open()函数来打开一个文件, 获取文件句柄(文件句柄是一个可迭代的对象). 然后通过文件句柄就可以进行各种各样的操作了了. 根据打开方式的不同能够执行的操作也会有相应的差异
因为文件句柄是一个可迭代的对象,可以通过for循环读取数据,并且它每次读取的时候都是读取一行内容
f = open('gg','r',encoding = 'utf-8') for i in f:#读取文件中的内容。 一行一行的读取。 每次读取的内容交给前面的变量 print(i.strip)
上面每次循环相当于直接使用f.readline()
f.writelines() 直接将一个列表的内容传递写进去,注意的是写入的东西都必须是字符串,如果不是字符串的话就会报错
f.writable() 判断文件是否是可写的
f.read() 一次性直接读取全部,如果里面写入了数据则按照数字读取文本的个数eg:f.read(2) 表示读取文件的多少个字符
f.readlines() 整行读取为一个元素,并将每行作为一个元素添加到列表中(说明返回值是一个列表)一次性全部读取
f.readline() 只是读取一行
f.readable() 判断文件否是可读的
在打开一个文件的时候如果文件是以绝对路径的方式进行打开的时候,由于含有’’eg: C:UsersviviDesktoppython编程练习答案 由于‘’在编程中有自己的意义,如果想要在编程中实现的话可以通过转义字符’’
eg: ‘C:\Users\vivi\Desktop\python编程\练习答案’
或者是使用时 r ‘C:UsersviviDesktoppython编程练习答案’‘r’使含有特殊意义的字符都失效
mode :模式
r 只读 (文件必须是已经存在)
w 写入,如果文件已经存在则将原来的文件覆盖,再写入(文件不存在的话可以自动创建)
a 打开一个文件用于追加写入 (文件不存在的话可以自动创建)与w模式一样,不过写入的时候,写入到文件的最后
文本的复制 f = open('gg','r',encoding ='utf-8') y = open('dd','w',encoding = 'utf-8') for i in f: y.write(i) f.close() y.close()
b - bytes 读取和写入的是字节 , 用来操作非文本文件(图片, 音频, 视频)
# rb, wb, ab(作用与上面的一致,不同的是这是用来操作非文本文件的)
复制一张图片的操作,基本与上面的文本复制一样
gg = open(r'C:UsersviviDesktop非.jpg','rb') f = open(r'C:UsersviviDesktop en.jpg','wb') for i in gg: f.write(i) gg.close() f.close()
r+ w+ a+ + 表示的是功能的扩展,# r+ 读写, w+ 写读, a+ 追加写读, r+b, w+b, a+b(功能一样,不过是用于非文本文件的操作)
r+ 模式下写入的内容按照指针的位置进行编写,默认的指针位置是在文件的开头,如果使用read进行读取的时候,指针的位置会发生变化
在读取之后才进行写入是没有问题的,因为读取完全部内容之后,不论你读取多少内容。再次写入的时候都是在末尾,但是如果先写入在读取的话,就会将文本的内容进行覆盖
w+
f = open("person", mode="w+", encoding="utf-8") # 先清空。 然后再操作
f.write("你好。 我叫肿瘤君")
content = f.read() # 写入东西之后。 光标在末尾。 读取不到内容的
print(content)
f.close()
a+, 不论指针(光标)在何处 写入的时候都是在末尾
对于光标的 操作:
f.seek(3) # 以字节为单位
# info = f.read(3) # 读取三个字符
打开一个文件,不从开头开始读(定位)
seek(offset,from)
一个偏移量 一个方向
from 中 0 表示文件开头
1 表示当前位置
2 表示文件末尾
偏移量 选定的位置向右偏移指定的字节
eg:
# 把光标移动到文件的开头: seek(0)
# 把光标移动到末尾: seek(0, 2)
gg = f.tell() 可以知道当前已经读取到那个字节
f.seek(0,2) 回到文本的末尾
pan.seek(0,gg) 回到先前的光标的位置
truncate() 截断文件. 慎用 无法恢复
f.seek(5) # 光标移动到5
f.truncate() # 默认从开头截取到光标位置
f.truncate(3) # 从头截取到3字节,之后光标后面的 所有内容全部删除
python 不支持直接进行文件修改操作
#文件内容的修改
import os with open('gg',mode = 'r',encoding = 'utf-8') as f ,open('ff',mode = 'w',encoding =' utf-8') as f2: for i in f: f2.write(i.replace('中','卫')) os.remove('gg') os.rename('ff','gg')
将文本中的内容提取出来并添加到字典中
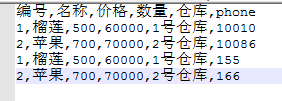
f = open("水果.data", mode="r", encoding="utf-8") titles = f.readline().strip() # 读取第一行 id,name,price,num t_list = titles.split(",") # 【id,name,price,num】 lst = [] for line in f: # "1,苹果,500,60000" {id:1,name:liulian, num:xx, price:xxx} dic = {} ll = line.strip().split(",") for i in range(len(t_list)): dic[t_list[i]] = ll[i] lst.append(dic) f.close() print(lst)
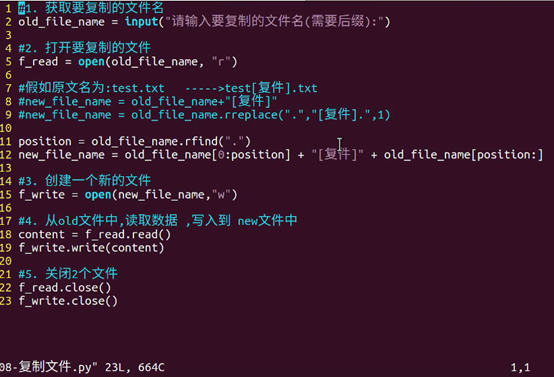
为了解决大文件的问题