- COMST 2018
主要内容
- 这是一篇有关快速包转发的综述,先介绍了包转发的有关基础知识和背景,具体介绍了包转发的主流方法,对这些方法进行了细致详尽的比较,最后介绍了最新的方法和未来的研究方向。
- 包处理包括Fast Path 和Slow Path,前者用于包转发和包头处理,后者主要用于管理、错误控制、维护。
- 主要的方法有三种:纯软件、纯硬件、软硬结合。
- 纯软件方法主要在软件层面(零拷贝、批处理、并行性、用户/内核空间)进行性能优化,性能不足的主要是因为网络协议栈架构的不足。
- 纯硬件方法性能高但灵活性差。
- 软硬结合方法主要将部分功能卸载到高性能的硬件上,具有软件和硬件二者的优势。
- 软硬结合里硬件处理主要有三种:CPU,GPU,FPGA,主要是将部分功能卸载到硬件上,利用硬件的高性能处理包。
- CPU在指令并行上最大化,GPU在线程并行上最大化,FPGA有大量的并行但是使用硬件编程难度较大(HDLs)。
- 最新的方法包括:FD.io、VPP、ODP、OFP、P4、Openstate、BESS.
introduction
Highly demond
- increased performance of network interfaces:
- high-speed router
- multi-terabit IP router
- datacenter switch.
Main methods
- Software
- Hardware
- Combination of the two
General purpose device
Problem
- Networks stacks' architectural design brings high overheads
Solution
- Many kinds of technology
Programmable aspect
- Openflow:high-end specialized equipment and make it programmable
- Use general-purpose computers in the well-known environment
- "Semi-specialized" solution:use network processors to offload packet processing,rest is done on conventional processors
- Reconfigurable Hardware
Based on Three hardware
- Cpu:less latency and programs laster longer
- Gpu:expreme thread-level parallelism
- Fpga:energy efficient and not easy to program
Base on Virtualize environments
- Wire and wireless
Background
Terminology
- Time-critical and non-time critical
- Fast path and slow path
Time-critical router
- Corresponding to fast path
- Performed on the majority of packets that pass through the router
- Have the higher priority.
- Bypass the router processing card
- Including forwarding and header processing.
forwaring
- Bypass,ASICs
- Forwading table,classification,queue
header processing
- version->length->checksum->TTL
Non-time critical router
- Corresponding to slow path
- Mainly used for management, error handling and maintenance.
- ICMP,SNMP,ARP,PKT fragmentation(ipv4/v6)
Background on Packet Processing
- Target:maximizing the utilization of available resource and providing the fastest possible service.
- Surporting a high throughput implicates a sufficiently low packet processing latency.
Steps of Packet Processing
- NIC->(by DMA)memory->Cpu->ring buffer->NIC register->(by DMA)NIC
- Multiqueue NICs designed for multi-core.
- RSS(Receive-Side Scaling)enables distributed among different cores.
- Memory-mapping techqinues reduce the cost of packet transmission from kernel-space to user-space through system calls.
CPU/GPU/FPGA
- CPU maximize the instruction-level parallelism.
- GPU maximize the threads-level parallelism.
- FPGAs have massive amount parallelism built-in.
Software Implemetations
Click-based solutions
- Problem:Inflexible closed designs,difficult to extend,rounting configuration limited.
- Solution:Building blocks or fine-graned components which are called elements.
RouteBricks
- RouteBricks is a software router architecture which can run on multiple cores of a single server in order to leverage the performance of a software router.
FastClick
- FastClick is a solution which intergrates both DPDK and Netmap in Click.
Netmap
- Netmap is a framework which allows commodity hardware(withou modiying applications or adding custom hardware) to handle millions of packets per second which go over 1...10Gbit/s links
- It builds a fast path betwwen the NIC and the applications
- Regular mode is a standard mode where NIC exchanges packet with the host stack.
- Netmap mode,NIC rings are disconnected from the host netork stack and packets are disconnected from the host network stack and packets are transferred through the netmap API.
NetSlices
- NetSlices represents operting system abstraction which processes packets in user-space and enables a linear increase of performance with the number of cores.
