一 . 要求
1. 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等,文件夹内的所有文件)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。
2. 使用性能测试工具进行分析,找到性能的瓶颈并改进
3.对代码进行质量分析,消除所有警告,http://msdn.microsoft.com/en-us/library/dd264897.aspx
4.设计10个测试样例用于测试,确保程序正常运行(例如:空文件,只包含一个词的文件,只有一行的文件,典型文件等等)
5.使用Github进行代码管理
6.撰写博客
二 . 基本功能
1. 统计文件的字符数
2. 统计文件的单词总数
3. 统计文件的总行数
4. 统计文件中各单词的出现次数,输出频率最高的10个。
5. 对给定文件夹及其递归子文件夹下的所有文件进行统计
6. 统计两个单词(词组)在一起的频率,输出频率最高的前10个。
7. 在Linux系统下,进行性能分析,过程写到blog中
三 . 功能分析与代码实现
1.统计文件字符:用fgetc()读取字符,ASCII码值在32~126之间则计数加一
2.统计文件行数:单一文件中的行数等于总换行符次数加一
3.统计单词个数:从词首开始判断,前四个字符都是字母时构成一个单词,第一次出现既不是字母也不是数字的字符时,单词结束。
4.递归遍历子文件夹:使用 vector<char*> getFilesList(const char * dir)函数,_finddata_t findData机构体,采用队列的结构递归遍历文件夹,读取每个跟文件夹的路径,然后转化为对单一文件夹的操作
5.统计单词出现的频率
(1)定义单词结构体
typedef struct Node
{
char wordroot[50];
char word[50];
int num;
Node *next;
}Node;
Node *Linkhead[26][26][26][26] = { NULL };
(2)定义Linkhead结构体指针数组,采用开散列(拉链法)
(3)当读取到一个单词时,获取单词的前四个字母归为一类,从对应的头节点下开始遍历链表,找到则对应的num++,未找到则构建一个单词结构体,头插到对应的链表下
6.统计词组出现的频率
(1)定义词组结构体
typedef struct Dword
{
char *firstword;
char *nextword;
int num;
}Dword;
Dword HashTable[20000000];
Node *prenode = NULL;
开始时想要存储两个单词数组,发现VS不允许申请这么大的内存空间,然后选择存储两个单词的词组指针,大大节约了空间
(2)定义HashTable(hash数组)来存储查找词组,hash函数值采用unsigned int ELFHash(char *str)得到
(3)每次用一个全局变量记录下前一个单词,和本次读到的单词组成词组,构建词组结构体。获得两个单词的词根将其组成一个字符串,用词根字符串去调用ELFHash()函数,得到一个较好的key值,在HashTable中从key值下标去查找,找到则对应的num++,未找到就将新的词组装入HashTable中
7.输出频率最高前十个单词和词组
(1)用一个容量为10的数组对所有的链表遍历,数组内降序排列,保留最大的前十个单词
(1)用一个容量为10的数组对HashTable遍历,数组内降序排列,保留最大的前十个词组
8.命令行的使用
int main(int argc, char *argv[]) strcpy(dir, argv[1]);
将命令行argv[1]字符串作为文件的根目录赋给dir形参,递归打开子文件夹
四. 附VS下源代码及输出结果
(1)源代码
#include <iostream>
#include <vector>
#include <cstring> // for strcat()
#include <io.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <iostream>
#include <algorithm>
#pragma warning(disable : 4996)
