linux操作系统内核分析这门课程主要可以分为三大块内容:
1.内核分析所需要的基础知识
如X86汇编,函数调用堆栈,存储计算机工作原理等
2.系统调用的原理和实现
如用户态与内核态,中断上下文的切换等
3.进程管理
进程是操作系统中最重要的抽象,因为进程是资源分配的基本单位,其他的抽象都是围绕他来进行的。
进程管理主要涉及进程的创建,进程的执行环境,进程的切换。
一.x86汇编
这门课程中主要涉及的硬件就是CPU,选择的CPU指令集是X86汇编,学习的重点是进程管理部分,对内存管理,文件管理比较忽略,相关的硬件细节也被忽略
学习X86指令集的关键事实上在于以下几个部分:
- 记忆理解X86的CPU寄存器 cs eip ss esp ds 等等
- 程序的逻辑分段(代码段,堆栈段,数据段)
- 函数调用堆栈
计算机工作的基础
计算机是如何工作的?(总结)——三个法宝:存储程序计算机 函数调用堆栈 中断 1.存储程序计算机工作模型,计算机系统最最基础性的逻辑结构; 2.函数调用堆栈,高级语言得以运行的基础,只有机器语言和汇编语言的时候堆栈机制对于计算机来说并不那么重要,但有了高级语言及函数,堆栈成为了计算机的基础功能; enter pushl %ebp movl %esp,%ebp leave movl %ebp,%esp popl %ebp 函数参数传递机制和局部变量存储 3.中断,多道程序操作系统的基点,没有中断机制程序只能从头一直运行结束才有可能开始运行其他程序。
二、C语言函数调用堆栈框架
1.堆栈是C语言运行时必须的一个记录调用路径和参数的空间
2.相关寄存器和堆栈操作
SP(栈顶指针) BP(栈底指针) PUSH(进栈) POP(出栈)
栈是由高地址向低地址增长的,所以有元素进栈是esp里的值是减4

3.函数调用和返回
CALL RET

4.函数堆栈框架
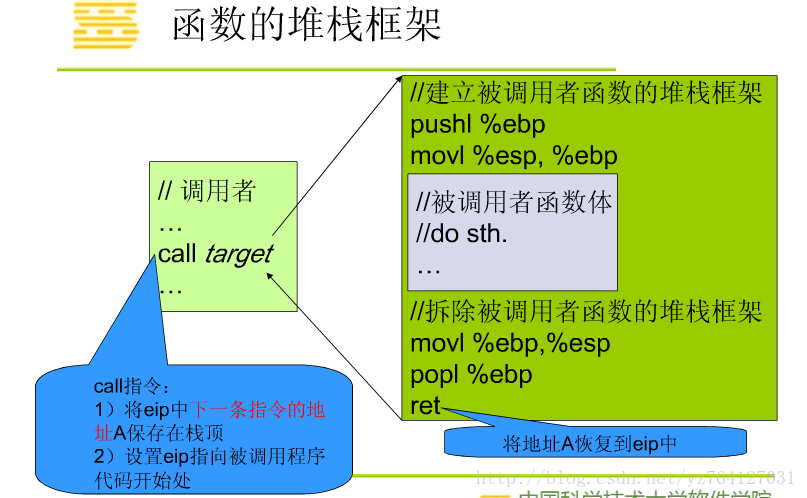
将eip中下一条指令的地址A保存在栈顶其实就是讲eip中下一条指令的地址存放在esp寄存器中 然后esp里的值又赋值给ebp 所以ebp就保存了eip中中下一条指令的地址
函数堆栈框架的形成:

三.系统调用
操作系统提供的抽象的本质:
操作系统提供了进程,地址空间,文件三个抽象,本质上是对硬件的虚拟,使得硬件由物理上的一个变为逻辑上的多个,利用的就是共享(时间或者空间)。
系统的调用的本质:

