一. 整体介绍
soft lockup:检测调度异常, 一般是驱动禁止调度或者阻塞比如while(1), 导致无法调度其他线程, 需要注意的是, 应用程序while(1)不会影响其调度, 只要有更高的优先级出现会在时间滴答(10ms)选中并切换进程,
但如果是在驱动也即内核态, 即使有更高优先级时间滴答也不会切换线程, 只不过会在该线程的task->flag 标志 NEED_RESHEDULE, 驱动还是会继续跑, 简单说就是驱动while(1) 会独占CPU 资源, CPU
不会调度到其他进程/线程, 只有中断产生, 才能打断其运行, soft lockup就是根据这个, 利用中断在中断上下文来判断调度是否阻塞了, 怎么判断呢? 先创建一个内核线程(watchdog/xx), 且优先级设置
实时优先级FIFO, 功能就只是更新时间戳到某个变量(watchdog_touch_ts), 这个线程在每一轮调度总能排在前面, 设想如果连这个线程都得不到运行, 其它普通线程还有机会么? 中断函数watchdog_timer_fn()
会读取这个变量watchdog_touch_ts存的时间戳和此时的时间戳, 如果相差大于20秒, 则说明进程阻塞了, 否则说明进程运行正常, 这里需要强调的是超过20秒是指线程watchdog/xx在20秒内都没得到运行,
可能是一个驱动while(1)导致的, 也可能是多个进程阻塞几秒钟, 全部累计时间超过20秒, 甚至是中断函数做一下耗时处理导致的, 总而言之是系统其他总时间超过20秒, 导致watchdog/xx没有被调度, 但这
并不一定意味是有问题的, 假设如果你的系统很变态, 跑了100个应用/进程, 每个耗时0.3秒, 那系统轮询所有的进程需要的时间就是30秒, 产生这个异常很正常, 所以要改这个默认20秒异常时间值, 可以
改成40秒就行了, 当然绝大部分系统20秒足够让进程轮了好多次了~~~
hard lockup:检测中断异常, 一般是禁止中断或者某个中断函数内阻塞, 导致其他中断无法得到执行, 中断是系统得以运行的重要保证, 出了异常系统不可控! 那问题来了, soft lockup是靠中断来监控进程, 那谁来监控
中断那就是NMI(不可屏蔽中断)或者FIQ(一般系统的中断都是IRQ), 总之就是要比普通中断更高级! 具体做法也简单, 上面已经有个中断监控函数watchdog_timer_fn() 里面除了判断soft lockup, 还会对
hrtimer_interrupts进行加1, 不可屏蔽中断watchdog_overflow_callback()会对上一次存放的值hrtimer_interrupts_saved和这次hrtimer_interrupts对比, 如果一样说明定时器中断函数watchdog_timer_fn()没有得到运行!
二. 源码分析
1. soft lockup:
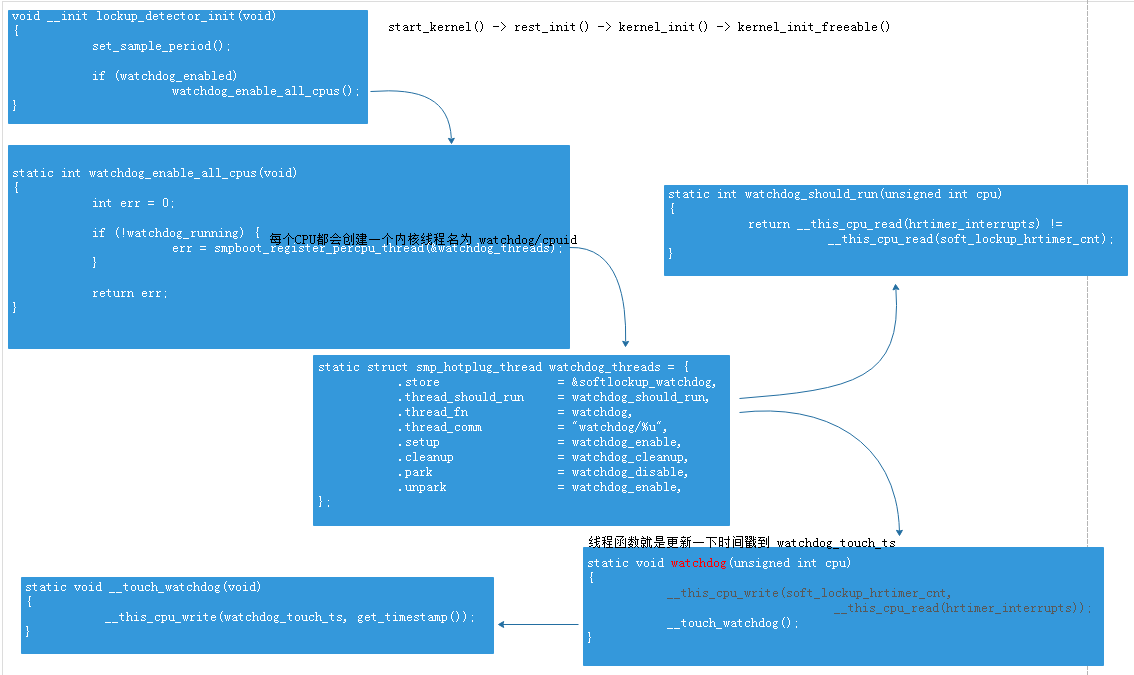
其实就是为每个CPU创建内核线程--watchdog/xx, 里面就只是更新时间戳而已(__touch_watchdog()), 只不过这个线程内核会有个while(1)大循环, 没必要老更新时间戳,
所以多个判断函数 -- watchdog_should_run(), 当然也可以在线程函数改成msleep(4000)也行
如何判断线程调度超时呢?
