一、关于数据
- 数据集:数据的整体,喂给算法的数据,一般为表格形式;
- 数据集中,每一行数据为一个样本,每行中的各列为每一个特征;
- 数据集中,除最后一列,每一列表达样本的一个特征;
- 最后一列,称为标记(label):对本行样本进行分类;
- 如本行是猫的特征,在最后一列要标记此样本为猫的样本;若该样本特征是狗的,则在最后一列标记为狗的样本;
- 数据集首行为特征,对应下列各行为特征值,每一行特征值为一个特征向量;
- 特征空间(feature space):数据集中的样本用空间中的一个点表示,数据集中有几种特征,就使用几维度的空间,此空间为特征空间。
- 通过对数据集的学习,算法系统再接受新的特征后可以自己判断该特征对应的事物;
- 事物的特征数据;
- 一般大写字母表示矩阵,小写字母表示向量;
- 向量分为行向量(1 X n)和列向量(n X 1),数学上一般将向量表示为列向量;
- 将数据集表示在坐标系中,有几种特征,就用几种维度的空间,一个样本就是特征空间中的一个点;
- 分类任务本质就是在特征空间切分;
- 图像识别中,将每一个像素做为一个特征;
二、机械学习的基本任务
#一般监督学习领域解决的主要为分类问题和回归问题;
1)分类
- 二分类任务:判断一个对象,是或不是、有或没有、是什么;
- 多分类任务:判定多个对象,做出选择;
- 多标签分类:一般多用于图像识别;
- 一些算法只支持完成二分类任务;
- 多分类任务可以转换成二分类任务;
- 有一些算法天然可以完成多分类任务;
2)回归
特点:结果是一个连续数字的值,而不是一个类别;如预测房价
应用:预测房价、分析市场、预测学生成绩等;
#有一些算法只能解决回归问题,有一些算法只能解决分类问题,有些算法既能解决回归问题又能解决分类任务;
#一些回归任务和为分类任务可以互相转换;
3)机械学习思路
- 输入大量的学习资料给机械学习算法,经过训练后,将该算法系统演变为一个模型;
- 输入新的样本给模型,模型可以自己做出判断或分析,得到结果;
- 输出结果一般分为两类:类别(分类问题)、数值(回归问题);
4)模型
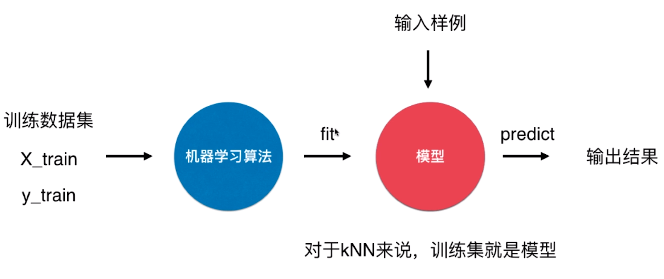
- 训练数据集 = X_train + y_train
- X_train:特征的具体值;
- y_train:样本的标签,或者称样本的类别;
- fit:拟合,算法训练出模型的过程;
- predict:预测,给模型输入样例后得到输出结果的过程;
三、根据算法本身进行分类
#监督学习、非监督学习、半监督学习、增强学习
1)监督学习
特点:给算法的训练数据带有“标记”或者“答案”;
思路:已经对给机器的数据进行了正确答案的划分,这种划分就是监督的信息;
2)非监督学习
特点:对没有“标记”的数据进行分类 - 聚类分析;
实例:电商平台的客户模型,根据客户对不同商品的浏览、选购等情况,对客户进行分类;
意义:对数据进行降维出来,特征提取、特征压缩(主要使用PCA);
特征压缩(主要用PCA算法降维):在尽量少的损失信息的情况下,将高维的特征向量压缩为低维特征向量;
特征压缩的作用:
A、提升了算法的运行效率,但不影响最终结果;
B、方便数据可视化;(因为人一般很难理解3维以上的维度)
C、异常检测:在样本空间中,排除明显不能表达样本的整体特性的样本点;
3)半监督学习
特点:一部分数据有“标记”或者“答案”,另一部分数据没有;(一般实践中更长见)
思路:通常都先使用无监督学习手段对数据做处理,之后使用监督学习手段做模型的训练和预测;
4)增强学习
特点:不断的根据反馈改进并优化算法系统;
思路:根据环境的情况采取行动,算法系统会得到相应的反馈(奖赏机制/惩罚机制),并根据反馈改进自己的行为模式,然后根据改进的算法系统对新的环境再次采取行动,并再次得到反馈;以此循环下去;
#AlphaGo就是采用增强学习算法系统、无人驾驶、机器人
#增强学习比较前沿,目前监督学习和非监督学习是基础;
四、机械学习的其它分类
#在线学习和批量学习(离线学习)、参数学习和非参数学习
1)批量学习(Batch Learning)
#也叫离线学习
特点:算法系统经过数据集训练后得到模型,直接被用于实践中,在实践中再次得到其它新的数据时,该算法系统不再对自身做调整和优化;