using namespace std;
int char_number = 0; // 分别记录字符数 单词数 行数
int word_number = 0;
int line_number = 0;
typedef struct Node
{
char wordroot[50];
char word[50];
int num;
Node *next;
}Node;
Node *prenode = NULL;
typedef struct Dword
{
char *firstword;
char *nextword;
int num;
}Dword;
Dword HashTable[20000000];
Node *Linkhead[26][26][26][26] = { NULL };
Node *Topword[15] = { NULL };
Dword *topphrase[15] = { NULL };
vector<char*> getFilesList(const char * dir);
void DwordHandler(Node *s);
int isZimu(char ch) //判断是否是字母
{
if (('a' <= ch && ch <= 'z') || ('A' <= ch && ch <= 'Z'))
return 1;
return 0;
}
int isOperator(char ch) { //判断是否是构成单词的元素
if (('a' <= ch && ch <= 'z') || ('A' <= ch && ch <= 'Z') || ('0' <= ch && ch <= '9'))
return 1;
return 0;
}
void getRoot(char *s, char* root) {
int i = 0, leng;
leng = strlen(s);
for (i = leng - 1; s[i] >= '0'&&s[i] <= '9'; i--)
leng--;
for (i = 0; i < leng; i++)
root[i] = s[i];
root[i] = '�';
for (i = 0; i<leng; i++)
if ('a' <= root[i] && root[i] <= 'z')
root[i] = root[i] - 32;
}
//得到单词S的大写词根存到root中
void wordHandler(char *s)
{
char root[50] = { 0 };
getRoot(s, root);
Node *p = NULL, *q = NULL;
p = Linkhead[root[0] - 'A'][root[1] - 'A'][root[2] - 'A'][root[3] - 'A'];
for (p; p &&strcmp(p->wordroot, root); p = p->next);
if (!p)
{
q = new Node;
q->num = 1; strcpy(q->word, s); strcpy(q->wordroot, root);
q->next = Linkhead[root[0] - 'A'][root[1] - 'A'][root[2] - 'A'][root[3] - 'A'];
Linkhead[root[0] - 'A'][root[1] - 'A'][root[2] - 'A'][root[3] - 'A'] = q;
DwordHandler(q);
}
else
{
p->num++;
if (strcmp(s, p->word) < 0)
strcpy(p->word, s);
DwordHandler(p);
}
}
void charCounter(FILE *fp) { //对字符计数
char ch;
rewind(fp);
while (EOF != (ch = fgetc(fp)))
if (32 <= ch && ch <= 126)
char_number++;
}
void lineCounter(FILE *fp) { //对行数计数
char ch;
rewind(fp);
while (EOF != (ch = fgetc(fp)))
if (ch == '
