前一阵被师妹问维生素论文里的特征选择,Fisher score和Laplacian score两种方法一直也没讲。于是趁把第四篇论文刚投完,马上把这个总结一下。
Fisher特征选择的主要思想是,认为鉴别性能强的特征的表现是类内部样本点的距离尽可能小,类之间的距离尽量大。
假设数据中有n个样本属于C个类别(忽然觉得这个不是我师兄反复强调的多标签分类问题吗- -),每个类分别包含ni个样本,mik表示第i类样本的取值,单个特征的Fisher准则表示为:
Jfisher(k)=SB/SW
其中,k表示第k维,SB,SW表示第k维特征在训练样本集上的类间方差和类内方差。(之前本博客笔误写错了,这里目前改过来了)
这样我们就可以判断出类别区分度好的特征(区分度越好fisher值越大)。
参考文献: 基于Fisher准则和特征聚类的特征选择 ,《计算机应用》 2007年11期
---------------------------------------------------------------------------------------------------
下面是Laplacian得分的判别法总结。
Laplacian score 算法是fisher score的推广,优先选择权重比较小的那些。
第一步,用所有数据建图:
如果xi和xj是一类,或者是K近邻,则xi和xj相连。
第二步,计算Sij。相邻的点使用下面公式计算:
Sij = exp(- ||xi - xj||2 / t),其中t为给定的宽度,一般为1
第三步,使用谱图理论的对角矩阵D来估计(下图是推导过程)
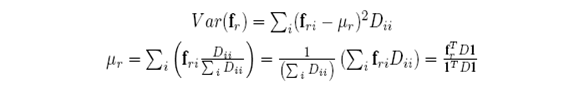
因为大家都知道,拉普拉斯矩阵的公式:L=D-S,则fr = fr - frTD1 / (1TD1) 1
第四步,
对于每个特征的拉普拉斯矩阵,有
Lr=frTLfr/(frTDfr)
参考博客来自:http://www.cnblogs.com/chend926/articles/2511666.html
---------------------------------------------------------------------------------------------------
其他的特征选择方法,包裹器方法如启发式搜索,嵌入式方法如决策树。