优点:简单,算法系统投入实践中后不用再考虑优化改进问题;
缺点:不能适应环境的变化;(一般机械学习算法系统所面临的问题,会随着时间不短变化,如垃圾邮件分类问题,垃圾邮件的定义随时间而定义不同);
解决方案:对算法系统定时重新批量学习,重新训练模型,来适应环境变化;
方案弊端:每次重新批量学习,运算量巨大;而且不适用变化很快的环境中(如股市变化很快,无法对股市走向预测);
2)在线学习(Online Learning)
特点:算法系统经过训练后得到模型,被用于实践后,在实践中得到其它新的数据时,将该数据的结果反馈给算法系统,经过算法系统学习后,重新对模型进行改进优化;
优点:及时反映新的环境变化;
问题:新的数据带来不好的变化(这些不好的数据也可能是竞争对手故意抛出的数据),导致改进后的模型对正常数据判断的正确率下降了;
解决方案:增加一个非监督学习算法,加强对数据进行监控;
其它:在线学习,也适用于数据量巨大,一次性批量无法全部学习,可以将数据分批在线喂给模型;
3)参数学习
特点:一旦学到了参数,就不再需要原有的数据集;
思路:已知特征和输出的关系(如线性关系:f(x) = a*x + b),将数据集喂给算法系统,得到关系中参数的值;
#一般特征和输出的关系,是统计上的假设;
#先预测特征和输出结果是统计学中的模型关系,之后的任务就是通过数据集学习并得到该统计模型中的参数;
4)非参数学习
特点:不对模型进行过多统计上的假设或对问题建模,而是通过喂给算法数据集,得到特征和输出结果的关系模型;
# 非参数学习不等于没有参数;
五、机械学习的其它思考
1)数据为王?
- 机械学习算法主要处理不确定世界中真实的问题,所给我们的答案也是不确定的概率性的具有统计意义的答案;
- 传统经典算法不同,通常有固定的标准的答案;
- 机械学习的答案可靠吗?我们可以多大程度的相信这些答案?机械学习学习到的本质是什么?
- 2001年微软研究:不同质量的算法,随着喂给数据量的增加,算法的准确度也增加,并最后趋于100%;因此有数据即算法的说法(只要喂给算法的数据足够多,数据的质量足够好),接着就有了大数据的时代;?
- 数据很重要,因为数据驱动算法的准确度;
- 目前机械学习应用中:收集更多的数据、提高数据质量、提高数据的代表性、研究更重要的特征(即特征工程),是工作的主要内容;
2)算法为王?
- AlphaGo Zero:Starting from scratch(从零开始),前期人类并没有给AlphaGo Zero输入任何数据,所有的数据都是靠算法产生的(对于有些问题,即使没有数据,算法也能为我们生产数据),因此产生“算法为王”的说法;
- AlphaGo Zero事件说明,算法本身很重要,再好的数据也需要优质高效的算法做辅助,才能最大程度的发挥数据本身的作用;但目前短时间内,机械学习领域中的任务,大部分是数据驱动的;
3)“奥卡姆的剃刀”定理
- 机械学习中有很多算法,但解决的问题种类差不多,怎么选择算法来解决问题?选择原则:奥卡姆的剃刀,简单的就是好的,也就是对一个问题不要有过多的假设,不要有过多的复杂化;
- 机械学习领域中,什么叫“简单”?
- 机械学习中,处理的是不确定世界中的真实的问题,没有变准答案;
4)“没有免费的午餐”定理
- “没有免费的午餐定理”:可以严格地用数学的方式推导出任意两个机械学习的算法,他们的期望性能(一个算法可以解决不同的问题,但应用在不同问题时的效果不一样,整体来说算法对解决问题的平均能力差不多)是相同的;根据这个理论可以得出,没有哪个算法比另一个算法好,相当于说算法是等价的,但针对具体问题时不同算法适用程度不同;目前机械学习主要解决具体的特定问题,因此需要学习多种算法,并在解决问题时选择更合适的算法,但整体而言,没有一个算法比另一个算法好;
- “没有免费的午餐定理”也告诉我们:1)脱离具体问题,谈哪个算法更好是没有意义的;2)在们面对一个具体问题的时候,尝试使用多种算法进行对比试验,是必要的;
5)其它
- 面对不确定的世界,怎么看待使用机械学习进行预测的结果?到底是机械学习算法本身起到了决定性的作用,使得我们得到了准确的预测结果?还是说只是一个巧合,机械学习算法本身并没有起到太大的作用?