')
line_number++;
line_number++;
}
void wordCounter(FILE *fp) {
int flag = 0, i = 1, j = 0;
char a[50] = { 0 };
char ch;
rewind(fp);
if (!fp) return;
while (1) {
for (i = 0; i <= 3 && EOF != (ch = fgetc(fp)); i++)
{
if (!isZimu(ch)) break;
a[i] = ch;
}
if (i == 4) {
word_number++;
while (EOF != (ch = fgetc(fp)) && isOperator(ch))
{
if (i <= 45) a[i++] = ch; ////
}
a[i] = '�';
if (strlen(a) <= 40) ////
wordHandler(a);
}
if (EOF == ch) break;
}
}
unsigned int ELFHash(char *str) //计算一个字符串的hash值
{
unsigned int hash = 0;
unsigned int x = 0;
while (*str)
{
hash = (hash << 4) + (*str++);//hash左移4位,把当前字符ASCII存入hash低四位。
if ((x = hash & 0xF0000000L) != 0)
{
//如果最高的四位不为0,则说明字符多余7个,现在正在存第7个字符,如果不处理,再加下一个字符时,第一个字符会被移出,因此要有如下处理。
//该处理,如果最高位为0,就会仅仅影响5-8位,否则会影响5-31位,因为C语言使用的算数移位
//因为1-4位刚刚存储了新加入到字符,所以不能>>28
hash ^= (x >> 24);
//上面这行代码并不会对X有影响,本身X和hash的高4位相同,下面这行代码&~即对28-31(高4位)位清零。
hash &= ~x;
}
}
//返回一个符号位为0的数,即丢弃最高位,以免函数外产生影响。(我们可以考虑,如果只有字符,符号位不可能为负)
return (hash & 0x7FFFFFFF);
}
void DwordHandler(Node *s)
{
unsigned int key = 0;
int i = 0, j = 0;
if (!prenode)
{
prenode = s;
return;
}
char a[100] = { 0 }, b[100] = { 0 }, c[50] = { 0 }, d[50] = {0};
strcpy(a, prenode->wordroot);
strcat(a, " ");
strcat(a, s->wordroot);
key = ELFHash(a) % 19000000;
for (j = 0, i = key; j<19000000 && HashTable[i].num != 0; j++)
{
getRoot(HashTable[i].firstword, c);
strcpy(b, c);
strcat(b, " ");
getRoot(HashTable[i].nextword, d);
strcat(b, d);
if (!strcmp(a, b))
{
HashTable[i].num++;
if (strcmp(prenode->word, HashTable[i].firstword)<0)
HashTable[i].firstword = prenode->word;
if (strcmp(s->word, HashTable[i].nextword)<0)
HashTable[i].nextword = s->word;
break;
}
i = (i + 1) % 19000000;
}
if (HashTable[i].num == 0)
{
HashTable[i].firstword = prenode->word;
HashTable[i].nextword = s->word;
HashTable[i].num = 1;
}
prenode = s;
}
void CountQuantity(const char *fileName)
