具体步骤:
1、进入宝马官网,查找经销商查询界面
http://www.bmw.com.cn/cn/zh/general/dealer_locator/content/dealer_locator.html
2、使用火狐浏览(需要安装Firebug和HttpFox)
找到json数据存储位置:https://secure.bmw.com.cn/cn/_common/_js/dealer_locator/dealer_locator.json
3、查看json数据以后,json中包含省份,城市,店面类型,经销商信息,并且发现里面的经销商数据中包含地域的编号信息,所以决定制作省份字典、城市字典、类型字典,并且和经销商中数据进行比对输出。
4、得到省份信息主要代码:
1 def get_province_dict(self): 2 province_dict={} 3 #创建省份信息字典 4 json_data = urllib2.urlopen(self.index_url).read() 5 #读取json页面 6 jsons = json_data.split(';') 7 #将几组json数据分开 8 json_province = jsons[0][jsons[0].index('=')+1:-1] 9 #jsons[0]是省份信息 10 json_province = json_province+']' 11 #将得到的字符串整理成正常的json数据格式 12 provinces = json.loads(json_province) 13 #读取json数据 14 for province in provinces: 15 province_dict[province.get('id')] = province.get('nz') 16 #得到ID和省份名称存入相应的字典中 17 return province_dict
5、得到城市信息的方法遇上面一样
1 def get_city_dict(self): 2 city_dict={} 3 json_data = urllib2.urlopen(self.index_url).read() #读取json数据 4 #print json_data 5 jsons = json_data.split(';') 6 #print jsons[1]# 城市信息 7 json_city = jsons[1][jsons[1].index('=')+1:-1] 8 json_city = json_city+']' 9 citys = json.loads(json_city) 10 #print provinces 11 for city in citys: 12 #print province.get('nz') 13 city_dict[city.get('id')] = city.get('nz') 14 15 for key in city_dict:#测试字典 16 print key 17 print city_dict[key] 18 return city_dict
6、获得店面类型的信息也类似
def get_type_dict(self): type_dict={} json_data = urllib2.urlopen(self.index_url).read() #读取json数据 #print json_data jsons = json_data.split(';') #print jsons[2]# 店面类型信息 json_type = jsons[2][jsons[2].index('=')+1:-1] json_type = json_type+']' types = json.loads(json_type) #print provinces for typea in types: #print province.get('nz') type_dict[typea.get('id')] = typea.get('nz') return type_dict
7、由于json中店面的类型是通过ID与类型ID进行匹配的,所以需要将类型的名称与店面id进行匹配制成字典
1 def get_dealer_type_dict(self): 2 dealer_type_dict={} 3 types = self.get_type_dict() 4 #调用之前的类型方法,用于后面的匹配 5 json_data = urllib2.urlopen(self.index_url).read() #读取json数据 6 #print json_data 7 jsons = json_data.split(';') 8 #print jsons[4]# 店面与类型关系信息 9 json__delaer_type = jsons[4][jsons[4].index('=')+1:-1] 10 json__delaer_type = json__delaer_type+']' 11 delaer_types = json.loads(json__delaer_type) 12 #print provinces 13 for delaer_type in delaer_types:#有用31-34编号的信息不是所需信息搜易使用if剔除 14 if delaer_type.get('tp')==31: 15 continue 16 if delaer_type.get('tp')==32: 17 continue 18 if delaer_type.get('tp')==33: 19 continue 20 if delaer_type.get('tp')==34: 21 continue 22 print delaer_type.get('tp') 23 dealer_type_dict[delaer_type.get('br')] = types[delaer_type.get('tp')] 24 return dealer_type_dict
8、处理经销商数据方法
1 def get_dealer_info(self): 2 province_dict = self.get_province_dict() 3 city_dict = self.get_city_dict() 4 dealer_type_dict = self.get_dealer_type_dict() 5 6 json_data = urllib2.urlopen(self.index_url).read() 7 8 jsons = json_data.split(';') 9 #print jsons[3]#经销商信息 10 json_dealer = jsons[3][jsons[3].index('=')+1:-1] 11 #由于此处的json数据过大,致使json.loads()发生异常 12 #所以选择拼凑成列表的格式进行生成 13 json_dealer = json_dealer.replace('[','') 14 json_dealer = json_dealer.replace(']','') 15 json_dealer = json_dealer.replace('},','}},') 16 json_dealer = json_dealer.split('},') 17 #以上为拼凑过程 18 dealers = list(json_dealer) 19 #将字符串转变成列表 20 dealer_info_list = [] 21 for dealer in dealers: 22 l={} 23 dealer = json.loads(dealer) 24 #字符减少可以使用json.loads()进行处理,得到字典 25 print dealer.get('nz') 26 l[Constant.PROVINCE] = province_dict[dealer.get('pv')] 27 #用经销商数据中的省份ID匹配省份字典中的ID,得到中文的省份名称 28 l[Constant.CITY] = city_dict[dealer.get('ct')] 29 l[Constant.TYPE] = dealer_type_dict[dealer.get('id')] 30 l[Constant.NAME] = dealer.get('nz') 31 l[Constant.ADDRESS] = dealer.get('az') 32 l[Constant.TEL] = dealer.get('tel') 33 l[Constant.EMAIL] = dealer.get('em') 34 l[Constant.WEBSHOP] = dealer.get('ws') 35 l[Constant.SINA] = dealer.get('wb') 36 l[Constant.LENDER] = dealer.get('fnz') 37 l[Constant.LENDERTEL] = dealer.get('ft') 38 l[Constant.AFTERSALE] = dealer.get('flt') 39 l[Constant.FAX] = dealer.get('fax') 40 l[Constant.POSTCODE] = dealer.get('zp') 41 dealer_info_list.append(l) 42 self.saver.add(dealer_info_list)#提交保存 43 self.saver.commit()
还有部分代码是用于将数据存入excel中的,就不贴出来了
最终结果是
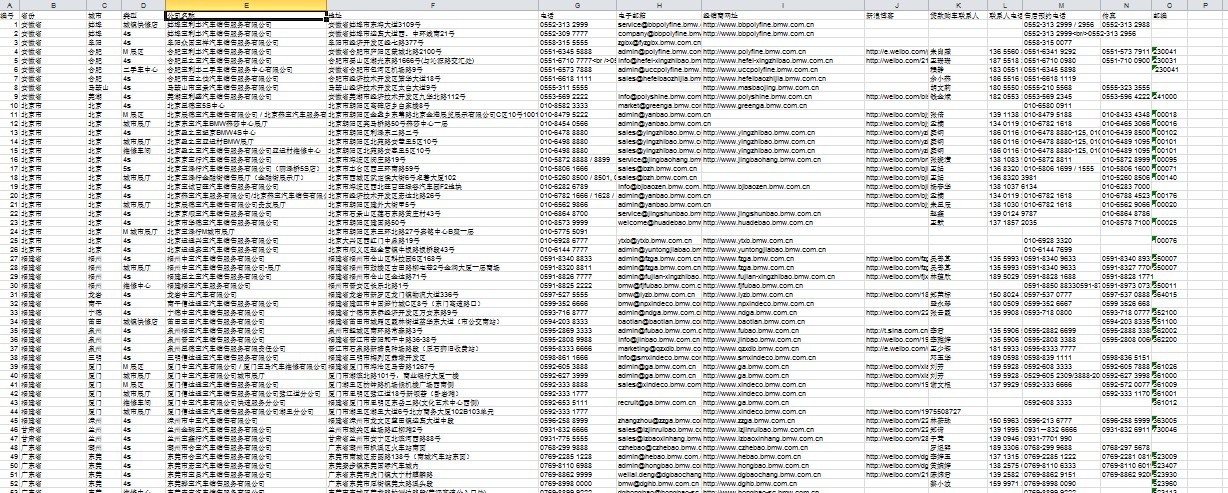
我是爬虫新手,学python也就一个月,还是有高人指点的,代码很冗余,希望对新手有帮助,更希望高手提出意见,我加紧改进学习!!!!!!