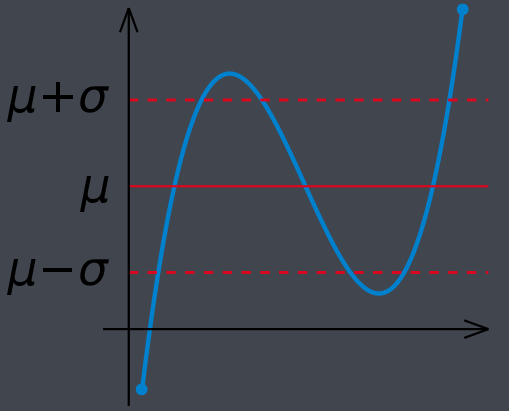
四、均方误差
1)定义
- 均方误差(mean-square error, MSE)是反映估计量与被估计量之间差异程度的一种度量。
2)名词介绍
- 均方误差是评价点估计的最一般的标准,自然,我们希望估计的均方误差越小越好,注意到
- 上式说明,均方误差
 由点估计的方差
由点估计的方差  与偏差
与偏差  的平方两部分组成。
的平方两部分组成。 - 如果
 是 θ 的无偏估计,则
是 θ 的无偏估计,则  ,此时用均方误差评价点估计与用方差是完全一致的,这也说明了用方差考察无偏估计是合理的。
,此时用均方误差评价点估计与用方差是完全一致的,这也说明了用方差考察无偏估计是合理的。 - 当 不是 θ 的无偏估计,就要看其均方误差 ,即不仅看方差大小,还要看其偏差大小,下面的例子说明在均方误差的含义下,有些有偏估计优于无偏估计。
3)一致性最小的均方误差估计
- 定义1:
- 设有样本
 对待估参数 θ,有一个估计类,称
对待估参数 θ,有一个估计类,称  是该类中θ的一致最小均方误差估计,如果对该类估计中另外任意一个θ的估计
是该类中θ的一致最小均方误差估计,如果对该类估计中另外任意一个θ的估计  ,在参数空间
,在参数空间  上都有
上都有 
- 使用情况:
- 一致最小均方误差估计通常是在一个确定的估计类中进行的,一致最小均方误差估计一般是不存在的。
- 既然一致最小均方误差估计一般是不存在的,人们通常就对估计提出一些合理性要求,如无偏性就是一个常见的合理性要求。
- 一致最小方差无偏估计前面曾指出,均方误差 由点估计的方差 与偏差 的平方两部分组成,当 是 θ 的无偏估计时,均方误差就简化为方差,此时一致最小均方误差估计就是一致最小方差无偏估计。
- 定义2 :
- 设 是 θ 的无偏估计,如果对于任意一个θ的无偏估计
 ,在参数空间 上都有
,在参数空间 上都有  则称 是 θ 的一致最小方差无偏估计,简记为UMVUE。
则称 是 θ 的一致最小方差无偏估计,简记为UMVUE。
五、估计量
1)定义
- 用来估计总体未知参数用的统计量。
2)举例
- 设(X1,……,Xn)为来自总体X的样本,(X1,……,Xn)为相应的样本值,θ是总体分布的未知参数,θ∈Θ。
- Θ 表示 θ 的取值范围,称 Θ 为参数空间。尽管 θ 是未知的,但它的参数空间 Θ 是事先知道的,为了估计未知参数θ,我们构造一个统计量 h(X1,……,Xn),然后用 h(X1,……,Xn) 的值 h(X1,……,Xn) 来估计θ的真值,称h(X1,……,Xn)为θ的估计量。
- 个人理解:
- 目的:估计总体数据集 X 的分布情况,即 θ;
- 方法:从总体数据集 X 中抽取一组样本 h,根据 h 的分布以及 θ 的取值范围 Θ 来估计总体数据集 X 的分布情况 θ。
3)误差
- 对于一个给定样本x,估计量
 的"误差"定义为
的"误差"定义为  其中
其中  是待估参数。
是待估参数。
- 注意误差e不仅取决于估计量(估计公式或过程),还取决于样本。
4)均方误差
- 估计量
 的均方误差被定义为误差的平方的期望值,即为:
的均方误差被定义为误差的平方的期望值,即为: 。
。
- 它用来显示估计值的集合与被估计单个参数的平均差异。试想下面的类比:假设“参数”是靶子的靶心,“估计量”是向靶子射箭的过程,而每一支箭则是“估计值”(样本)。那么,高均方误差就意味着每一支箭离靶心的平均距离较大,低均方误差则意味着每一支箭离靶心的平均距离较小。箭支可能集聚,也可能不。比如说,即使所有箭支都射中了同一个点,同时却严重偏离了靶子,均方误差相对来说依然很大。然而要注意的是,如果均方误差相对较小,箭支则更有可能集聚(而不是离散)。
5)一致性
- 一致估计量序列是一列随着序号(通常是样本容量)无限增大时依概率收敛于被估量的估计量序列。换句话说,增加样本容量增大了估计量接近总体参数的概率。
- 在数学上,一个估计量序列 {tn;n≥ 0} 是参数 θ 的一致估计量当且仅当对于所有 ϵ > 0,不管多小,我们都有
 ;
;
- 就如,一个人不断地抛硬币,随着次数的增多,任何一面出现的概率(机率)就会趋于0.5。那么这个0.5就是这个抛硬币事件中任何一面出现概率的一致估计量,或者说一致估计值。
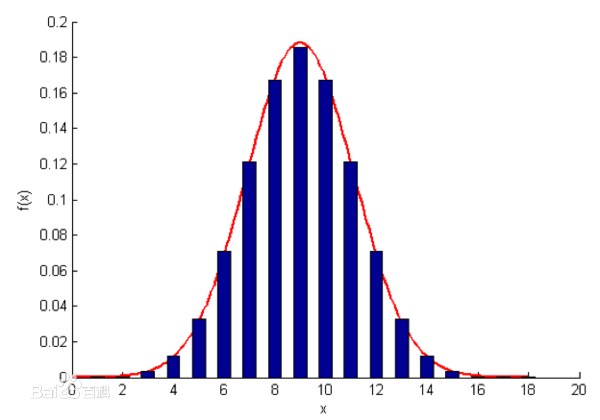
六、高斯函数、正态分布
1)定义
- 格式:

2)积分
- 任意高斯函数的积分是:

- 另一种形式是:

- 其中 f 必须是严格积分的积分收敛;
3)正态分布
- 公式:

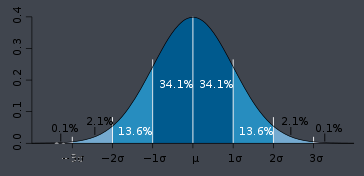
- 正态分布(Normal distribution),也称“常态分布”,又名高斯分布(Gaussian distribution)
- 高斯函数是正态分布的密度函数,根据中心极限定理它是复杂总和的有限概率分布;
- 若随机变量X服从一个数学期望为μ、方差为σ^2的正态分布,记为N(μ,σ^2)。其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布。
-
定理:
-
由于一般的正态总体其图像不一定关于y轴对称,对于任一正态总体,其取值小于x的概率。只要会用它求正态总体在某个特定区间的概率即可。为了便于描述和应用,常将正态变量作数据转换。将一般正态分布转化成标准正态分布。若
 服从标准正态分布,通过查标准正态分布表就可以直接计算出原正态分布的概率值。故该变换被称为标准化变换。(标准正态分布表:标准正态分布表中列出了标准正态曲线下从-∞到X(当前值)范围内的面积比例。)
服从标准正态分布,通过查标准正态分布表就可以直接计算出原正态分布的概率值。故该变换被称为标准化变换。(标准正态分布表:标准正态分布表中列出了标准正态曲线下从-∞到X(当前值)范围内的面积比例。) -
定义:
- 多维正态分布参见“二维正态分布”。
-
标准正态分布:当
 时,正态分布就成为标准正态分布
时,正态分布就成为标准正态分布