{
FILE *fp;
fp = fopen(fileName, "r");
if (!fp) printf("fail to open
");
charCounter(fp);
lineCounter(fp);
wordCounter(fp);
fclose(fp);
return ;
}
void getTopWord()
{
int i = 0, j = 0, k = 0, l = 0, n = 0, m = 0, r = 0;
Node *p;
for (i = 0; i<26; i++)
for (j = 0; j<26; j++)
for (k = 0; k<26; k++)
for (l = 0; l < 26; l++)
for (p = Linkhead[i][j][k][l]; p; p = p->next)
{
for (m = 0; m < 10 && Topword[m]; m++); //m 第一个空下标
if (m <= 9) //Topword未装满时
{
for (n = m - 1; n >= 0 && Topword[n]->num < p->num; n--)
Topword[n + 1] = Topword[n];
Topword[n + 1] = p;
}
else //Topword
{
for (n = 9; n >= 0 && Topword[n]->num < p->num; n--)
Topword[n + 1] = Topword[n];
Topword[n + 1] = p;
}
}
}
void getTopDword()
{
int i = 0, j = 0, m = 0;
while (HashTable[i].num == 0 && i<=19000000) i++;
for ( ; i < 19000000; i++)
{
// while (HashTable[i].num==0) i++;
for (m = 0; m < 10 && topphrase[m]; m++); //m 第一个空下标
if (m <= 9) //Topdword未装满时
{
for (j = m - 1; j >= 0 && topphrase[j]->num < HashTable[i].num; j--)
topphrase[j + 1] = topphrase[j];
topphrase[j + 1] = &HashTable[i];
}
else //Topword
{
for (j = 9; j >= 0 && topphrase[j]->num < HashTable[i].num; j--)
topphrase[j + 1] = topphrase[j];
topphrase[j + 1] = &HashTable[i];
}
}
}
int main(int argc, char *argv[]) //C:UsersstardustDesktop estfile
{
int k = 0;
char dir[200];
FILE *fp=NULL;
strcpy(dir, argv[1]);
//cout << "Enter a directory: ";
//cin.getline(dir, 200);
vector<char*>allPath = getFilesList(dir);
//cout << "输出所有文件的路径:" << endl;
for (size_t i = 0; i < allPath.size(); i++)
{
char *perPath = allPath.at(i); //perpath是所有文件的根文件名字符串
//cout << perPath << endl; //打印处所有的文件名
CountQuantity(perPath);
}
getTopWord();
getTopDword();
fp = fopen("result.txt", "w");
fprintf(fp, "char_number=%d
line_number=%d
word_number=%d
", char_number, line_number, word_number);
fprintf(fp, "the top ten frequency of word :