系统调用可以看做特殊的函数调用,所以每次进行系统调用都要新建堆栈。
系统调用程序及服务例程

int $0x80 是指中断向量表的第128号中断,而第128号中断就是系统调用
传递系统调用号用eax寄存器
系统调用的参数传递

(3)进程管理
文件和地址空间事实上都是依赖进程这个抽象,进程通过系统调用来控制其他的资源。
进程的描述
进程控制块PCB——task_struct
进程的标示pid
所有进程链表struct list_head tasks;(双向链表)
程序创建的进程具有父子关系
Linux为每个进程分配一个8KB大小的内存区域,用于存放该进程两个不同的数据结构:Thread_info和进程的内核堆栈
进程处于内核态时使用,不同于用户态堆栈,即PCB中指定了内核栈,
内核控制路径所用的堆栈很少,因此对栈和Thread_info来说,8KB足够
进程的创建
创建一个新进程在内核中的执行过程 fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建; Linux通过复制父进程来创建一个新进程,那么这就给我们理解这一个过程提供一个想象的框架: 复制一个PCB——task_struct err = arch_dup_task_struct(tsk, orig); 要给新进程分配一个新的内核堆栈 ti = alloc_thread_info_node(tsk, node); tsk->stack = ti; setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈 要修改复制过来的进程数据,比如pid、进程链表等等都要改改吧,见copy_process内部。 从用户态的代码看fork();函数返回了两次,即在父子进程中各返回一次,父进程从系统调用中返回比较容易理解,子进程从系统调用中返回,那它在系统调用处理过程中的哪里开始执行
的呢?这就涉及子进程的内核堆栈数据状态和task_struct中thread记录的sp和ip的一致性问题,这是在哪里设定的?copy_thread in copy_process *childregs = *current_pt_regs(); //复制内核堆栈 childregs->ax = 0; //为什么子进程的fork返回0,这里就是原因! p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶 p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址
进程的装载
程序生成可执行文件的过程
可执行文件装载生成进程,并进行静态与动态链接库文件的过程
详细过程略,主要参考书 《程序员的自我修养》
进程的切换和系统的一般执行过程
进程的调度时机与进程的切换
操作系统原理中介绍了大量进程调度算法,这些算法从实现的角度看仅仅是从运行队列中选择一个新进程,选择的过程中运用了不同的策略而已。
