Kafka 是一个高吞吐、分布式、基于发布订阅的消息系统,利用Kafka技术可在廉价PC Server上搭建起大规模消息系统。Kafka具有消息持久化、高吞吐、分布式、多客户端支持、实时等特性,适用于离线和在线的消息消费
Kakfa特点:
- 解耦:消息系统在处理过程中插入一个隐含、基于数据的接口层。
- 冗余:消息队列持久化,防止数据丢失。
- 扩展性:消息队列解耦处理过程,容易扩展处理过程。
- 可恢复性:处理过程失效,恢复后可继续处理。
- 顺序保证:消息队列保证顺序。Kafka保证一个Partition内消息有序。
- 异步通信:消息队列允许消息加入队列,等需要时再处理。
Kafka 的术语
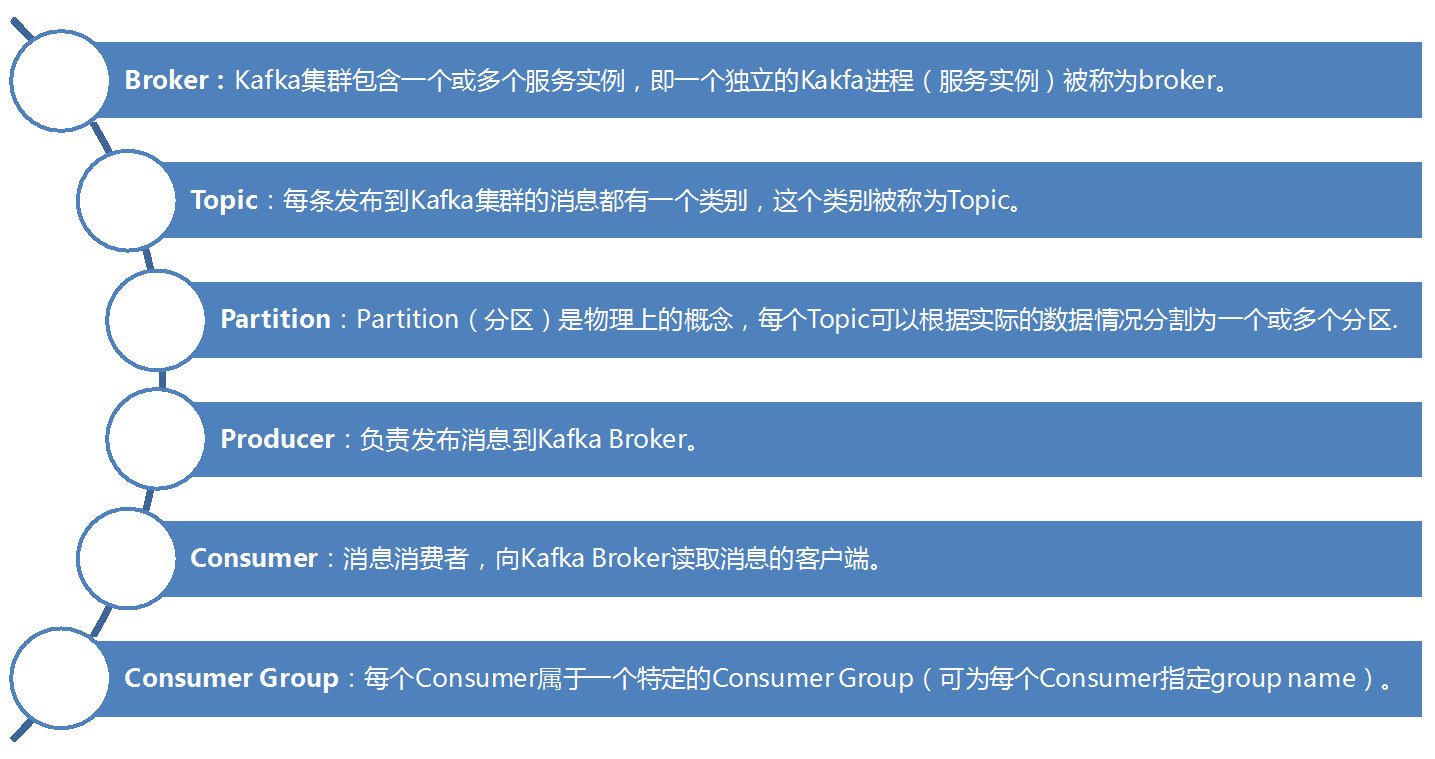
Kafka 架构
典型Kafka架构
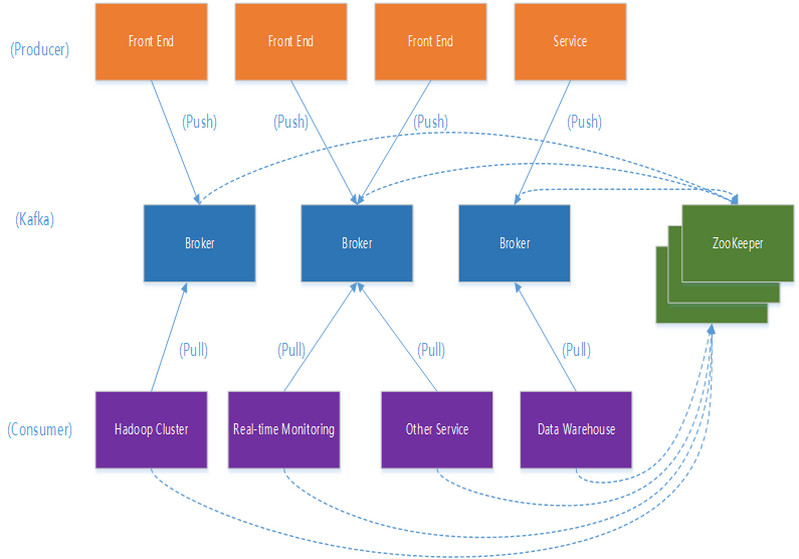
一个典型的Kafka集群中包含若干Producer(可以是web前端应用产生的消息,也可以是类似通过上网Flume收集上网日志产生的Events等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置及服务协同。Producer使用push模式将消息发布到broker,Consumer通过监听使用pull模式从broker订阅并消费消息。
多个broker协同合作,producer和consumer部署在各个业务逻辑中被频繁的调用,三者通过zookeeper管理协调请求和转发。这样一个高性能的分布式消息发布和订阅系统就完成了。图上有个细节需要注意,producer刡broker的过程是push,也就是有数据就推送给broker,而consumer给broker的过程是pull,是通过consumer主动去拉数据的,而不是broker把数据主动发送给consumer端的。