");
for (k = 0; k < 10; k++)
fprintf(fp, "%-6s %-6d
", Topword[k]->word, Topword[k]->num);
fprintf(fp,"
");
fprintf(fp, "the top ten frequency of phrase :
");
for (k = 0; k < 10; k++)
fprintf(fp, "%-10s%-10s %-10d
", topphrase[k]->firstword, topphrase[k]->nextword, topphrase[k]->num);
fprintf(fp,"
");
fclose(fp);
return 0;
}
vector<char*> getFilesList(const char * dir)
{
vector<char*> allPath;
char dirNew[200];
strcpy(dirNew, dir);
strcat(dirNew, "\*.*"); // 在目录后面加上"\*.*"进行第一次搜索
intptr_t handle;
_finddata_t findData;
handle = _findfirst(dirNew, &findData);
if (handle == -1)
{// 检查是否成功
strcpy(dirNew, dir);
handle = _findfirst(dirNew, &findData);
if (-1 == handle)
{
cout << "can not found the file ... " << endl;
return allPath;
}
else
{
allPath.push_back(const_cast <char*>(dir));
return allPath;
}
}
do
{
if (findData.attrib & _A_SUBDIR)//// 是否含有子目录
{
//若该子目录为"."或"..",则进行下一次循环,否则输出子目录名,并进入下一次搜索
if (strcmp(findData.name, ".") == 0 || strcmp(findData.name, "..") == 0)
continue;
//cout << findData.name << " <dir>
";
// 在目录后面加上"\"和搜索到的目录名进行下一次搜索
strcpy(dirNew, dir);
strcat(dirNew, "\");
strcat(dirNew, findData.name);
vector<char*> tempPath = getFilesList(dirNew);
allPath.insert(allPath.end(), tempPath.begin(), tempPath.end());
}
else //不是子目录,即是文件,则输出文件名和文件的大小
{
char *filePath = new char[200];
strcpy(filePath, dir);
strcat(filePath, "\");
strcat(filePath, findData.name);
allPath.push_back(filePath);
//cout << filePath << " " << findData.size << " bytes.
";
}
} while (_findnext(handle, &findData) == 0);
_findclose(handle); // 关闭搜索句柄
return allPath;
}
(2)输出结果比较
左侧为助教的输出,右侧为我的输出,字符数和行数差别不大,单词数多了一万个(不知道为什么),前十个单词和词组完全一致

五.VS下的性能分析
测试环境:VS2017,Release模式
(1)CPU和GPU使用情况

(2)主要的函数占用GPU细节
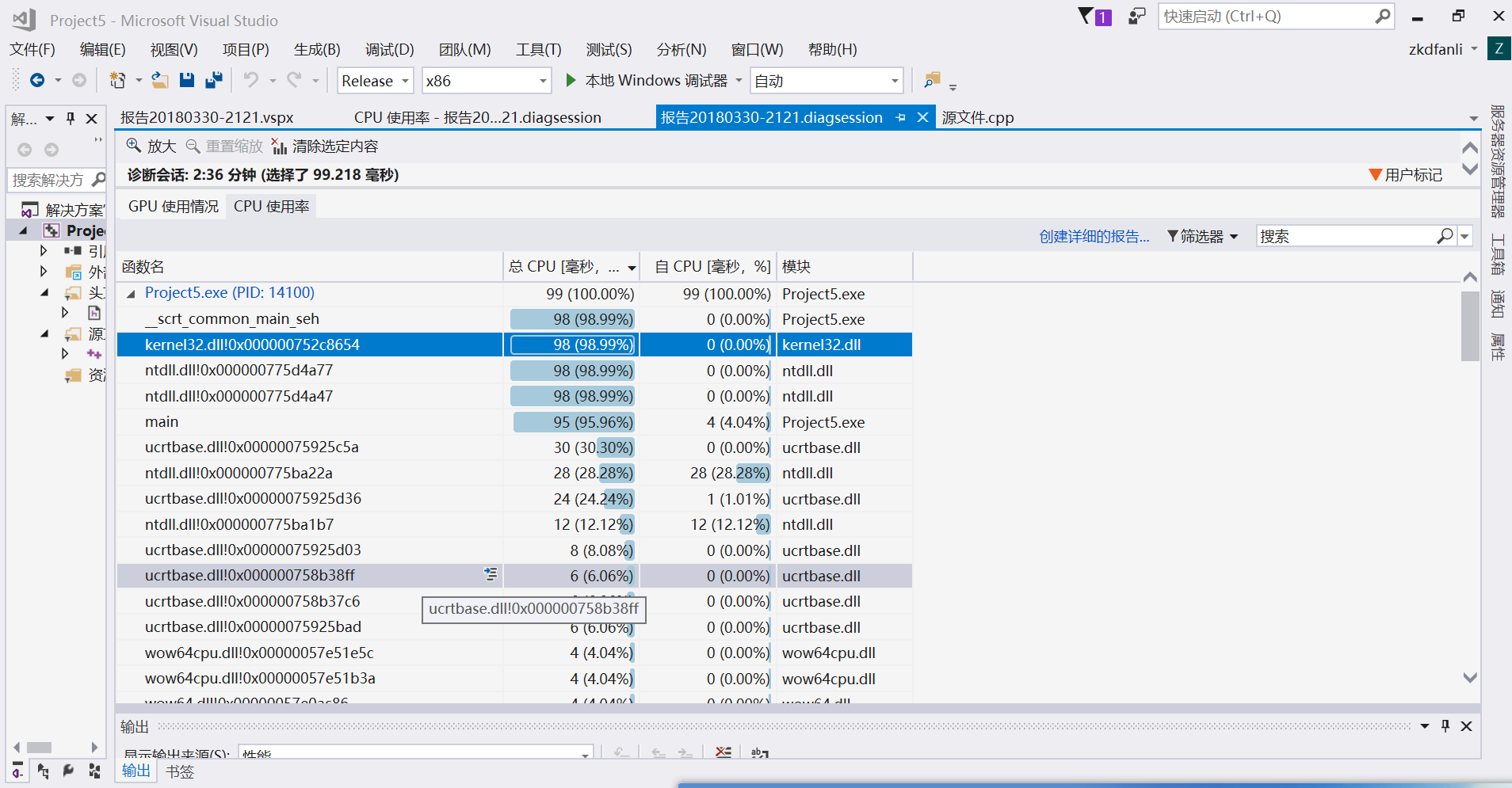
(3)main函数占用CPU细节
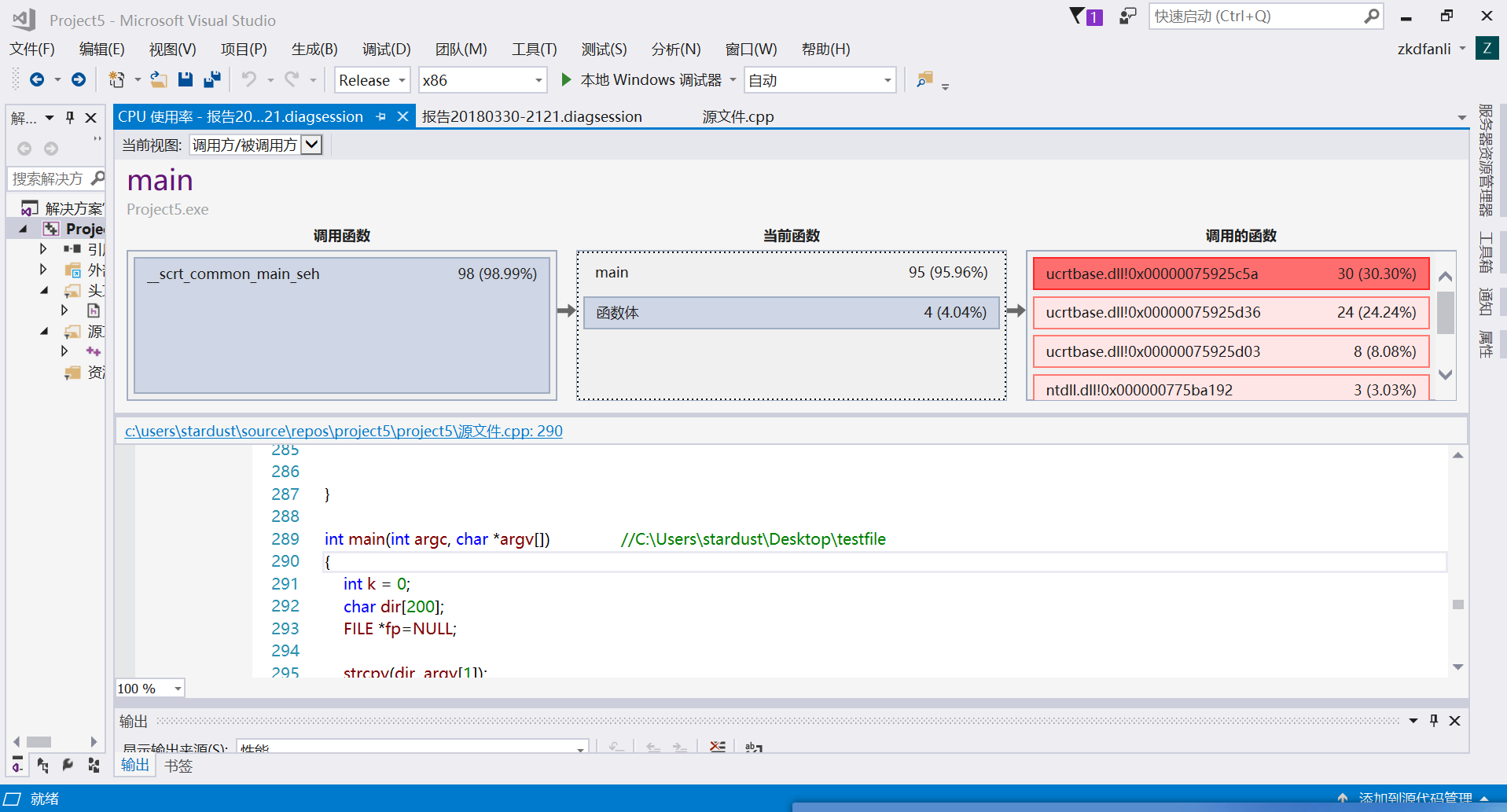
通过对热行查看,运行次数最多的就是fgetc()函数,有的同学建议使用 fread函数,但是最后没有时间修改
