>>> str2 = '192.168.1.1'
>>> re.match('(d{1,3}).(d{1,3}).(d{1,3}).(d{1,3})', str2).groups()
('192', '168', '1', '1')
>>> re.match('(d{1,3}).(d{1,3}).(d{1,3}).(d{1,3})', str2)
<re.Match object; span=(0, 11), match='192.168.1.1'>
>>> IP=re.match('(d{1,3}).(d{1,3}).(d{1,3}).(d{1,3})', str2)
>>> IP
<re.Match object; span=(0, 11), match='192.168.1.1'>
>>> IP.groups()
('192', '168', '1', '1')
用正则表达式来划分IP地址:
需要提前import re
re.match('(d{1,3}).(d{1,3}).(d{1,3}).(d{1,3})', str2).groups()
re.match(‘xxx’, str2)用正则表达式匹配后面的字符串
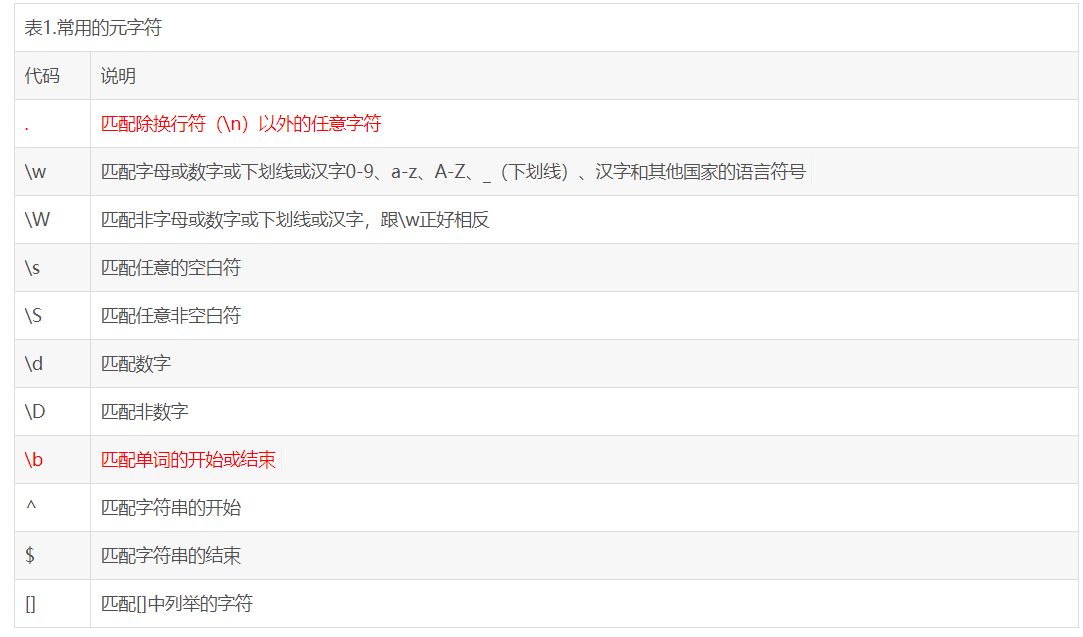
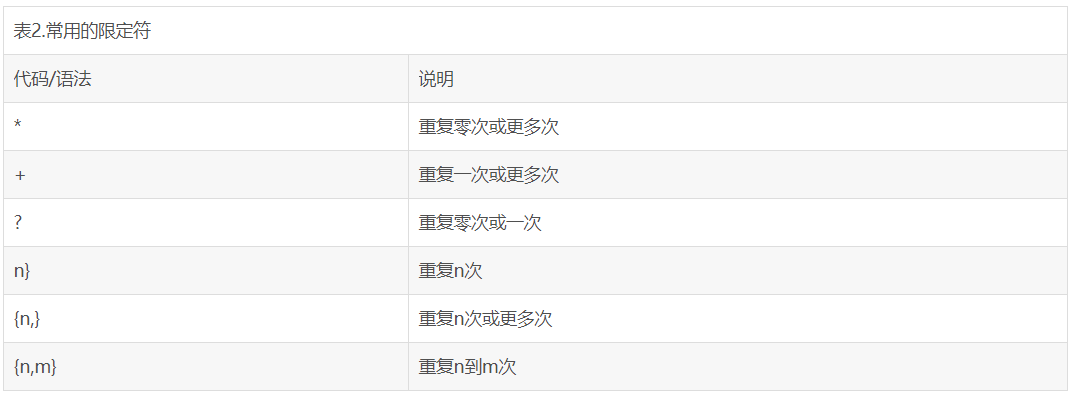
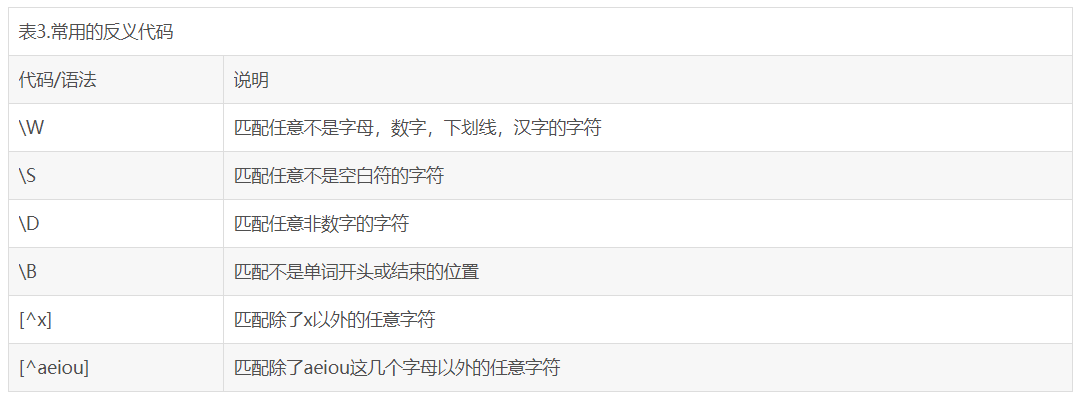
()里是正则表达式,(d{1,3})表示任意数字出现1到3次
groups()表示生成元组
>>> str4='hello my world!'
>>> str4
'hello my world!'
>>> str4.split()
['hello', 'my', 'world!']
>>> re.match('hellos+([a-z]+)s+([a-z]+)s*!', str4).groups()
('my', 'world')
>>> re.match('([a-z]+)s+([a-z]+)s+([a-z]+)s*!', str4).groups()
('hello', 'my', 'world')
s表示出现空格,+表示出现至少一次,*表示可能出现,0次或多次
因为使用了(),才会匹配出某一个值,即括号才是能匹配出的结果:
>>> re.match('(hell[a-z]+)s([a-z]+)s([a-z]+)s*!',str4).groups()
('hello', 'my', 'world')
>>> re.match('hell[a-z]+s([a-z]+)s([a-z]+)s*!',str4).groups()
('my', 'world')
############################################
正则表达式groupdict():
>>> str1='...aaa/bbb/ccc]'
>>> str1
'...aaa/bbb/ccc]'
>>> re.search('(?P<part1>w*)/(?P<part2>w*)',str1).groups()
('aaa', 'bbb')
>>> re.search('(?P<part1>w*)/(?P<part2>w*)',str1).groupdict()
{'part1': 'aaa', 'part2': 'bbb'}
>>> re.search('(?P<part1>w*)/(?P<part2>w*)',str1).groupdict()
这里属于固定写法,<part1>是字典的key,后面的w*匹配任意数量的字符,不包括...
下面是使用正则表达式匹配ASA接口地址和状态:
>>> test='GigabitEthernet1/2 172.31.105.22 YES CONFIG up up '
>>> re.match('(w.*d)s+(d{1,3}.d{1,3}.d{1,3}.d{1,3})s+YESs+CONFIGs+(w+)s+(w+)s*' ,test).groups()
('GigabitEthernet1/2', '172.31.105.22', 'up', 'up')
>>> a=re.match('(w.*d)s+(d{1,3}.d{1,3}.d{1,3}.d{1,3})s+YESs+CONFIGs+(w+)s+(w+)s*' ,test).groups()
>>> a
('GigabitEthernet1/2', '172.31.105.22', 'up', 'up')
>>> a[0]
'GigabitEthernet1/2'
>>> a[1]
'172.31.105.22'
>>> a[2]
'up'
>>> a[3]
'up'