Docker部署RbbitMQ集群及Haproxy高可用
环境准备
Centos 7.8三台ECS:
-
192.168.102.10
-
192.168.102.11
-
192.168.102.12
以上虚拟机统一安装docker环境
三台机器分别配置如下所示的hosts文件,以供rabbitmq容器使用
$ vim /home/rabbitmq/hosts //文件中写入以下内容:
192.168.10.10 rabbit1 rabbit1 192.168.10.11 rabbit2 rabbit2 192.168.10.12 rabbit3 rabbit3
搭建过程
拉取镜像
在三台机器上,分别management版本的rabbitmq镜像
docker pull rabbitmq:3.8.3-management
创建容器
在三台机器上分别创建rabbitmq容器
-
在192.168.102.10上创建容器rabbit1
$ docker run -d --restart=unless-stopped --name rabbit1 -h rabbit1 -p 5672:5672 -p 15672:15672 -p 25672:25672 -p 4369:4369 -v /home/rabbitmq:/var/lib/rabbitmq:z -v /home/rabbitmq/hosts:/etc/hosts -e RABBITMQ_DEFAULT_USER=monitor -e RABBITMQ_DEFAULT_PASS=123456 -e RABBITMQ_ERLANG_COOKIE='monitor_cluster_cookie' rabbitmq:3.8.3-management
-
在192.168.102.11上创建容器rabbit2
$ docker run -d --restart=unless-stopped --name rabbit2 -h rabbit2 -p 5672:5672 -p 15672:15672 -p 25672:25672 -p 4369:4369 -v /home/rabbitmq:/var/lib/rabbitmq:z -v /home/rabbitmq/hosts:/etc/hosts -e RABBITMQ_DEFAULT_USER=monitor -e RABBITMQ_DEFAULT_PASS=123456 -e RABBITMQ_ERLANG_COOKIE='monitor_cluster_cookie' rabbitmq:3.8.3-management
-
在192.168.102.12上创建容器rabbit3
$ docker run -d --restart=unless-stopped --name rabbit3 -h rabbit3 -p 5672:5672 -p 15672:15672 -p 25672:25672 -p 4369:4369 -v /home/rabbitmq:/var/lib/rabbitmq:z -v /home/rabbitmq/hosts:/etc/hosts -e RABBITMQ_DEFAULT_USER=monitor -e RABBITMQ_DEFAULT_PASS=123456 -e RABBITMQ_ERLANG_COOKIE='monitor_cluster_cookie' rabbitmq:3.8.3-management