六.LINUX下的性能分析
将VS下编译通过的代码适当修改后在LINUX下也可以运行,使用GPROF性能分析工具,得到一份如下的性能分析报告
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
40.08 4.88 4.88 16639177 0.00 0.00 DwordHandler(Node*)
17.28 6.98 2.10 48593941 0.00 0.00 getRoot(char*, char*)
15.64 8.88 1.90 16639177 0.00 0.00 wordHandler(char*)
10.94 10.22 1.33 16639176 0.00 0.00 ELFHash(char*)
5.68 10.91 0.69 1323 0.00 0.01 wordCounter(_IO_FILE*)
3.21 11.30 0.39 1 0.39 0.39 getTopDword()
2.55 11.61 0.31 132121068 0.00 0.00 isZimu(char)
1.89 11.84 0.23 1323 0.00 0.00 charCounter(_IO_FILE*)
1.48 12.02 0.18 1323 0.00 0.00 lineCounter(_IO_FILE*)
1.32 12.18 0.16 48986288 0.00 0.00 isOperator(char)
0.08 12.19 0.01 1 0.01 0.01 getTopWord()
0.00 12.19 0.00 1323 0.00 0.01 CountQuantity(char const*)
0.00 12.19 0.00 1 0.00 0.00 _GLOBAL__sub_I_char_number
0.00 12.19 0.00 1 0.00 0.00 __static_initialization_and_destruction_0(int, int)
0.00 12.19 0.00 1 0.00 11.79 listDir(char*)
% the percentage of the total running time of the
time program used by this function.
cumulative a running sum of the number of seconds accounted
seconds for by this function and those listed above it.
self the number of seconds accounted for by this
seconds function alone. This is the major sort for this
listing.
calls the number of times this function was invoked, if
this function is profiled, else blank.
self the average number of milliseconds spent in this
ms/call function per call, if this function is profiled,
else blank.
total the average number of milliseconds spent in this
ms/call function and its descendents per call, if this
function is profiled, else blank.
name the name of the function. This is the minor sort
for this listing. The index shows the location of
the function in the gprof listing. If the index is
in parenthesis it shows where it would appear in
the gprof listing if it were to be printed.
