C++标准特性问题
关于花括号的构造问题
class Base {};
Base b1 = {}; // 隐式构造
Base b2{}; // 显式构造
Base b3(); // 声明函数
隐式转换

第一行代码显式构造
第二行代码用到了两个隐式转换,先转换成double,再转换成Fraction
第三行代码用到了一个隐式转换,转换成Fraction
initializer_list的作用是什么
第一是统一,第二是方便
统一
统一了类(结构体),数组(包含STL中的容器,虽然说它们也是类),POD三者的初始化方式。对于前两者来说,只需要在类内部实现一个参数为initializer_list的构造函数即可
class MyClass {
public:
MyClass(const std::initializer_list<int>& iList) {}
};
// 以下三种都是隐式构造 只调用一次构造函数
MyClass m2 = { 1, 2, 3 };
map<int, string> m = { {1, "11"}, {2, "22"} };
vector<int> v1 = { 1, 2, 3, 4 };
vector<int> v2{ 1, 2 };
int arr[] = { 1, 2 ,3 ,4 ,5 }; // 可以不指明大小
对于类(结构体)和POD类型
class A_Class
{
private:
int data;
bool isDone;
public:
A_Class(int _data, bool _isDone) : data(_data), isDone(_isDone) {}
};
struct B_POD
{
int data;
bool isDone;
};
A_Class a{ 1, false };
B_POD b{ 2, true };
// 没有提供有参构造函数 错误
// B_POD b(2, true);
POD:Plain Old Data,指没有构造函数,析构函数和虚函数的类或结构体
方便
对于容器,数组类型,可以直接用初始化列表进行初始化,十分方便
函数模板
C++98和C++11中函数模板的区别

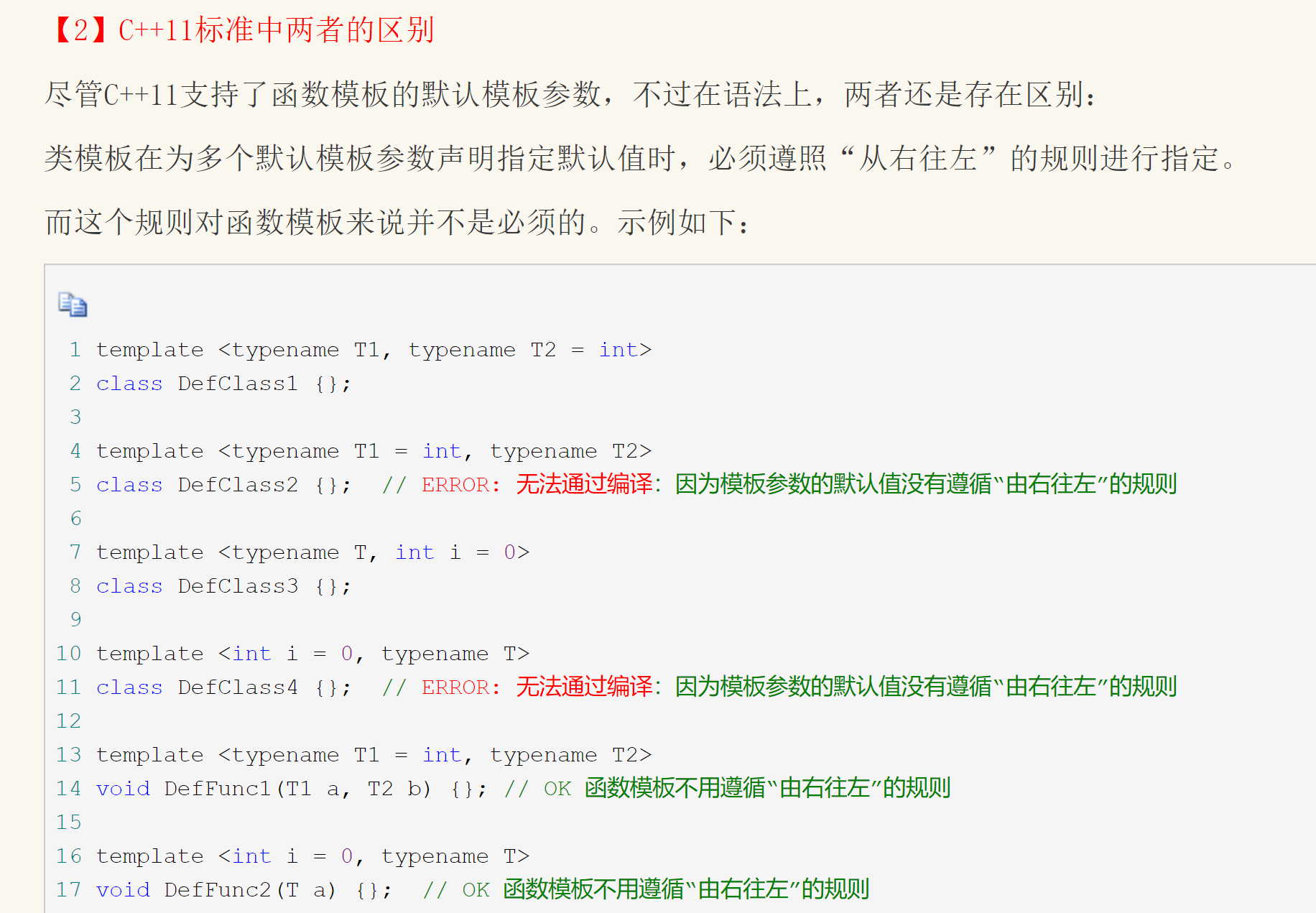
如果泛型函数有参数,那么它可以通过参数来推断出模板类型,不需要显式指定。(显式指定优先级大于参数)
函数模板只有全特化,没有偏特化
如何实现函数模板的偏特化,相关连接:https://zhuanlan.zhihu.com/p/268600376
现有i++还是先有++i
// 前置++
ListNodeIterator& operator++()
{
node = node->nextNode;
return *this;
}
// 后置++
ListNodeIterator operator++(int)
{