对于理解操作系统的工作机制,反而是进程的调度时机与进程的切换机制更为关键。
进程调度的时机
中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule();
内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度;
用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度。
进程的切换
为了控制进程的执行,内核必须有能力挂起正在CPU上执行的进程,并恢复以前挂起的某个进程的执行,这叫做进程切换、任务切换、上下文切换;
挂起正在CPU上执行的进程,与中断时保存现场是不同的,中断前后是在同一个进程上下文中,只是由用户态转向内核态执行;
进程上下文包含了进程执行需要的所有信息
用户地址空间:包括程序代码,数据,用户堆栈等
控制信息:进程描述符,内核堆栈等
硬件上下文(注意中断也要保存硬件上下文只是保存的方法不同)
schedule()函数选择一个新的进程来运行,并调用context_switch进行上下文的切换,这个宏调用switch_to来进行关键上下文切换
next = pick_next_task(rq, prev);//进程调度算法都封装这个函数内部 context_switch(rq,
prev, next);//进程上下文切换
switch_to利用了prev和next两个参数:prev指向当前进程,next指向被调度的进程
以用户读一个文件为例
当用户点击打开文件时, 会调用库函数中的read()函数, 而在这个函数中会触发软中断指令, CPU正式陷入到内核态, 进程堆栈也会切换到相应的内核态堆栈.接着, 进入异常处理的硬件级流程, 在这个过程中, CPU在栈中保存eflags, cs, 和eip的 内容, 随后进入异常处理的软件级流程, 在这个过程中, CPU会进一步保存上下文. 与这个过程相对应的是: CPU读取idtr寄存器指向的IDT表中的第128项,此时可以得到0x80中断门, 通过这个中断门CPU可以得到中断处理例程. 接着, 中断处理例程会到系统调用表中找到read()函数相对应的VFS虚拟文件系统中的系统调用sys_read()
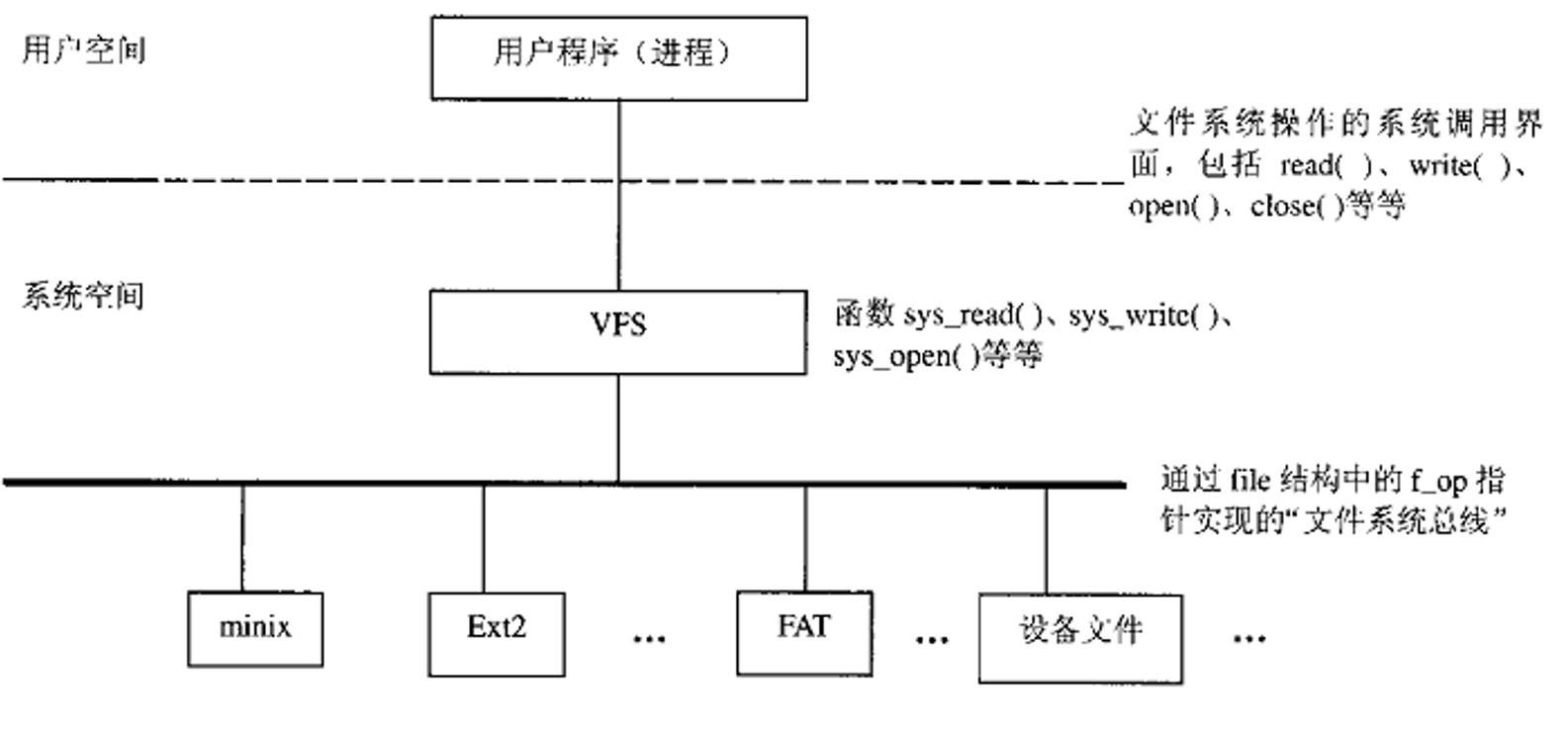
文件打开之后, 将pt_regs数据结构中描述的寄存器以及cs:eip寄存器恢复, 此时进程又重新恢复到了用户态, 并沿着read()函数的下一条语句继续执行.上述具体的过程可以看看Linux文件系统的逻辑结构.如下图,

心得体会
本学期的linux操作系统分析课程,向我们展示了linux很多功能的底层实现,让我对linux操作系统有了更进一步和更深刻的理解,孟宁老师布置的实验让我们了解了进程的切换、嵌入式汇编、内核的编译、根文件系统的挂载、系统调用的各种具体实现,李春杰老师的理论课程部分带领我们阅读了linux内核源码,加深对知识的理解,这门课程让我收获颇丰,感谢两位老师的教导。