Copyright (C) 2012-2015 Free Software Foundation, Inc.
Copying and distribution of this file, with or without modification,
are permitted in any medium without royalty provided the copyright
notice and this notice are preserved.
Call graph (explanation follows)
granularity: each sample hit covers 2 byte(s) for 0.08% of 12.19 seconds
index % time self children called name
<spontaneous>
[1] 100.0 0.00 12.19 main [1]
0.00 11.79 1/1 listDir(char*) [3]
0.39 0.00 1/1 getTopDword() [9]
0.01 0.00 1/1 getTopWord() [14]
-----------------------------------------------
0.00 11.79 1323/1323 listDir(char*) [3]
[2] 96.7 0.00 11.79 1323 CountQuantity(char const*) [2]
0.69 10.69 1323/1323 wordCounter(_IO_FILE*) [4]
0.23 0.00 1323/1323 charCounter(_IO_FILE*) [11]
0.18 0.00 1323/1323 lineCounter(_IO_FILE*) [12]
-----------------------------------------------
125 listDir(char*) [3]
0.00 11.79 1/1 main [1]
[3] 96.7 0.00 11.79 1+125 listDir(char*) [3]
0.00 11.79 1323/1323 CountQuantity(char const*) [2]
125 listDir(char*) [3]
-----------------------------------------------
0.69 10.69 1323/1323 CountQuantity(char const*) [2]
[4] 93.3 0.69 10.69 1323 wordCounter(_IO_FILE*) [4]
1.90 8.31 16639177/16639177 wordHandler(char*) [5]
0.31 0.00 132121068/132121068 isZimu(char) [10]
0.16 0.00 48986288/48986288 isOperator(char) [13]
-----------------------------------------------
1.90 8.31 16639177/16639177 wordCounter(_IO_FILE*) [4]
[5] 83.8 1.90 8.31 16639177 wordHandler(char*) [5]
4.88 2.71 16639177/16639177 DwordHandler(Node*) [6]
0.72 0.00 16639177/48593941 getRoot(char*, char*) [7]
-----------------------------------------------
4.88 2.71 16639177/16639177 wordHandler(char*) [5]
[6] 62.3 4.88 2.71 16639177 DwordHandler(Node*) [6]
1.38 0.00 31954764/48593941 getRoot(char*, char*) [7]
1.33 0.00 16639176/16639176 ELFHash(char*) [8]
-----------------------------------------------
0.72 0.00 16639177/48593941 wordHandler(char*) [5]
1.38 0.00 31954764/48593941 DwordHandler(Node*) [6]
[7] 17.3 2.10 0.00 48593941 getRoot(char*, char*) [7]
-----------------------------------------------
1.33 0.00 16639176/16639176 DwordHandler(Node*) [6]
[8] 10.9 1.33 0.00 16639176 ELFHash(char*) [8]
-----------------------------------------------
0.39 0.00 1/1 main [1]
[9] 3.2 0.39 0.00 1 getTopDword() [9]
-----------------------------------------------
0.31 0.00 132121068/132121068 wordCounter(_IO_FILE*) [4]
[10] 2.5 0.31 0.00 132121068 isZimu(char) [10]
-----------------------------------------------
0.23 0.00 1323/1323 CountQuantity(char const*) [2]
[11] 1.9 0.23 0.00 1323 charCounter(_IO_FILE*) [11]
-----------------------------------------------
0.18 0.00 1323/1323 CountQuantity(char const*) [2]
[12] 1.5 0.18 0.00 1323 lineCounter(_IO_FILE*) [12]
-----------------------------------------------
0.16 0.00 48986288/48986288 wordCounter(_IO_FILE*) [4]
[13] 1.3 0.16 0.00 48986288 isOperator(char) [13]
-----------------------------------------------
0.01 0.00 1/1 main [1]
[14] 0.1 0.01 0.00 1 getTopWord() [14]
-----------------------------------------------
0.00 0.00 1/1 __libc_csu_init [28]
[21] 0.0 0.00 0.00 1 _GLOBAL__sub_I_char_number [21]
0.00 0.00 1/1 __static_initialization_and_destruction_0(int, int) [22]
-----------------------------------------------
0.00 0.00 1/1 _GLOBAL__sub_I_char_number [21]
[22] 0.0 0.00 0.00 1 __static_initialization_and_destruction_0(int, int) [22]
-----------------------------------------------
This table describes the call tree of the program, and was sorted by
the total amount of time spent in each function and its children.