// 调用到拷贝构造函数 进行一次默认的浅拷贝 故需要自行书写拷贝构造函数 同时该拷贝构造函数不能为explicit
ListNodeIterator temp = *this;
// ListNodeIterator temp(*this); // 两种写法
operator++();
// ++(*this); // 两种写法
return temp;
}
从这种写法来看的话应该是先有++i,并且++i的开销更小,不需要构建一个临时变量。所以在for循环里头一般写++i
如何new一个对象,new一个对象的数组,new一个对象的指针数组
基础不牢 地动山摇
数组
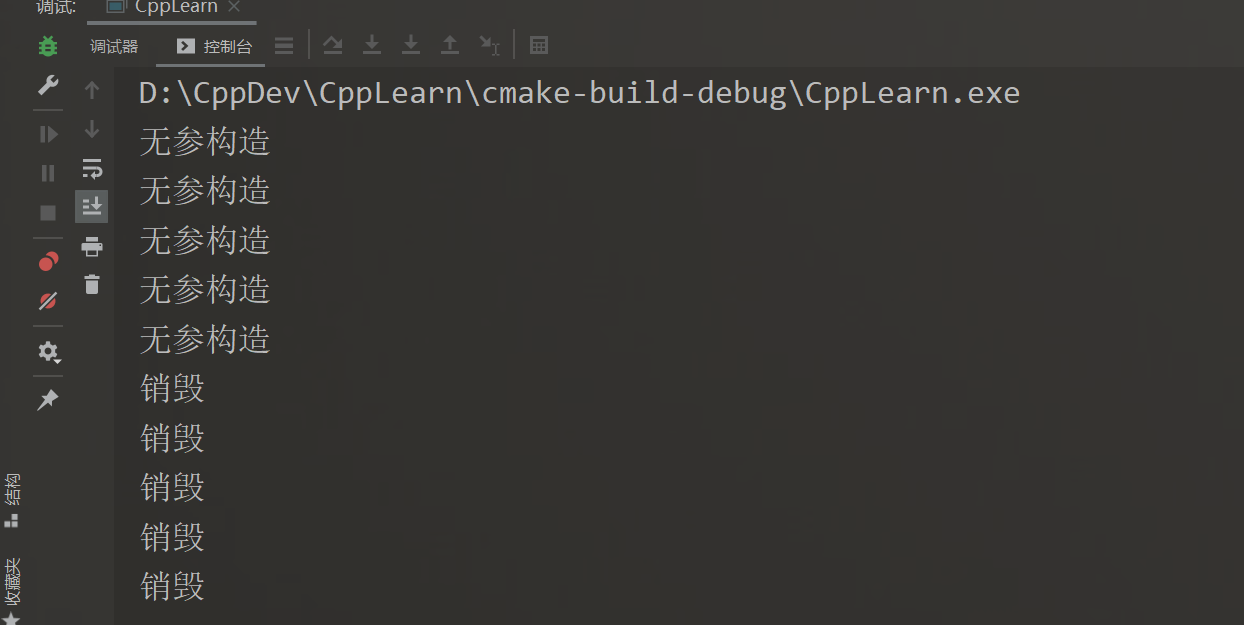
问下列代码会输出什么
class TreeNode
{
public:
int data;
TreeNode() { cout << "无参构造" << endl; }
TreeNode(int _data) : data(_data) { cout << "有参构造" << endl; }
~TreeNode() { cout << "销毁" << endl; }
};
int main()
{
TreeNode nodes[5];
return 0;
}
公布答案
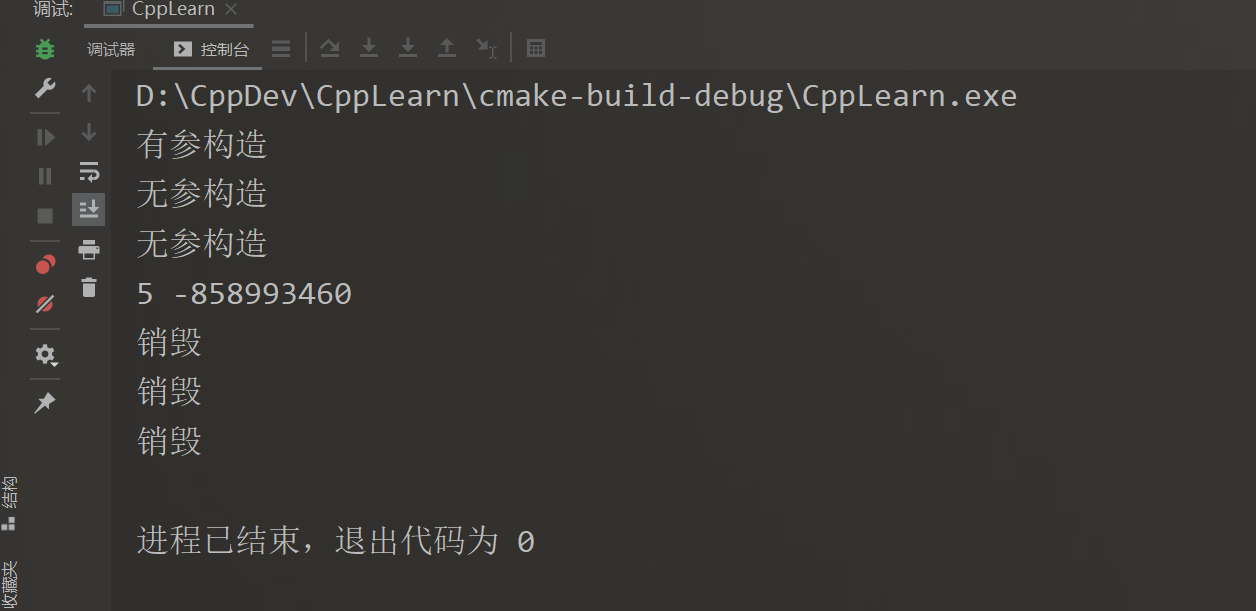
再来看这种
TreeNode nodes[3] { TreeNode(5) };
cout << nodes[0].data << ends;
cout << nodes[1].data << endl;
nodes数组的构造方式为:显式调用拷贝构造函数,然后隐式调用两次默认构造函数。也就是说如果默认构造函数是显式的(explicit),那么上述花括号构造不能通过编译
指针数组 - 记录指针的数组
再问,保持类不变,下列代码会输出什么
// 在栈上创建了一个指针数组 因为没有初始化 所以数组中的每个元素都是野指针
TreeNode* pNodes[20];
答案是没有输出,上述声明了一个指针数组。指针数组就是一个存了n个指针的数组
下方代码示范指针数组的初始化
// 将20个元素都初始化为空指针
TreeNode* pNodes[20] {};
// 访问空指针 非法 程序异常
cout << pNodes[0]->data << endl;
下方代码构建了指针数组的第一个元素,然后将剩下的19个元素置为nullptr
TreeNode element(10);
TreeNode* pNodes[20] { &element };
// 输出10
cout << pNodes[0]->data << endl;
下面演示一下在栈上的指针数组,且每一项指针都指向堆上的资源
// 两个函数等价 都被编译器解释为二级指针类型
void TestPassPP(TreeNode** t) {}
void TestPassPA(TreeNode* t[]) {}