参数说明:
-
-d 表示容器后台运行
-
-h rabbit1 容器的主机名是rabbit1,容器内部的hostname
-
-v /home/rabbitmq:/var/lib/rabbitmq:z 将宿主机目录/home/rabbitmq挂载到容器的/var/lib/rabbitmq目录。z是一个标记,在selinux环境下使用
-
-e RABBITMQ_ERLANG_COOKIE='rabbit_cluster' 设置rabbitmq的cookie,该值可以任意设置,只需要三个容器保持一致即可
绑定集群
-
重置myrabbit1节点
$ docker exec -it myrabbitmq1 /bin/bash
$ rabbitmqctl stop_app && rabbitmqctl reset && rabbitmqctl start_app
-
加入myrabbit2节点到集群中
$ docker exec -it rabbit2 /bin/bash
$ rabbitmqctl stop_app && rabbitmqctl reset && rabbitmqctl join_cluster rabbit@rabbit1 && rabbitmqctl start_app
-
加入myrabbit3节点到集群中
$ docker exec -it rabbit3 /bin/bash
$ rabbitmqctl stop_app && rabbitmqctl reset && rabbitmqctl join_cluster rabbit@rabbit1 && rabbitmqctl start_app
查询集群状态
$ rabbitmqctl cluster_status
故障节点的处理
$ docker exec -it rabbit2 /bin/bash
$ rabbitmqctl stop_app
在一个正常的节点上移除一个异常的节点
$ docker exec -it rabbit1 /bin/bash
$ rabbitmqctl forget_cluster_node rabbit@rabbit2
haproxy.cfg配置信息如下:
vim /home/rabbitmq/haproxy-etc/haproxy.cfg
#Simple configuration for an HTTP proxy listening on port 80 on all # interfaces and forwarding requests to a single backend "servers" with a # single server "server1" listening on 127.0.0.1:8000 global daemon maxconn 256 defaults mode http timeout connect 5000ms timeout client 5000ms timeout server 5000ms listen rabbitmq_cluster bind 0.0.0.0:5677 option tcplog mode tcp balance leastconn server rabbit1 rabbit1:5672 check inter 2s rise 2 fall 3 server rabbit2 rabbit2:5672 check