0,基础概念
Collection:统计大小、插入或删除数据、清空、是否包含某条数据,等等。而Collection就是对这些常用操作进行提取,只是其很全面、很通用。size(),isEmpty(),contains(),add(),remove,clear(),hashCode()
AbstractCollection:在Collection得基础上,在泛型上实现了一些方法,add抛出一个异常,addAll获得一个迭代器遍历添加,clear获得一个迭代器遍历删除,contains获得一个迭代器遍历查找,tostring集合内容
list:和collection相比,比较针对线性表来设计add,addAll,sort,get,set,indexOf,lastIndexOf,listIterator()返回一个先前遍历得迭代器
AbstractList<e>:iterator方法返回了一个内部类Itr对象,合理的处理hasNext,next,remove方法,还有个ListItr实现了ListIterator接口,equals和hashcode的实现,所以在定义数据元素时,也应该复写这两个方法,以保证程序的正确运行
queue:继承自,collection,有offer(add),poll(remove),peek(element)操作,返回null不抛出异常
AbstractQueue:在泛型上实现了add,remove,element
Deque<e>:双向队列,添加了一些对应的,offerFist,addFirst,removeLast,pollLast,getLast,peekLast,定义了栈,push,和pop
map接口:put,get,size,remove,clear,希望我们完成hashcode和equal
AbstractMap:在泛型上帮我们实现上面方法
String的方法:
hashcode:hash = 31 * hash+ a[i]
equals:对比是不是同一个引用,对比是不是长度相同,再一个个字母对比
compareTo:实现了Comparable<t>的int compareTo(T t)方法,先对比长度,小的作为循环数,比较到a和b某个字母不相同,返回他们两个相减
数组
- 创建一个数组,必须声明其长度,以在内存中寻找合适的一段连续存储单元。这也意味着数组的大小是固定的,我们无法动态调整其大小。
- 想要获取数组中第i个元素,其时间复杂度是 O(1),因为可以根据其地址直接找到它。同理修改也是。
- 因为地址连续,想要在数组中插入一个元素是复杂的,因为从插入位置起,后边的所有元素都需要向后移动一位。同理删除也是,只是移动方向为向前。并且,当数组存满时,就无法继续插入了。
链表
- 链表的每个元素都分为数据域和指针域,前者是实际存储的数据,后者则指向下一个元素的地址。和数组相比,每个元素需要占用的内存更大了。
- 增加与删除一个元素更方便了,因为没有对内存地址的限制,我们只需要在对应节点合理处理下指针域的值,就可以把一个元素插入链表或者从链表删除。
- 链表对查询表现也一般,需要遍历,时间复杂度为O(n)。
红黑树:红黑树和AVL树的思想是类似的,都是在插入过程中对二叉排序树进行调整,从而提升性能,它的增删改查均可以在O(lg n)内完成。红黑树的插入与删除和AVL树类似,也是每插入一个结点,都检查是否破坏了树的结构,然后进行调整。红黑树每个结点插入时默认都为红色,这样做可以降低黑高,也可以减少调整的次数。
队列
- 调整操作:
initialCapacity |= (initialCapacity >>> 1); initialCapacity |= (initialCapacity >>> 2); initialCapacity |= (initialCapacity >>> 4); initialCapacity |= (initialCapacity >>> 8); initialCapacity |= (initialCapacity >>> 16); initialCapacity++;
一个数的二进制位00001101,那他最接近的二次幂就是00010000,具体操作就是通过上面的跳跃填充1的或操作,把后面的0补上1,即00001111加上1后变00010000
ps:二级制:0 -》1-》127-》-128-》-127-》-1-》-0即-128
00000000 -》00000001 -》 0111111111 -》 10000000 -》 10000001 -》11111111 -》10000000
循环队列操作: elements[head = (head - 1) & (elements.length - 1)] = e;参考上面二进制,正数就是取模,到了负数的时候,比如-1,此时他是用补码表示,无视符号位和前面高位的数,用地位数做取模,效果从最大的数开始
队列为满:head==tail。这时候就不得不扩容了,因为head==tail是判断是否为空的条件。直接扩容两倍
1,Iterator
Iterable<E>:collection继承的接口,代表要实现Iterator<T> iterator()接口,有了获得一个迭代器的能力,获得一个迭代器
Iterator<E>:Iterator是foreach遍历的主体,有核心next,remove,hasNext
ArrayList和linkedList:ListItr增加了hasPrevious,previous,nextIndex,add,set
2,ArrayList
- 默认是10,添加第一个的时候创建,添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为
oldCapacity + (oldCapacity >> 1),也就是旧容量的 1.5 倍。 - 扩容操作需要调用