TreeNode* pNodes[5];
for (auto& node : pNodes)
node = new TreeNode(10);
// 输出10
cout << pNodes[0]->data;
// 测试函数参数传递
TestPassPP(pNodes);
TestPassPA(pNodes);
// 释放资源
for (auto& node : pNodes)
delete node;
个人觉得这种写法虽然能通过编译,但是并无实际用途,甚至可以说是一种错误的写法,比如下方代码
TreeNode** Create1DPointerArrayOnStack()
{
TreeNode* pNodes[5];
for (auto& node : pNodes)
node = new TreeNode(10);
// 退化成二级指针 外界无法知道这个指针数组里头有多少个元素
return pNodes;
}
TreeNode** p = Create1DPointerArrayOnStack();
// 仍然能访问
cout << p[0]->data << ends;
// 栈指针偏移 数据丢失
cout << p[0]->data << endl;
// 此时已经无法找到对应的指针可以delete
虽然指针数组中的指针指向的是在堆上的资源,但是函数返回的是一个二级指针(数组指针),且该这个数组本身是在栈上的,自然而然地程序也会出错
现在再演示如何在堆上创建指针数组(数组本身在堆上),因为new操作返回的是指针,所以需要一个数组指针来承接
// 数组指针p2pNode 指向一个指针数组
TreeNode** p2pNodes = new TreeNode*[5];
for (int i = 0; i < 5; i++)
p2pNodes[i] = new TreeNode(10);
// 输出10
cout << p2pNodes[3]->data << endl;
// 销毁
for (int i = 0; i < 5; i++)
delete p2pNodes[i];
delete[] p2pNodes;
用法示例
TreeNode** Create1DPointerArrayOnHeap(int size, int value)
{
TreeNode** p2pNodes = new TreeNode*[size];
for (int i = 0; i < size; i++)
p2pNodes[i] = new TreeNode(value);
return p2pNodes;
}
TreeNode** p = Create1DPointerArrayOnHeap(5, 10);
// 输出10
cout << p[2]->data << endl;
// 手动销毁
for (int i = 0; i < 5; i++)
delete p[i];
delete[] p;