producer、consumer、broker以及zookeeper返四者的关系
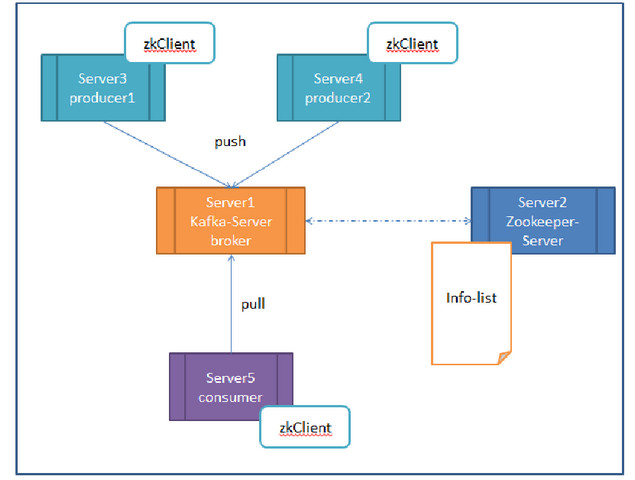
我们看上面的图,我们把broker的数量减少,叧有一台。现在假设我们按照上图进行部署:
Server-1 broker其实就是kafka的server,因为producer和consumer都要去连它。Broker主要还是做存储用。
Server-2是zookeeper的server端,zookeeper的具体作用你可以去上网查,在这里你可以先想象,它维持了一张表,记录了各个节点的IP、端口等信息(以后还会讲到,它里面还存了kafka的相关信息)。
Server-3、4、5他们的共同之处就是都配置了zkClient,更明确的说,就是运行前必须配置zookeeper的地址,道理也很简单,这之间的连接都是需要zookeeper来进行分发的。
Server-1和Server-2的关系,他们可以放在一台机器上,也可以分开放,zookeeper也可以配集群。目的是防止某一台挂了。
简单说下整个系统运行的顺序:
1. 启动zookeeper的server
2. 启动kafka的server
3. Producer如果生产了数据,会先通过zookeeper找到broker,然后将数据存放进broker
4. Consumer如果要消费数据,会先通过zookeeper找对应的broker,然后消费。