单向链表相对数组来说已经有很多优点了,但是,它还有一个最大的弊端,那就是在某种程度上和深度优先遍历有通性------一条路走到黑,从不回头!这种特性在进行数据操作时,会大大浪费时间,鉴于此,出现了双向链表的概念。
顾名思义,双向链表就是具备两个方向的指向,无非就是每个结点成了两个指针。其实,对于数据结构,我们要先形象的理解其具体“形状”与出现它的意义,如果你彻底理解了单向链表,会用自己的思维从0开始写一个链表集成类出来,别说双向链表,就是三向链表,五向链表,你也可以自己写出来,只不过,介于实际需求更多向的链表用树,图来解决更形象方便点,所以说,学不是学代码,而是学思维,固有一句话:程序等于数据结构加算法,而不是等于C + C++ +JAVA + C# + .NET + PYTHON + ASP.NET + VB +......,
1.创建双链表。
我们来看看双向链表的创建:
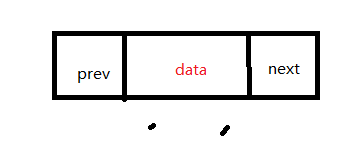
有两个指针域分别指向前一个结点和后一个结点,还有一部分用来保存结点数据,初始化结点时需要将两个指针都指向空
eg:
Node* node = (Node*)malloc(sizeof(Node));
node->prev = NULL;
node->next = NULL;
1.增加结点。
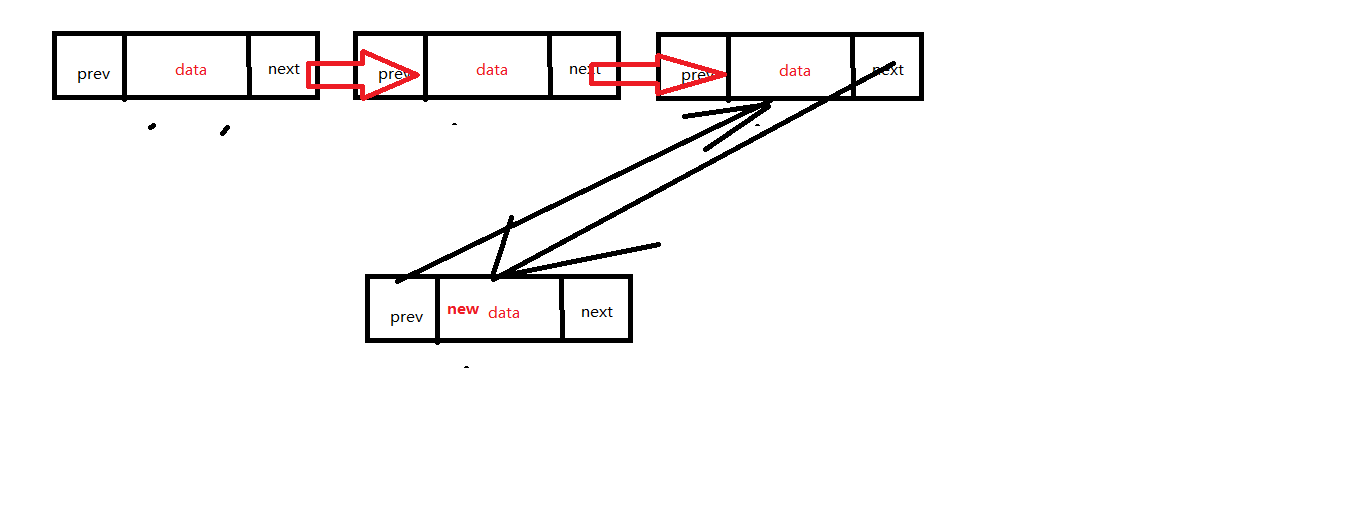
增加结点时,需要将最后一个结点的next指针指向新结点,然后将新结点的prev指向最后一个结点
3.删除结点。
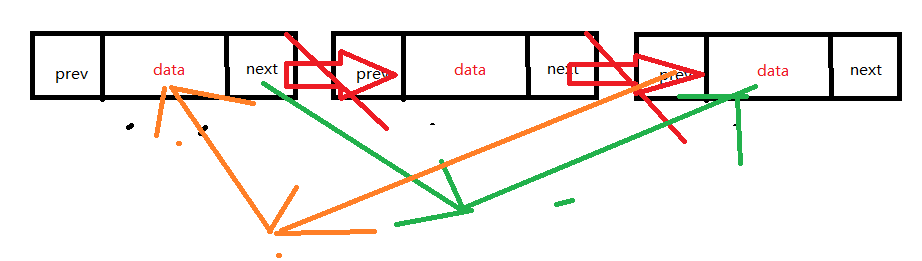
删除结点时需要将待删除结点的前一个结点的next指向待删除结点的后一个结点,然后,把后者的prev指针指向前者:
4.插入结点。
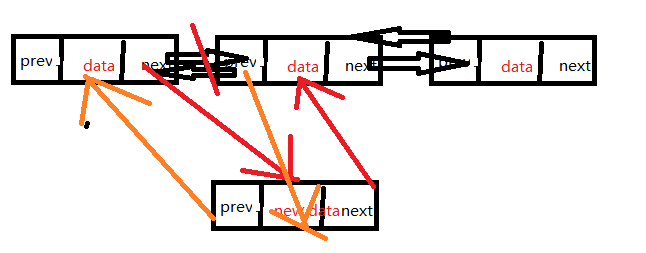
插入结点就是将新结点的前一个结点的next指针指向指向新结点,然后把新结点的next指针指向前一个结点原来后面的那个结点,然后把后面的结点的prev指针指向新结点,把新结点的Prev指针指向前一个结点。
下面是双向链表的Demo:
#include<iostream>
#include<malloc.h>
#include<windows.h>
using namespace std;
struct Node{
char sex;
int data;
struct Node* prev;
struct Node* next;
};
Node* newNode();
void Add(Node* head); //增
void Del(Node* head); //删
void Show(Node* head); //查
void Update(Node* head); //改
void Menu();
int main(int argc,char** argv){
Node* head = newNode();
int select;
while(true){
Menu();
cin >> select;
switch(select){
case 1:
Add(head);
break;
case 2:
Del(head);
break;
case 3:
Show(head);
break;
case 4:
Update(head);
break;
case 5:
exit(1);
break;
default:
cout << "输入无效,请重新输入" << endl;
break;
}
}
return 0;
}
Node* newNode(){ //把初始化结点的步骤封装成一个函数,方便后续操作
Node* node = NULL;
node = (Node*)malloc(sizeof(Node));
node->prev = NULL;
node->next = NULL;
node->sex = '0';
node->data = 0;
return node;
}
void Add(Node* head){
system("cls");
Node* temp = newNode();
cout << "请输入您的性别代号" << endl;