众所周知,一个二级指针可以表示一个1维的指针数组,也可以表示一个2维的普通数组,请看下方代码,注意,因为无参构造函数中没有初始化数据,所以输出的将会是不确定的int值
TreeNode** p2pNodes2D = new TreeNode*[5];
// 拓展到第二维度 含有10个元素
for (int i = 0; i < 5; i++)
p2pNodes2D[i] = new TreeNode[10];
// 访问第0行第0列的元素 利用指针访问 可通过++操作遍历列元素
cout << p2pNodes2D[0]->data << ends;
// 访问第0行第1列的元素
cout << p2pNodes2D[0][1].data << endl;
// 销毁
for (int i = 0; i < 5; i++)
delete[] p2pNodes2D[i];
delete[] p2pNodes2D;
下面介绍另外一种创建二维普通数组的方法,这种需要提前确定第2维度的大小(本例中是10)。测试输出的仍然是不确定的int值
// 已知第二维 类型为TreeNode (*)[10]TreeNode (*pNodes2D)[10] = new TreeNode[5][10];// 访问第1行第0列的元素cout << pNodes2D[1]->data << ends;// 访问第2行数组的第3列的元素cout << pNodes2D[2][3].data << endl;// 销毁delete[] pNodes2D;
pNodes2D的类型是TreeNode (*)[10],该类型不能退化为二级指针类型
// 都需要显式指定第二维度为10
void TestPassPA(TreeNode (*t)[10]) {}
void TestPassAA(TreeNode t[][10]) {}
using TreeNodeArrayPointer2D = TreeNode[10];
TreeNodeArrayPointer2D* CreateTest()
{
TreeNode (*pNodes2D)[10] = new TreeNode[5][10];
TestPassPA(pNodes2D);
TestPassAA(pNodes2D);
// 省略外部调用的delete[]操作
return pNodes2D;
}
结论
- 一维指针数组可以退化为二级指针
- 二维数组指针不能正常转换为二级指针
- 二级指针无法正常转换为以上两种类型
拓展:上文中p2pNodes2D中的每个元素都是TreeNode类型,且在构建的时候使用的是无参构造函数,若要使用有参构造,那么需要使用到列表初始化
p2pNodes2D[i] = new TreeNode[10] {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
这种写法是比较麻烦的,又或者说我想创建一个二维的数组指针应该怎么写呢?