PF_RING
- is a high-speed packet capture library that allows a commodity PC to perform efficient network mearsurement which allows both packet and active traffic analysis and manipulation.
DPDK
- ~is a set of data plane libraries and drivers which are used for fast packet procceing.
Gpu-based solutions
Snap
- Snap is a packet proccessing system based on Click which offloads some of the computation lod on GPUs.
PacketShader
- ~ is a software router framwork which uses Graphic Processing Units.
APUNet:
- ~ is an APU-accelerated network pakcet processing system that exploits the power of intgrated GPUs for parallel packet processing while using a COU for scalable packet I/O.
ClickNP
GASPP
- ~ is a programmable network traffic processing framework that was made of modern GPUs.
FPGA-based solutions
- represents and FPGA-accelerated platform for high performance and highly flexible Network NF processing on commodity servers.
GRIP
- The authors point out that transmitting or receiving data at gigabit speeds already fully monopolize the CPU, therefore, it is not possible to realize any additional processing of these data without degrading toughput.
SwitchBlade
- ~ represents a platform which is used for rapid prototyping and deployment of custon protocols on programmable hardware.
chimpp
- ~ is a development environment for reconfigurable networking hardware that is base on the Click modular router and that targets the NetFPGA platform.
Comparation
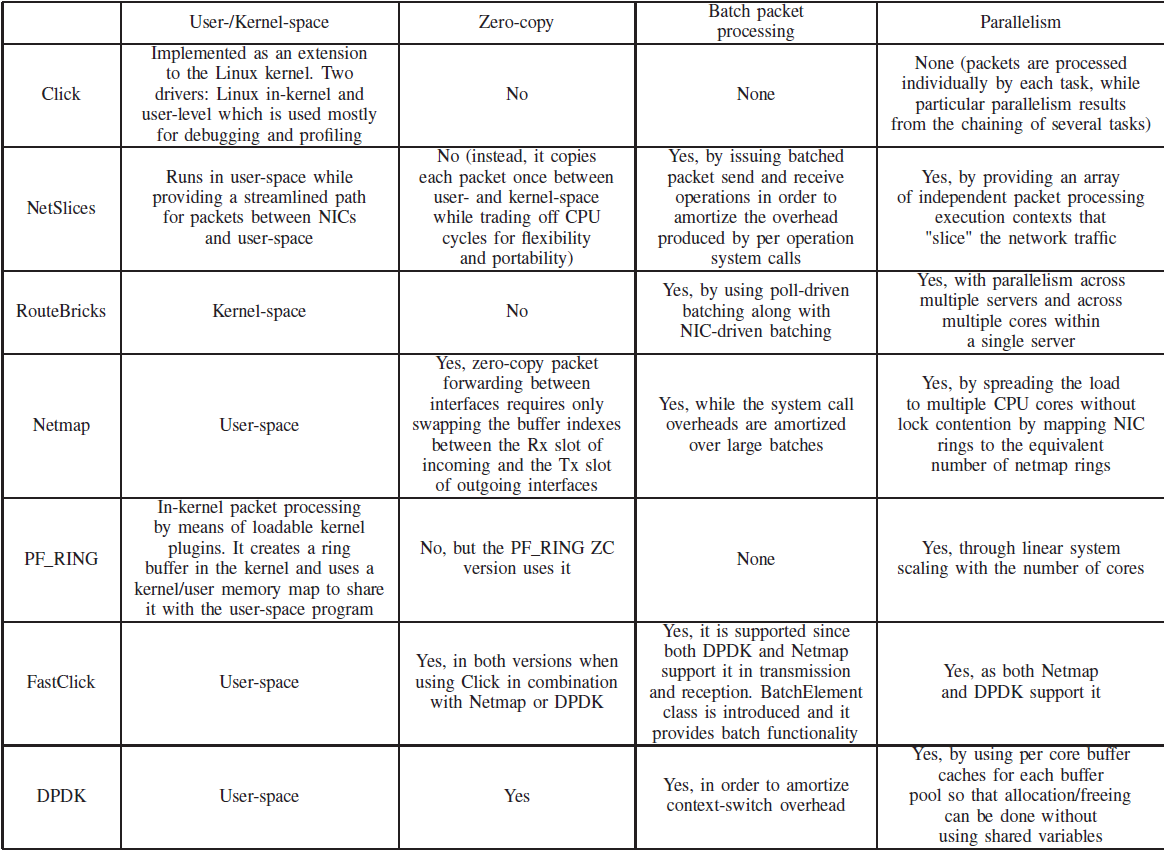