cin >> temp->sex;
cout << "请输入您的学号" << endl;
cin >> temp->data;
while(head->next != NULL){ //移动到链表的最后一个元素,然后添加新结点
head = head->next;
}
head->next = temp;
temp->prev = head;
system("pause");
}
void Menu(){
system("cls");
cout << "1.增加数据" << endl;
cout << "2.删除数据" << endl;
cout << "3.查看数据" << endl;
cout << "4.修改数据" << endl;
cout << "5.退出" << endl;
cout << endl << "请选择功能代码进行下一步操作" << endl;
}
void Del(Node* head){
system("cls");
Node* node = newNode();
int sign;
cout << "请输入学生的学号" << endl;
cin >> sign;
while(head->next != NULL){
if(head->next->data == sign){ //移动到待删除结点的前一个结点,如果该结点是最后一个结点则直接使待删除结点的前一个结点的next指针指向NULL,如果不是最后一个结点,则使待删除结点的前一个结点的next指向待删除结点的后一个结点,并使后一个结点的prev指向前一个结点,需要注意的是,删除前需要新建一个指针指向待删除结点,等到把待删除结点从链表中“脱离”后,释放该结点,避免野指针和对储存空间的浪费。
node->next = head->next;
if(head->next->next == NULL){
head->next = NULL;
}else{
head->next = head->next->next;
head->next->next->prev = head;
}
free(node->next);
free(node);
}else{
head = head->next;
}
}
}
void Show(Node* head){
system("cls");
while(head->next != NULL){
cout << head->sex << "," << head->data << "<===" << head->next->sex << "," << head->next->data << "===>";
if(head->next->next == NULL){
cout << "NULL" << endl;
}else{
cout << head->next->next->sex << "," << head->next->next->data << endl;
}
head = head->next;
}
system("pause");
}
void Update(Node* head){
system("cls");
Node* node = newNode();
Node* temp = newNode();
cout << "请输入学生的学号" << endl;
cin >> node->data;
cout << "请输入学生的性别" << endl;
cin >> node->sex;
while(head->next != NULL){
if(head->next->data == node->data){
temp->next = head->next;
if(head->next->next == NULL){
head->next = node;
node->prev = head;
break;
}else{
node->next = head->next->next;
head->next->next->prev = node;
head->next = node;
node->prev = head;
break;
}
free(temp->next);
free(temp);
}else{
head = head->next;
}
}
}