// 5 * 6 的二维指针数组
TreeNode*** p2pNodes2DParamInit = new TreeNode**[5];
for (int i = 0; i < 5; i++)
{
p2pNodes2DParamInit[i] = new TreeNode*[6];
for (int j = 0; j < 6; j++)
p2pNodes2DParamInit[i][j] = new TreeNode(j);
}
// 输出5
cout << p2pNodes2DParamInit[4][5]->data << endl;
// 销毁
for (int i = 0; i < 5; i++)
{
for (int j = 0; j < 6; j++)
delete p2pNodes2DParamInit[i][j];
delete[] p2pNodes2DParamInit[i];
}
delete[] p2pNodes2DParamInit;
数组指针 - 指向数组的指针
问:下列代码会输出什么
TreeNode* pNode = new TreeNode[20];
// delete[] pNode;
答案是会输出20次无参构造,没有输出销毁,因为delete[]被注释掉了
如果是这样呢
TreeNode* pNode = new TreeNode[20];delete pNode;
会输出20次无参构造,一次销毁,然后程序报错。所以说明new[]和delete[]要搭配使用
那么这个数组中存的是什么类型呢
auto node = pNode[5];
存的是TreeNode类型,并且下列代码会输出一个不确定的值,因为没有初始化(C#中则会默认初始化为0,C++中不会)
cout << pNode[5].data << endl;
// 头元素调用有参构造函数 其他元素隐式调用无参构造函数
TreeNode* pNode = new TreeNode[20] {10};
// 输出数组的头元素 输出10
cout << pNode->data;
delete[] pNode;
上文中创建了在堆上的数组,下文演示在栈上的数组指针
// 创建一个数组以供赋值
TreeNode arr[20];
TreeNode* pArr = arr;
pArr[0].data = 100;
// 两者都是输出100
cout << pArr->data << endl;
cout << pArr[0].data << endl;
// 输出不确定的值 因为在++操作后指针指向的是第1个元素 它的data没有被初始化
cout << (++pArr)->data << endl;
再来看看在栈上的指向二维数组的指针
TreeNode arr2D[10][20];
TreeNode (*p)[20] = arr2D;
来看看内置类型的初始化
int intArr[20];
cout << intArr[5] << ends;
int intArrInit[20] {};
cout << intArrInit[5] << endl;
int* p2IntArr = new int[20];
cout << p2IntArr[5] << ends;
int** p2pIntArr = new int*[20];
cout << p2IntArr[5] << ends;
int* pIntArrInit = new int[20] {10, 100};
cout << pIntArrInit[1] << ends;
cout << pIntArrInit[5] << endl;
小测验
TreeNode* pArr[5]; // 一个数组 存的是指针
TreeNode* pArrInitNull[5] {}; // 一个数组 存的是指针 且指针都初始化为nullptr
TreeNode (*p2Arr)[5]; // 一个指针 指向一个第二维度大小为5的存放TreeNode的二维数组
TreeNode* (*p2pArr)[10]; // 一个指针 指向一个第二维度大小为10的存放TreeNode*的二维数组
TreeNode* nodesOnHeap = new TreeNode[20]; // 指向一个堆上的数组的数组指针
TreeNode** pNodesOnHeap = new TreeNode*[20]; // 指向一个堆上的指针数组的数组指针
TreeNode nodes2DArray[10][20]; // 二维数组
TreeNode* pArr1D = nodes2DArray[0]; // 指向一维数组的指针
TreeNode (*pArr2DLimit)[20] = nodes2DArray; // 指向二维数组且第二个维度为20的指针
TreeNode** pArr2DUnLimit = nodes2DArray; // 编译不通过 李在赣神魔?
TreeNode* pNodes2DArray[10][20]; // 二维指针数组
TreeNode** pArr1D = pNodes2DArray[0]; // 数组指针 指向的是存放指针的一维数组
TreeNode* (*pArr2DLimit)[20] = pNodes2DArray; // TreeNode* (*)[20] 类型的指针
using PointerTreeNode20 = TreeNode*[20];
PointerTreeNode20* simpleWay = pNodes2DArray; // C++11
题外话
参数传递数组
void GetArraySize(int (&arr)[10]) { cout << sizeof(arr) << endl; }
int a[10];
// 输出40
putValues(a);
使用vector构建二维数组
class TestClass
{
public:
int data = 10;
TestClass() { cout << "无参构造" << endl; }
TestClass(const TestClass& copy) { cout << "拷贝构造函数" << endl; }
~TestClass() { cout << "销毁" << endl; }
};
// 会额外产生1 + 3个临时对象
vector<vector<TestClass>> vec(2, vector<TestClass>(3, TestClass()));
// 调用了1次无参构造和3 + 2 * 3次拷贝构造
// 调用了10次销毁
使用vector和share_ptr构建二维指针数组
vector<vector<shared_ptr<TestClass>>> array2D(4, vector<shared_ptr<TestClass>>(6, make_shared<TestClass>()));
cout << array2D[0][0]->data << endl;
array2D[0][0]->data = 100;
cout << array2D[0][0]->data << endl;
cout << array2D[0][1]->data << endl;

所以以上的构建方式是错误的,整个数组中存放的都是指向同一份资源的指针,正确的创建方式是
// 24次构造和24次销毁vector<vector<shared_ptr<TestClass>>> vec2D(4, vector<shared_ptr<TestClass>>(6));for (auto& vec1D : vec2D) for (auto& ptr : vec1D) ptr = make_shared<TestClass>();vec2D[0][0]->data = 100;for (const auto& vec1D : vec2D){ for (const auto& ptr : vec1D) cout << ptr->data << ends; cout << endl;}
模板的分文件编写
range-base-loop中修饰符的使用
返回值为auto和decltype(auto)的函数有什么区别?