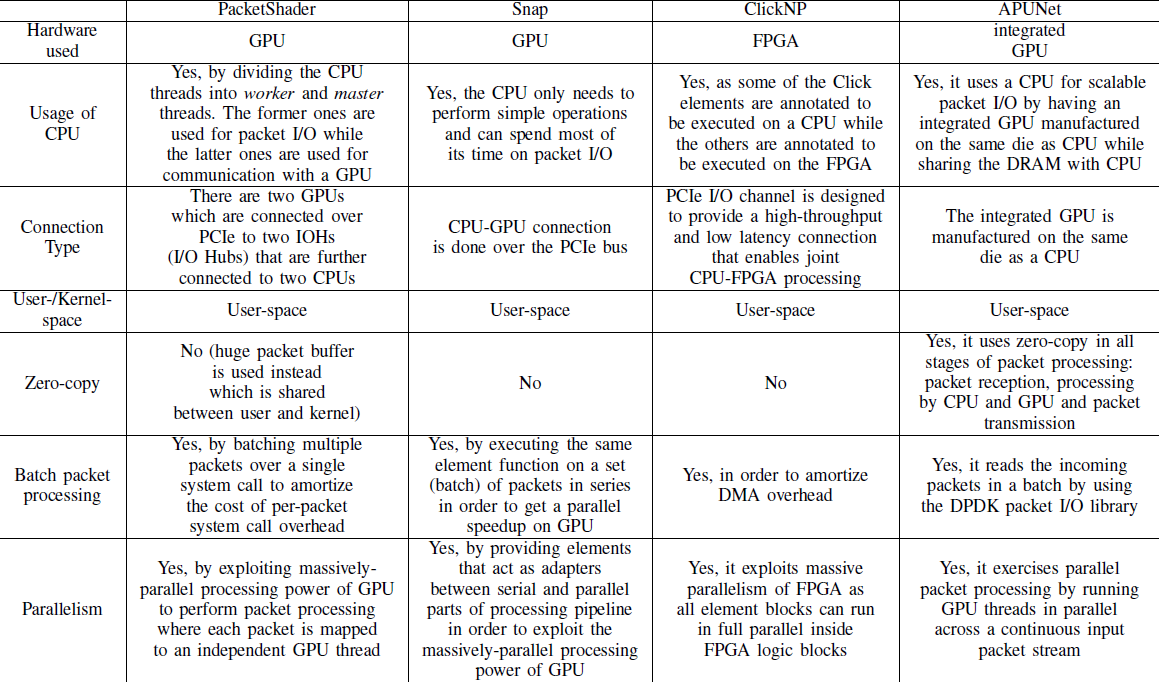
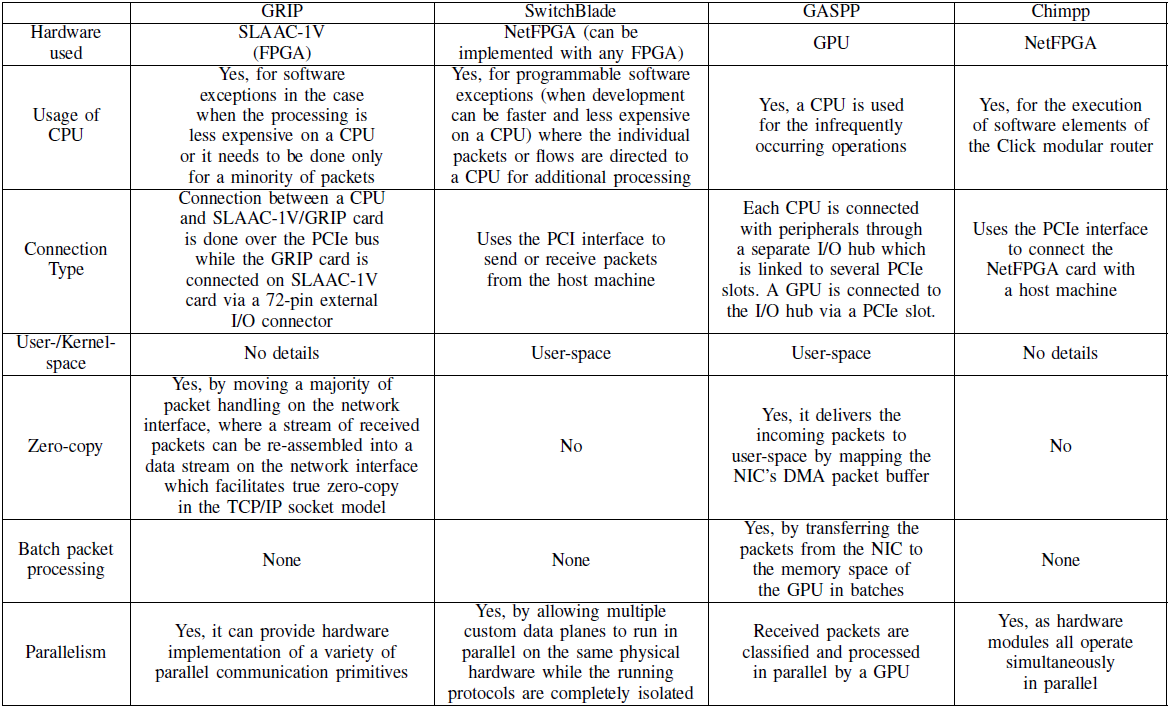
Integration Possibilityies in Virtualized Environments
- One solution to packet processing in virtualized environments: group packet processing instead of processing them individually.
VALE
- ~ is a system base on netmap API which implements high performance Virtual local Ethernet that can be used to interconnet virtual machines by providing access ports to multiple cients.
ptnetmap
- ~ is a Virual Passthrough solution based on the netmao framework, which is used as the "device" model exported to VMs.
NetVM
- ~ is a high-speed network packet processing platform built on top of KVM and DPDK library.
OVS+DPDK
- An open source virtual switch with high performance.