Arrays.copyOf()把原数组整个复制到新数组中,这个操作代价很高,因此最好在创建 ArrayList 对象时就指定大概的容量大小,减少扩容操作的次数。 - 需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上,该操作的时间复杂度为 O(N),可以看出 ArrayList 删除元素的代价是非常高的。
-
ArrayList 基于数组实现,并且具有动态扩容特性,因此保存元素的数组不一定都会被使用,那么就没必要全部进行序列化。ArrayList 实现了 writeObject() 和 readObject() 来控制只序列化数组中有元素填充那部分内容。
-
Fail-Fast,modCount 用来记录 ArrayList 结构发生变化的次数。结构发生变化是指添加或者删除至少一个元素的所有操作,或者是调整内部数组的大小,仅仅只是设置元素的值不算结构发生变化。
在进行序列化或者迭代等操作时,需要比较操作前后 modCount 是否改变,如果改变了需要抛出 ConcurrentModificationException。
3,linked list
LinkedList既继承了List,又继承了Deque,那它必然有一堆add、remove、addFirst、addLast等方法。- Node<e>作为她的内部类,有e数据域,和上下节点的指针
- 因为链表没有长度方面的问题,所以也不会涉及到扩容等问题,其构造函数也十分简洁了。
- 果要遍历,也最好使用
foreach,也就是Iterator提供的方式。 - 非常适合大量数据的插入与删除,但其对处于中间位置的元素,无论是增删还是改查都需要折半遍历,这在数据量大时会十分影响性能。
4,treemap
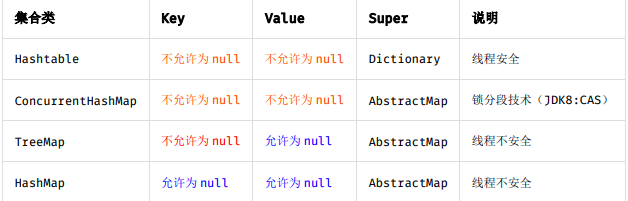
- TreeMap是根据key进行排序的,它的排序和定位需要依赖比较器或覆写Comparable接口,也因此不需要key覆写hashCode方法和equals方法,就可以排除掉重复的key,而HashMap的key则需要通过覆写hashCode方法和equals方法来确保没有重复的key。
- TreeMap的查询、插入、删除效率均没有HashMap高,一般只有要对key排序时才使用TreeMap。
- TreeMap的key不能为null,而HashMap的key可以为null。
- TreeMap不是同步的。如果多个线程同时访问一个映射,并且其中至少一个线程从结构上修改了该映射,则其必须 外部同步。
5,hashmap
- 初始化没有设定值的时候,初始值1《《4=16,最大为1《《30,负载因为0.75的时候扩容,也是2次幂
- 链表长度为8的时候变成红黑树,小于6的时候变回链表
- 设计的key对象一定要实现
hashCode方法 - 如果可以预先估计数量级,可以指定initial capacity,以减少rehash的过程。
- JDK 1.8 使用了 CAS 操作来支持更高的并发度,在 CAS 操作失败时使用内置锁 synchronized。
6,Collections.sort(list,comparator<User>),默认升序
Collections.sort(userList, new Comparator<User>() { public int compare(User u1, User u2) { return new Double(u1.getSalary()).compareTo(new Double(u2.getSalary())); //升序 // return new Double(u2.getSalary()).compareTo(new Double(u2.getSalary())); //降序 } });
int[] intArray = new int[] { 4, 1, 3, -23 }; Arrays.sort(intArray);
7,集合和数组转化,list转数组
List<String> list = new ArrayList<String> (); list.add("str1"); list.add("str2"); int size = list.size(); String[] arr = (String[]) list.toArray(new String[size]);
数组转集合
List<String> list = new ArrayList<>(arr.length); Collections.addAll(list, arr);
8,数组和list复制,数组复制
System.arraycopy(a1, 1, a2, 3, 3); System.out.println(Arrays.toString(a1)); // [1, 2, 3, 4, 5] System.out.println(Arrays.toString(a2)); // [0, 0, 0, 2, 3, 4, 0, 0, 0, 0]
list复制
浅拷贝
1、遍历循环复制
List<Person> destList=new ArrayList<Person>(srcList.size()); for(Person p : srcList){ destList.add(p); }
2、使用List实现类的构造方法
List<Person> destList=new ArrayList<Person>(srcList);
3、使用list.addAll()方法
List<Person> destList=new ArrayList<Person>(); destList.addAll(srcList);
4、使用System.arraycopy()方法
Person[] srcPersons=srcList.toArray(new Person[0]); Person[] destPersons=new Person[srcPersons.length]; System.arraycopy(srcPersons, 0, destPersons, 0, srcPersons.length);