不单单是返回值的问题,首先应该理解auto可能会出现推导错误的情况(即丢失引用等信息),假设我们有以下三个方法
string name = "Mike";
string get_name() { return "Jelly"; }
string& get_name_reference() { return name; }
const string& get_name_const_reference() { return name; }
然后我们对其进行封装,然后检测auto推断的类型
auto package_get_name_reference() { return get_name_reference(); }
auto package_get_name_const_reference(){ return get_name_const_reference(); }
int main()
{
cout << boolalpha << is_same<decltype(package_get_name_reference()), string>::value << endl; // true
cout << boolalpha << is_same<decltype(package_get_name_const_reference()), string>::value << endl; // true
}
是的,单纯使用一个auto,引用或者const都被扔掉了,那应该怎么办呢
- 对于我们自己知道它是什么类型的,可以加上
&来“帮助”auto,让它推断出正确的类型 - 如果说想偷懒或者说无法知道返回值是什么类型的,可以使用
decltype(auto)
auto& package_get_name_reference() { return get_name_reference(); } // 推断为string&
auto& package_get_name_const_reference(){ return get_name_const_reference(); } // 推断为const string&
或者
decltype(auto) package_get_name_reference() { return get_name_reference(); } // 推断为string&
decltype(auto) package_get_name_const_reference(){ return get_name_const_reference(); } // 推断为const string&
在现代C++书籍中也有提到,当碰到复杂的模板等情况的时候,选择使用C++14新加入的decltype(auto)会更加方便
- 转发函数
- 封装的返回类型
- 复杂的模板
如何防止模板的重复实例化导致编译时间的增加