- It consumes too much cpu resource.
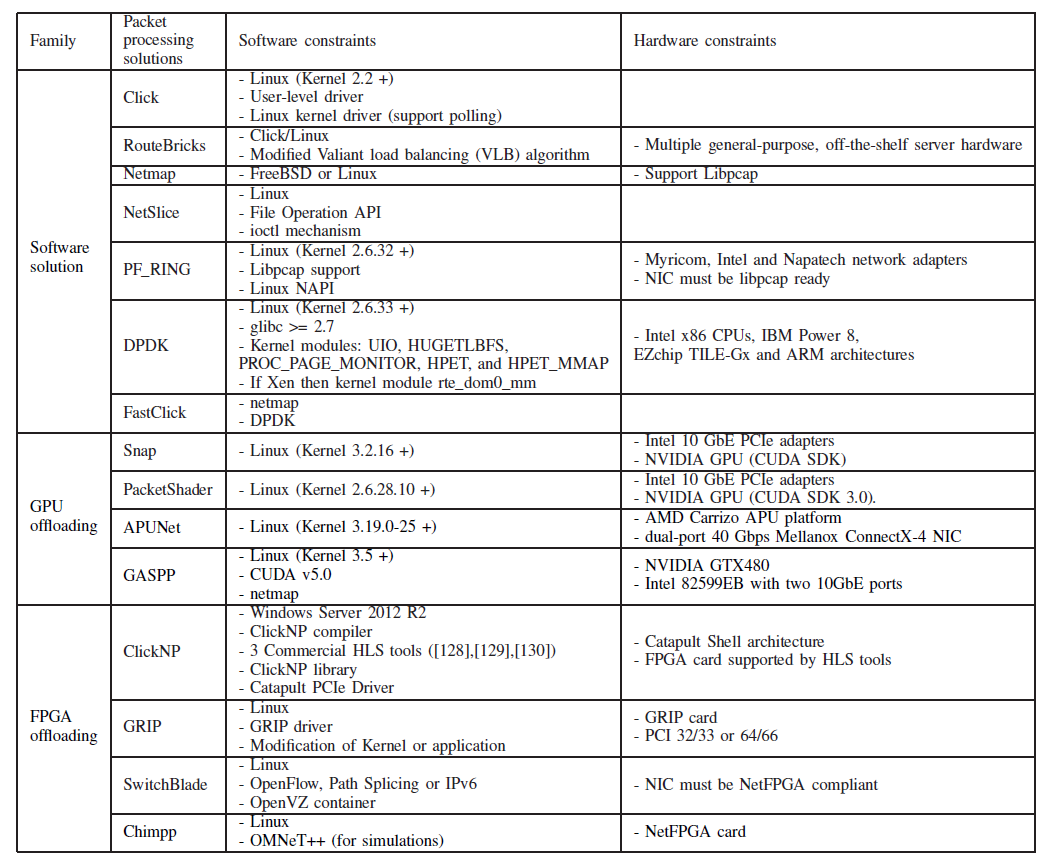
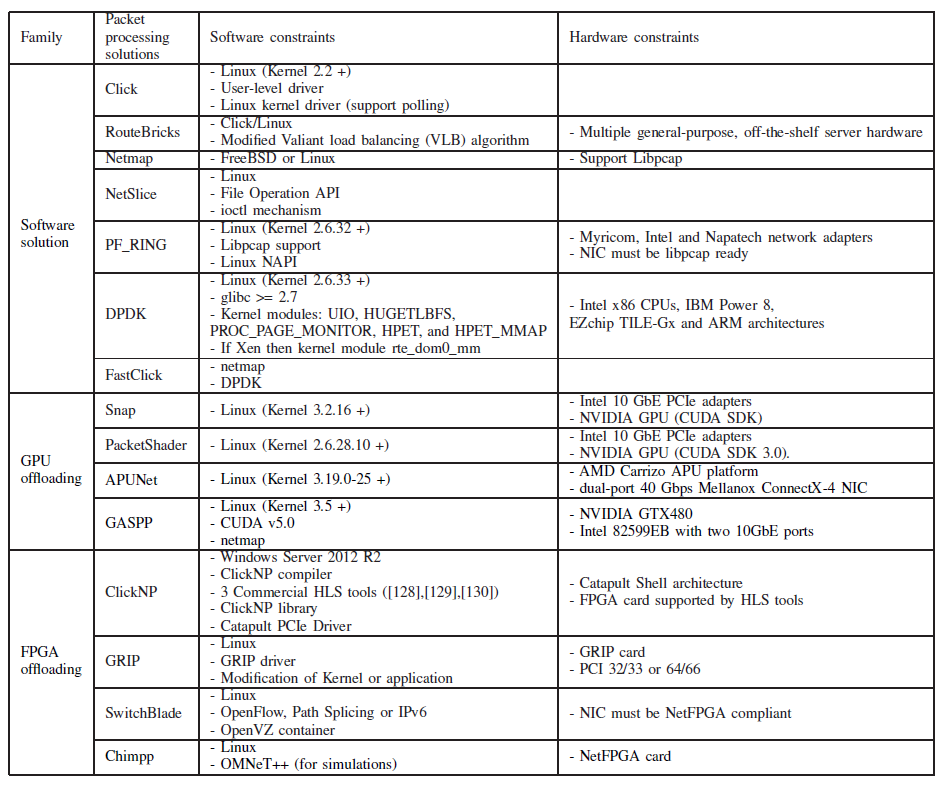
Summary of the constraints
Latest approaches and Future Directions
- FD.io
- VPP
- ODP:is a set of APIs for the networking software defined date palone which are open-source and cross-platform.
- OFP:A project provides an open-source implementation of high-performance TCP/IP stacks.
- P4:a high-level language used to program protocol-independent packet processors.
- Openstate:A approach which allows performing stateful control functionalities directly inside a switch without the nedd for the intervention of the externel controller.
- BESS is concerned with building a programmable plaform called SoftNIC that auguments hardware NICs with software.