static int is_softlockup(unsigned long touch_ts) //watchdog_touch_ts { unsigned long now = get_timestamp(); if (watchdog_enabled & SOFT_WATCHDOG_ENABLED) { /* Warn about unreasonable delays. get_softlockup_thresh() = 20秒 */ if (time_after(now, touch_ts + get_softlockup_thresh())) return now - touch_ts; } return 0; }
now就是此刻时间, 参数是线程上次更新后的时间戳值, get_softlockup_thresh() = 20秒, 如果if为true, 说明这个线程已经过了20秒都没更新时间戳, 有问题! 在哪里判断呢? 在定时器中断watchdog_timer_fn()函数中,
这个定时器中断也是每个CPU都有的, 所以也放置在线程的初始化函数内 -- .setup = watchdog_enable(), 同时设置改线程为SCHED_FIFO 实时进程!
static void watchdog_enable(unsigned int cpu) { struct hrtimer *hrtimer = raw_cpu_ptr(&watchdog_hrtimer); /* kick off the timer for the hardlockup detector */ hrtimer_init(hrtimer, CLOCK_MONOTONIC, HRTIMER_MODE_REL); hrtimer->function = watchdog_timer_fn; /* Enable the perf event */ watchdog_nmi_enable(cpu); /* done here because hrtimer_start can only pin to smp_processor_id() */ hrtimer_start(hrtimer, ns_to_ktime(sample_period), HRTIMER_MODE_REL_PINNED); /* initialize timestamp */ watchdog_set_prio(SCHED_FIFO, MAX_RT_PRIO - 1); __touch_watchdog(); }
在中断函数中, 每产生一次中断, 判断该线程是否超时了, 超时的话就打印log“BUG: soft lockup - CPU#%d stuck for %us!”。 另外, 线程不是一直在跑, 只有在hrtimer_interrupts更新时候才会跑否则shedule出去, 所以在这更新后要唤醒线程!
static enum hrtimer_restart watchdog_timer_fn(struct hrtimer *hrtimer) { unsigned long touch_ts = __this_cpu_read(watchdog_touch_ts); struct pt_regs *regs = get_irq_regs(); int duration; int softlockup_all_cpu_backtrace = sysctl_softlockup_all_cpu_backtrace; /* kick the hardlockup detector hrtimer_interrupts++ */ watchdog_interrupt_count(); /* kick the softlockup detector */ wake_up_process(__this_cpu_read(softlockup_watchdog)); ............... duration = is_softlockup(touch_ts); }
2. hard lockup
hardlockup比较简单, 就是注册一个周期为10秒的不可屏蔽中断函数watchdog_overflow_callback(), 里面判断是否超时:
static int is_hardlockup(void) { unsigned long hrint = __this_cpu_read(hrtimer_interrupts); if (__this_cpu_read(hrtimer_interrupts_saved) == hrint) return 1; __this_cpu_write(hrtimer_interrupts_saved, hrint); return 0; }
由于不可屏蔽中断是10秒产生一次, 而定时器中断每4秒产生一次, 所以hrtimer_interrupts必然不等于hrtimer_interrupts_saved, 且将hrtimer_interrupts赋值到hrtimer_interrupts_saved进行更新,
如果哪次相等, 说明这10秒钟内该定时器中断都没有被执行! 从而打印"Watchdog detected hard LOCKUP on cpu %d"
当然触发后是警告式打印还是panic挂死系统取决用户的配置! 毕竟前面我说了, 有可能触发是正常现象, 如果是正常现象用户应该更改超时时间阈值, 不过我习惯panic(), 早发现早解决!
三、测试代码
softlockup测试用例, 如果针对SMP, 可以多创建几个线程以及绑定CPU
#include <linux/module.h> #include <linux/init.h> #include <linux/kernel.h> #include <linux/slab.h> #include <linux/gpio.h> #include <linux/of_gpio.h> #include <linux/delay.h> #include <linux/kthread.h> int test_thread0(void *data) { int cnt=0; printk("I will block CPU0 "); msleep(3000); printk("block CPU0 "); while(1){ mdelay(1000); printk("[CPU%d]block CPU %ds ", raw_smp_processor_id(), ++cnt); } } static int test_init(void) { struct task_struct *test_task0; printk("Vedic init..... "); test_task0 = kthread_create(test_thread0, NULL, "test_thread0"); if(IS_ERR(test_task0)) { printk("test_task0 fail "); return 0; } kthread_bind(test_task0, 0); wake_up_process(test_task0); return 0; } static void test_exit(void) { printk("Vedic exit...... "); } module_init(test_init); module_exit(test_exit); MODULE_LICENSE("Dual BSD/GPL"); MODULE_AUTHOR("Vedic <FZKmxcz@163.com>");
四、 其他
a. 上面的测试用例我在单核上出现softlockup panic, 但双核却没有, 甚至我开两个线程分别绑定CPU0/CPU1都正常运行, 怀疑跟系统的负载均衡有关, 即线程绑定某个CPU不会一直就在该CPU上运行的!
b. 无论是soft还是hard触发打印当前的线程, 都不能判定就是凶手, 只能说系统有问题, 需要进一步排查。
c. hard lockup依赖处理器有没有NIM中断, 没有的话无法实现