inter 2s rise 2 fall 3 server rabbit3 rabbit3:5672 check inter 2s rise 2 fall 3 listen http_front bind 0.0.0.0:8002 stats uri /haproxy?stats listen rabbitmq_admin bind 0.0.0.0:8001 mode tcp balance leastconn server rabbit1 rabbit1:15672 check inter 2s rise 2 fall 3 server rabbit2 rabbit2:15672 check inter 2s rise 2 fall 3 server rabbit3 rabbit3:15672 check inter 2s rise 2 fall 3
启动haproxy
docker run -d --name rabbitmq-haproxy
--restart=unless-stopped -p 8002:8002 -p 5677:5677 -p 8001:8001 -v /home/rabbitmq/hosts:/etc/hosts -v /home/rabbitmq/haproxy-etc:/usr/local/etc/haproxy:ro haproxy:latest
集群模式
普通模式
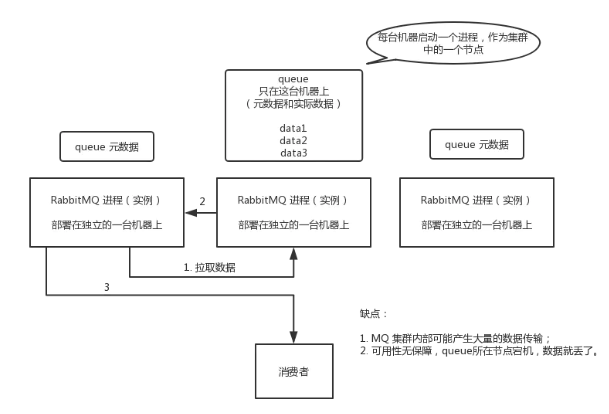
基本特征
-
交换机和队列的元数据存在于所有的节点上
-
队列中的完整数据只存在于创建该队列的节点上
-
其他节点只保存队列的元数据信息以及指向当前队列的owner node的指针
数据消费
进行数据消费时随机连接到一个节点,当队列不是当前节点创建的时候,需要有一个从创建队列的实例拉取队列数据的开销。此外由于需要固定从单实例获取数据,因此会出现单实例的瓶颈。
优点
可以由多个节点消费单个队列的数据,提高了吞吐量
缺点
-
节点实例需要拉取数据,因此集群内部存在大量的数据传输
-
可用性保障低,一旦创建队列的节点宕机,只有等到该节点恢复其他节点才能继续消费消息
示意图
镜像模式
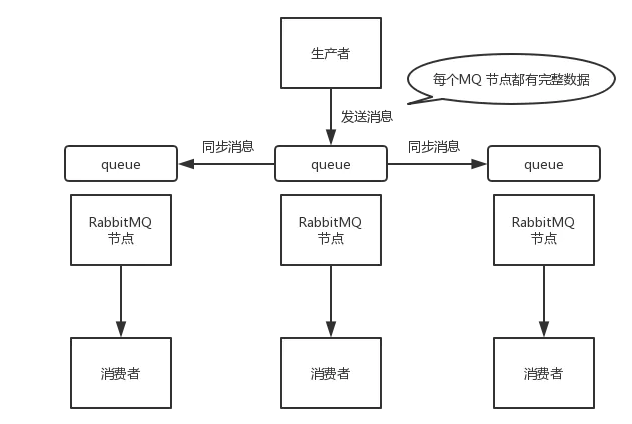
基本特征
-
创建的queue,不论是元数据还是完整数据都会在每一个节点上保存一份
-
向queue中写消息时,都会自动同步到每一个节点上
优点
-
保障了集群的高可用
-
配置方便,只需要在后台配置相应的策略,就可以将指定数据同步到指定的节点或者全部节点
缺点
-
性能开销较大,网络带宽压力和消耗很严重
-
无法线性扩展,例如单个queue的数据量很大,每台机器都要存储同样大量的数据
示意图
策略配置
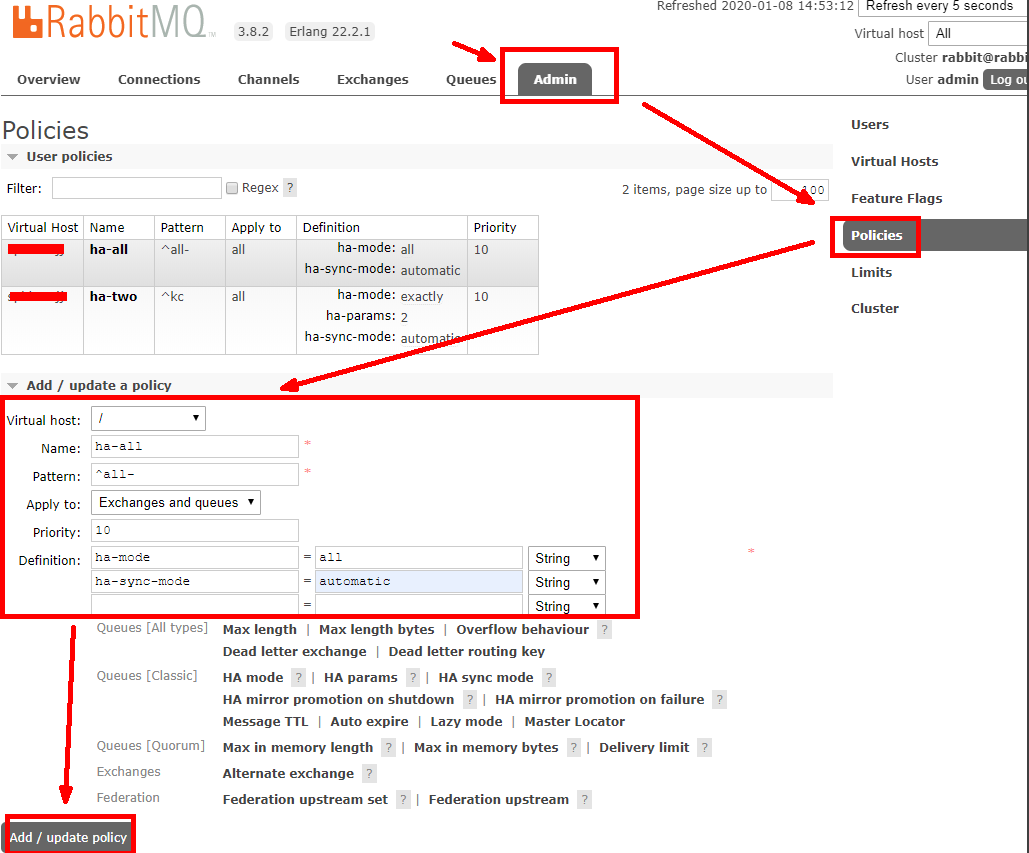
全部节点镜像策略创建
指定节点数镜像策略创建
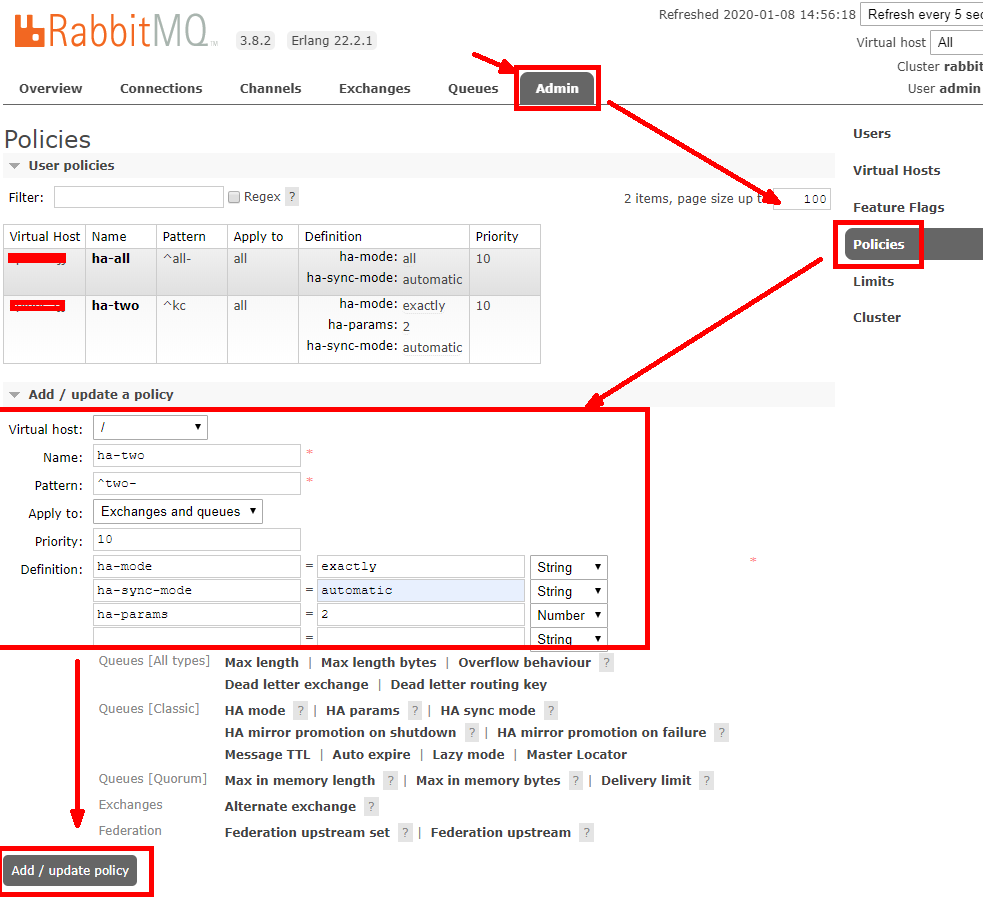
参数说明:
-
Pattern 模式:""为全部;"all-"为所有all-开头
-
Priority 优先级:建议10,比较耗费资源
-
Definition 定义参数:
ha-mode=all 或 exactly;
ha-sync-mode=automatic;
ha-params=2(ha-mode=exactly);
总结
综上所述,对于可靠性要求比较高的场合,推荐使用镜像模式。