什么是模板的实例化
假设我们有一个hpp文件,里头定义并实现了一个泛型函数
// TestTemplate.hpp
template<typename T>
void TestExternTemplate(T data)
{
cout << typeid(T).name() << endl;
}
此时有一个cpp文件调用这个泛型函数
// Test1.cpp
#include "TestTemplate.hpp"
void Func1()
{
TestExternTemplate(10);
}
当单独编译这个文件的时候,编译器会在Test1.object中生成一个TestExternTemplate<int>的实例化
如果此时有一份别的cpp文件也要调用这个泛型函数
// Test2.cpp
#include "TestTemplate.hpp"
void Func2()
{
TestExternTemplate(1000);
}
那么编译之后在Test1.object和Test2.object中会有两份一摸一样的TestExternTemplate<int>的实例化代码。
虽然编译器可能会进行剔除操作来防止代码的重复,但是这仍然增加了编译和链接的时间
使用外部模板来防止重复实例化
使用extern来“查找”外部模板
// Test1.cpp
#include "TestTemplate.hpp"
template void TestExternTemplate(int);
void Func1()
{
TestExternTemplate(10);
}
// Test2.cpp
#include "TestTemplate.hpp"
extern template void TestExternTemplate<int>(int);
void Func2()
{
TestExternTemplate(1000);
}
STL的问题
OOP与GP

全局sort中使用的迭代器指针是要求支持随机访问的(RandomAccessIterator),也就是说该泛型指针支持++操作。而list是双向链表,每个节点在内存空间上的分布不是连续的,所以不支持使用全局的sort方法。
Malloc
malloc操作具有一定的开销,其申请的内存大小其实略大于程序员要求的大小,因为包含了一定大小的头部和尾部,成为Cookies,用来记录一些必要的信息。所以说,当程序员申请的内存空间非常小时,Cookies的占比就会非常的高。若程序员多次申请非常小的内存,例如一百万次,那么就会产生难以忍受的额外开销。解决这种问题的方法之一是内存池(一次性申请一大块,然后自己写一个类来分配)
所以假设容器中有一百万个小元素,那么使用相应的allocator取申请一百万次内存空间,且该allocator只是对malloc的简单包装,也就是说调用了一百万次malloc,那么效率会很低,导致总的Cookies占量非常高。