Each entry in this table consists of several lines. The line with the
index number at the left hand margin lists the current function.
The lines above it list the functions that called this function,
and the lines below it list the functions this one called.
This line lists:
index A unique number given to each element of the table.
Index numbers are sorted numerically.
The index number is printed next to every function name so
it is easier to look up where the function is in the table.
% time This is the percentage of the `total' time that was spent
in this function and its children. Note that due to
different viewpoints, functions excluded by options, etc,
these numbers will NOT add up to 100%.
self This is the total amount of time spent in this function.
children This is the total amount of time propagated into this
function by its children.
called This is the number of times the function was called.
If the function called itself recursively, the number
only includes non-recursive calls, and is followed by
a `+' and the number of recursive calls.
name The name of the current function. The index number is
printed after it. If the function is a member of a
cycle, the cycle number is printed between the
function's name and the index number.
For the function's parents, the fields have the following meanings:
self This is the amount of time that was propagated directly
from the function into this parent.
children This is the amount of time that was propagated from
the function's children into this parent.
called This is the number of times this parent called the
function `/' the total number of times the function
was called. Recursive calls to the function are not
included in the number after the `/'.
name This is the name of the parent. The parent's index
number is printed after it. If the parent is a
member of a cycle, the cycle number is printed between
the name and the index number.
If the parents of the function cannot be determined, the word
`<spontaneous>' is printed in the `name' field, and all the other
fields are blank.
For the function's children, the fields have the following meanings:
self This is the amount of time that was propagated directly
from the child into the function.
children This is the amount of time that was propagated from the
child's children to the function.
called This is the number of times the function called
this child `/' the total number of times the child
was called. Recursive calls by the child are not
listed in the number after the `/'.
name This is the name of the child. The child's index
number is printed after it. If the child is a
member of a cycle, the cycle number is printed
between the name and the index number.
If there are any cycles (circles) in the call graph, there is an
entry for the cycle-as-a-whole. This entry shows who called the
cycle (as parents) and the members of the cycle (as children.)
The `+' recursive calls entry shows the number of function calls that
were internal to the cycle, and the calls entry for each member shows,
for that member, how many times it was called from other members of
the cycle.
Copyright (C) 2012-2015 Free Software Foundation, Inc.
Copying and distribution of this file, with or without modification,
are permitted in any medium without royalty provided the copyright
notice and this notice are preserved.
Index by function name
[21] _GLOBAL__sub_I_char_number [12] lineCounter(_IO_FILE*) [22] __static_initialization_and_destruction_0(int, int)
[14] getTopWord() [4] wordCounter(_IO_FILE*) [10] isZimu(char)
[13] isOperator(char) [5] wordHandler(char*) [8] ELFHash(char*)
[11] charCounter(_IO_FILE*) [6] DwordHandler(Node*) [7] getRoot(char*, char*)
[9] getTopDword() [2] CountQuantity(char const*) [3] listDir(char*)
七.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 50 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 1245 | ∞ |
| · Analysis | · 需求分析 (包括学习新技术) | 2h * 60 | 3h * 60 |
| · Design Spec | · 生成设计文档 | 30 | 20 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 5 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 10h * 60 | 10h * 60 |
| · Code Review | · 代码复审 | 30 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 6h * 60 | 8h * 60 |
| Reporting | 报告 | 70 | 60 |
| · Test Report | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 20 |
| 合计 | 1200 | ∞ |