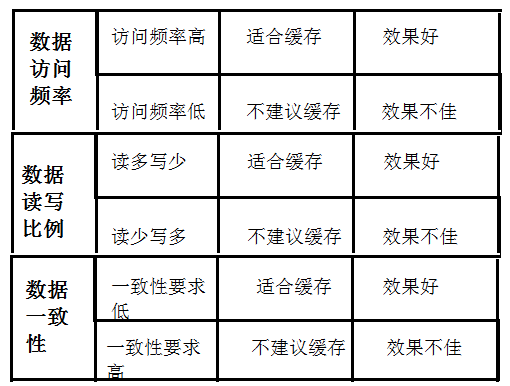
一.什么样的数据适合缓存
二.缓存策略一些问题应对总结
(1).缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,造成缓存穿透。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
应对方案:
- 如果对应在数据库中的数据都不存在,我们将此key对应的value设置为一个默认的值,比如“NULL”,并设置一个缓存的失效时间。当然这个key的时效比正常的时效要小的多
- 采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层数据库的查询压力。
(2).缓存雪崩
缓存雪崩是指在设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,导致所有的查询都落在数据库上,造成了缓存雪崩。
应对方案:
1.将系统中key的缓存失效时间均匀地错开,防止统一时间点有大量的key对应的缓存失效。比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
2.建立备份缓存,缓存A和缓存B,A设置超时时间,B不设值超时时间,先从A读缓存,A没有读B,并且更新A缓存和B缓存。
3.在固定的缓存时间上加上随机时间长度,比如固定缓存5分钟加上随机的1到3分钟不等,在一定程度上可以避免缓存雪崩。
(3).缓存击穿
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
应对方案:
1.双缓存策略
2.缓存永远不过期
这里的“永远不过期”包含两层意思:
(1) 从缓存上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
(2) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期.