一、openpyxl模块介绍
1、openpyxl是读写Excel的python库,是一个比较综合的工具,能够同时读取和修改Excel文档
2、openpyxl中有三个不同层次的类,每一个类都有各自的属性和方法:
- Workbook是一个excel工作表
- Worksheet是工作表中的表单,如图
-
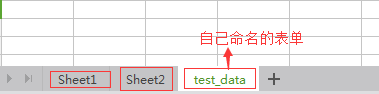
- Cell就是表单中的一个格
3、操作Excel的一般场景:
- 打开或者创建一个Excel需要创建一个Workbook对象
- 获取一个表则需要先创建一个Workbook对象,然后使用该对象的方法来得到一个Worksheet对象
4、Workbook对象
- 一个Workbook对象代表一个Excel文档,因此在操作Excel之前,都应该先创建一个Workbook对象。
- 对于一个已经存在的Excel文档,可以使用openpyxl模块的load_workbook函数进行读取,该函数包涵多个参数,但只有filename参数为必传参数。filename 是一个文件名,也可以是一个打开的文件对象。
二、安装openpyxl模块
在cmd命令行下输入命令:pip install openpyxl
三、代码实现(在Pycharm中编写代码)
1、本地新建一个Excel表test_case.xlsx
2、复制test_case.xlsx到Pycharm:
3、用python操作excel
导入load_workbook库
from openpyxl import load_workbook
第一步:打开excel
workbook1=load_workbook('test_case.xlsx')
第二步:定位表单(test_data)
sheet=workbook1['test_data']
第三步:操作excel的test_data表单
1、定位单元格(cell),根据行列读取测试数据
data=sheet.cell(3,2).value
print(data)
特殊说明:

定位C2单元格数据{'mobilephone':'13502288210','pwd':'123456'}
data=sheet.cell(2,3).value
查看C2单元格数据类型为,但实际为dict类型
print(type(data)) 输出str
将str类型转化为他原来的类型dict:eval(data)
print(type(eval(data))) 输出dict
综上可得:
- excel 存储的数据,数字还是数字:int—>int、 float—>float 、其他类型—>str
- 使用eval(数据) 将str类型转换为他原来的类型
2、定位单元格(cell),根据行列值,更改原有的数据、写入新的测试数据,
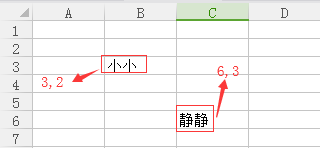
sheet.cell(3,2).value='妮妮' #更改已经存在的测试数据
sheet.cell(6,3).value='小小' #在空的单元格写入新的测试值
workbook1.save('test_case.xlsx') #保存修改
3、统计行和列(参考上图)
max_row=sheet.max_row
max_cow = sheet.max_column
print('最大的行值:',max_row) #输出6
print('最大的列值:',max_cow) #输出7
从excel中读取测试用例:
#读取每一条测试用用例分别保存到字典中,然后再将所有用例保存到列表中,如[{用例1},{用例2},{用例3}]
def read_case():
workbook1=load_workbook('test_case.xlsx')
sheet=workbook1['test_data']
max_row=sheet.max_row
test_case=[]
for row in range(2,max_row+1):
sub_data={}
sub_data['case_id']=sheet.cell(row,1).value
sub_data['title']=sheet.cell(row,2).value
sub_data['data']=sheet.cell(row,3).value
sub_data['method']=sheet.cell(row,4).value
sub_data['expected']=sheet.cell(row,5).value
test_case.append(sub_data)
print("读取到的所有测试用例:",test_case)
read_case()

1 #读取每一条测试用用例分别保存到字典中,然后再将所有用例保存到列表中,如[{用例1},{用例2},{用例3}]
2 def read_case():
3 workbook1=load_workbook('test_case.xlsx')
4 sheet=workbook1['test_data']
5 max_row=sheet.max_row
6 test_case=[]
7 for row in range(2,max_row+1):
8 sub_data={}
9 sub_data['case_id']=sheet.cell(row,1).value
10 sub_data['title']=sheet.cell(row,2).value
11 sub_data['data']=sheet.cell(row,3).value
12 sub_data['method']=sheet.cell(row,4).value
13 sub_data['expected']=sheet.cell(row,5).value
14 test_case.append(sub_data)
15 print("读取到的所有测试用例:",test_case)
16
17 read_case()