sed的N,D,P 是用于多行模式空间的命令,分别对应于n,d,p
n & N: n(next)输出模式空间的内容,然后读取新的输入行,n命令不创建多行模式空间;N(Next)通过读取新的输入行,并将它添加到模式空间的现有内容之后来创建多行模式空间。
注:在模式空间中嵌入的换行符可以利用转移序列" " 来匹配,在多行模式空间中"^"匹配空间中的第一个字条,而不匹配换行符后面的字符,同样"$"只匹配模式空间最后的换行符。
d & D: d删除模式空间的内容并导致读入新的输入行,并且在脚本顶端重新使用编辑方法。D删除模式空间中直到第一个嵌入的换行符的这部分内容,D不会导致读入新的输入行并且它返回到脚本的顶端,将这些指令应用于模式空间的剩余内容。例如:
cat test a b c sed -n '/^a/{ P N
p /a/D p
}' test
输出: a
a
b
解释:test是一个三行的文本(a,b,c);sed匹配首字母是a的行/^a/(模式空间:a);P打印出来模式空间中直到第一个嵌入的换行符的部分(a);然后用N向模式空间中追加一行(模式空间:a b);p打印出来模式空间的内容(a,b);接着如果模式空间中匹配到了a(/a/),D命令删除模式空间中直到第一个嵌入的换行符的这部分内容(模式空间:b),并且返回脚本顶部,将这些命令用于模式空间剩余内容(b);但是模式空间中并没有匹配到/^a/,所以没有后续输出了。
p & P : p 打印模式空间内容;P打印模式空间中知道第一个嵌入的换行符的部分。
P命令经常在N之后和D之前。N D P能建立一个输入/输出循环,用来维护两行的模式空间,但是一次只输出一行。这个循环的目的是只输出模式空间的第一行,然后删除(D)模式空间第一行,然后返回到脚本的顶端将所有的命令应用于模式空间的第二行。
sed & awk 例:P125
创建模式空间以匹配第一行结尾处的"UNIX"和第二行开始出的"System"。如果发现"UNIX System"跨越两行,那么我们将它变成"UNIX Operator System"。建立这个循环以返回到脚本的顶端,并寻找第二行结尾处的"UNIX"
脚本:sed.Print /UNIX$/{ N s/ System/ Operating &/ P D }
测试脚本 test.Print
Here are examples of the UNIX
System. Where UNIX
System appears, it should be the UNIX
Operating System
sed -f sed.Print test.Print
输出:
Here are examples of the UNIX Operating
System. Where UNIX Operating
System appears, it should be the UNIX
Operating System
指令执行的顺序图见下:
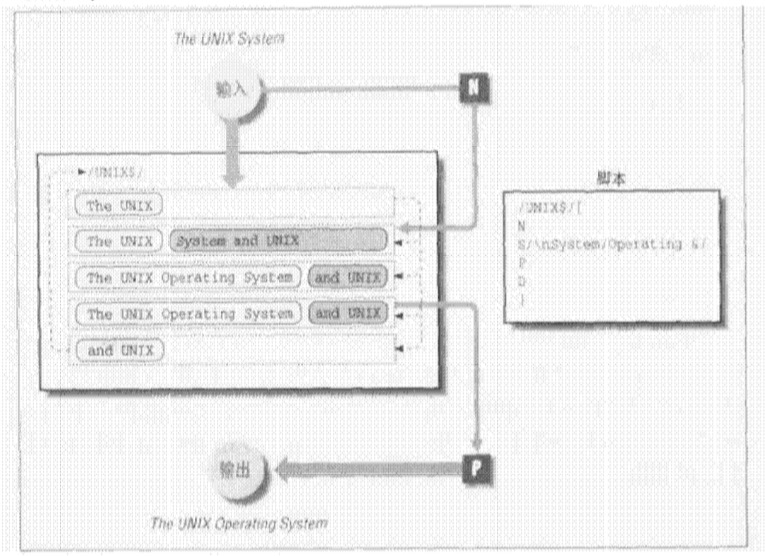
输入/输出循环让我们可以匹配出在第二行结束处出现的UNIX。如果正常输出两行的模式空间,那么就不能匹配出第二行结尾处的UNIX。
sed -n '/UNIX$/{ N s/ System/ Operating &/ p }' test.Print 输出: Here are examples of the UNIX Operating System. Where UNIX System appears, it should be the UNIX Operating System
可见,如果没有用D,则在追加了第二行,并且进行替换打印(p)模式空间后,就继续处理第三行了,并没有对第二行进行匹配替换。
所以,N命令追加下一行,P打印出第一行,D删除第一行并且跳到脚本顶部,并将脚本命令作用于模式空间剩下内容;N命令追加下一行,P打印出第一行,D删除第一行……