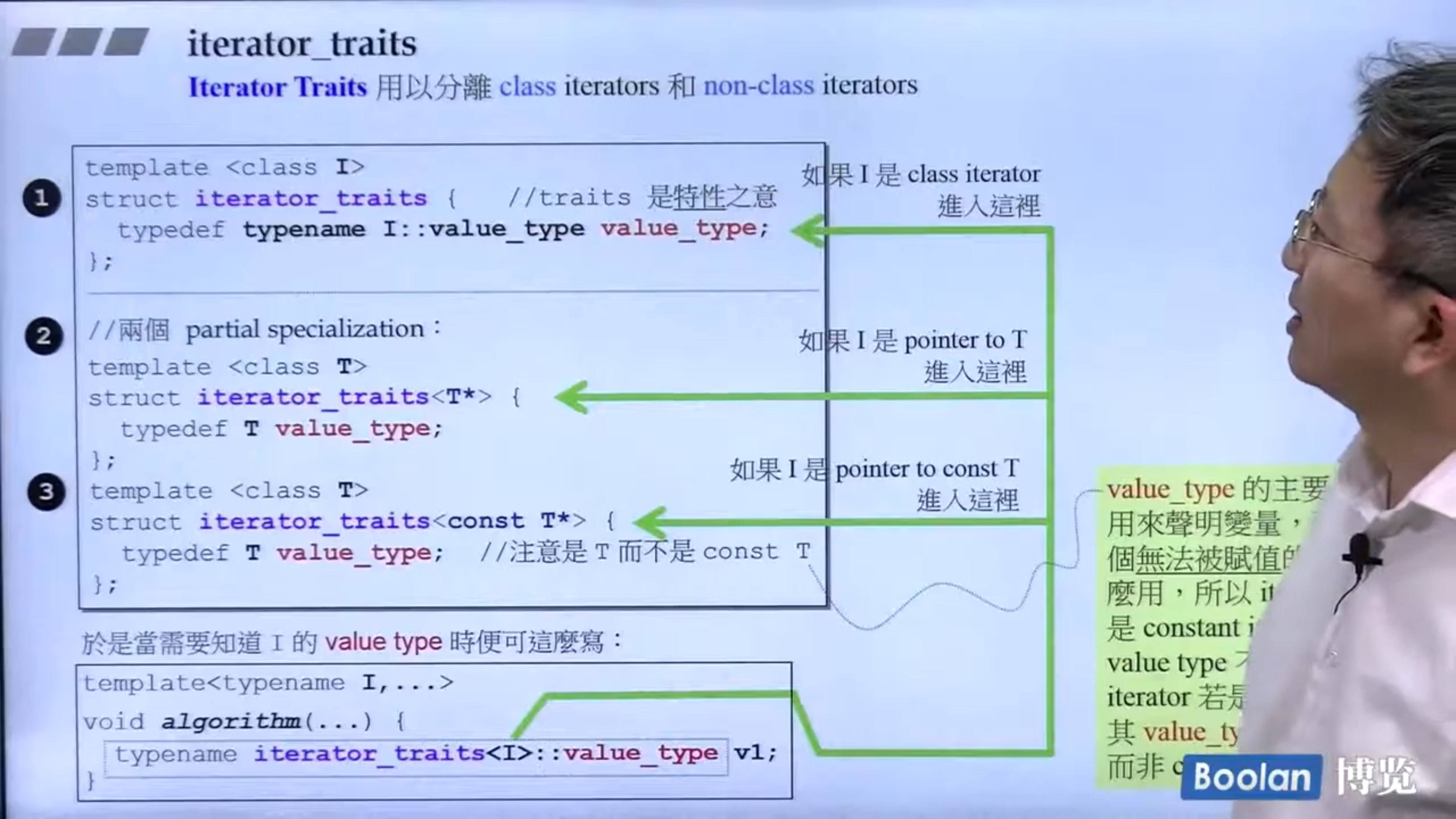
类型萃取
iterator_traits的简单机理实现
List相关问题
list的结构是怎么样的
list是一个双向循环链表

为什么list要使用循环链表
对于常规的数据结构来说,循环链表的优点是:不论从哪个节点切入,都能成功遍历整个链表,而对于STL,个人见解:为了节省空间。
以下是我在IDE中按F12扒来的源码,VS2019
// list standard header
_NODISCARD iterator begin() noexcept {
return iterator(_Mypair._Myval2._Myhead->_Next, _STD addressof(_Mypair._Myval2));
}
_NODISCARD iterator end() noexcept {
return iterator(_Mypair._Myval2._Myhead, _STD addressof(_Mypair._Myval2));
}
使用循环链表,不需要在类中存储额外的指针指向头和尾。STL将_Myhead指向“虚无”的尾节点,而获取头节点的操作则直接对Head取next即可
list的初始头节点指向哪里,和end指向同一块空间吗
因为begin和end操作都会构造一个iterator(其实这里的iterator套了using之后的一种类型,暂且不深究)出来,从测试结果来看两者确实是相等的。
但是对于刚初始化时的_Myhead来说,它的next指向的是哪里呢?应该不是一个空类型,如果是的话,因为end的结果和begin相等,也就是说_Myhead也是个空类型,那么这个空类型是怎么获取到next的呢?本人暂时没有更深究list的源码,对这个问题并不清楚。
GCC2.9和GCC4.9中list的大小有什么区别,当前呢
从上面贴的list结构图里可以看出,GCC2.9中存的是一个指针,而指针指向的对象里头存放的是两个void类型的指针,一个是next一个是pre。不论是什么类型指针的大小都是4个字节。所以GCC2.9中list的大小是4
而GCC4.9中,通过一层一层的关系,放的其实是两个指针,所以GCC4.9中list的大小是8
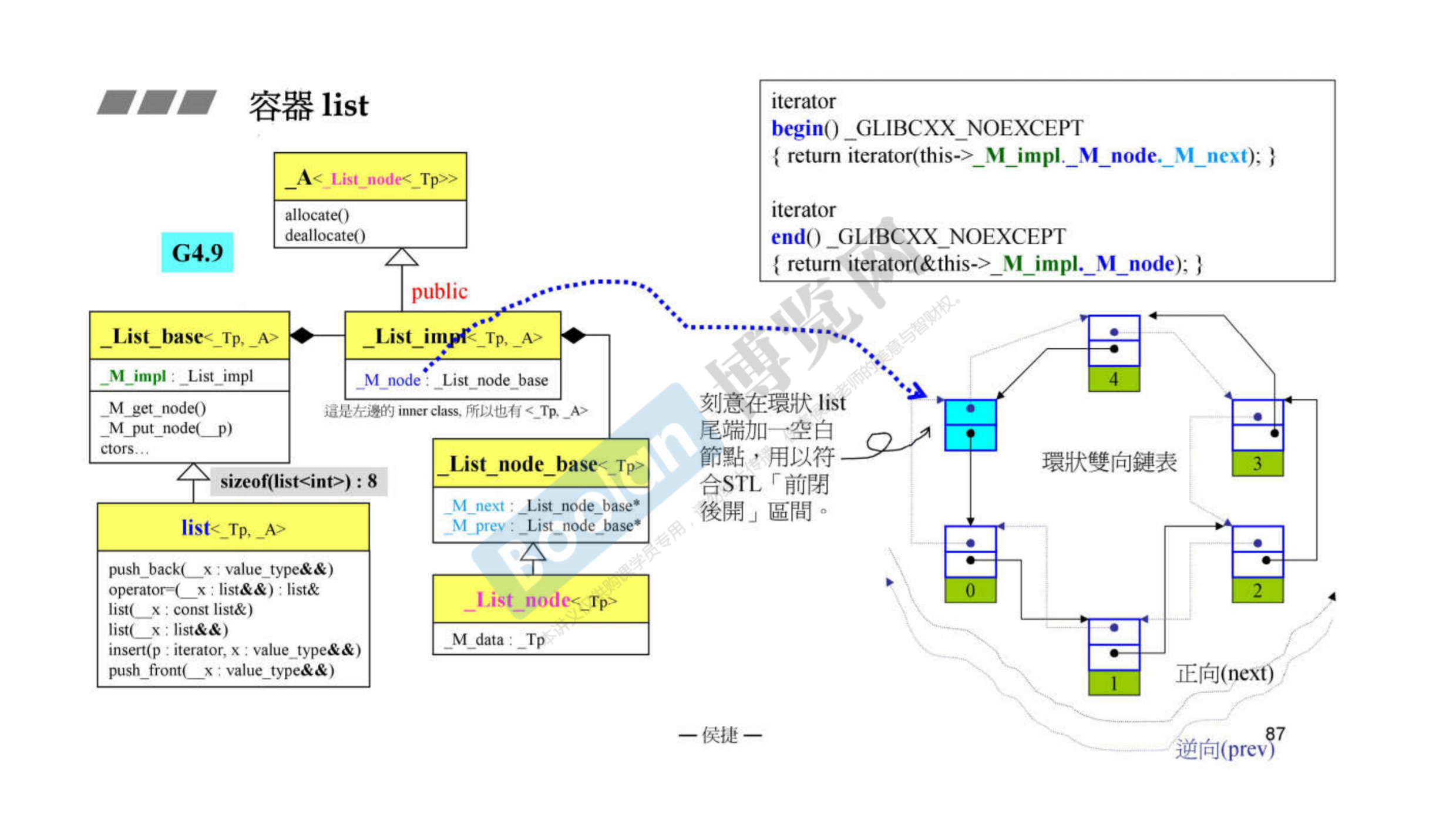
而我在当前的编辑器中对list进行sizeof操作,得到的结果是12
寄!
list和forward_list的end有什么区别
list的end指向的一个“虚无的”节点,也是整个循环链表的“头”,而forward_list指向的end可以看作是一个指向新建的空节点的iterator,与链表本身并无关系。forward_list是一个线形单向链表
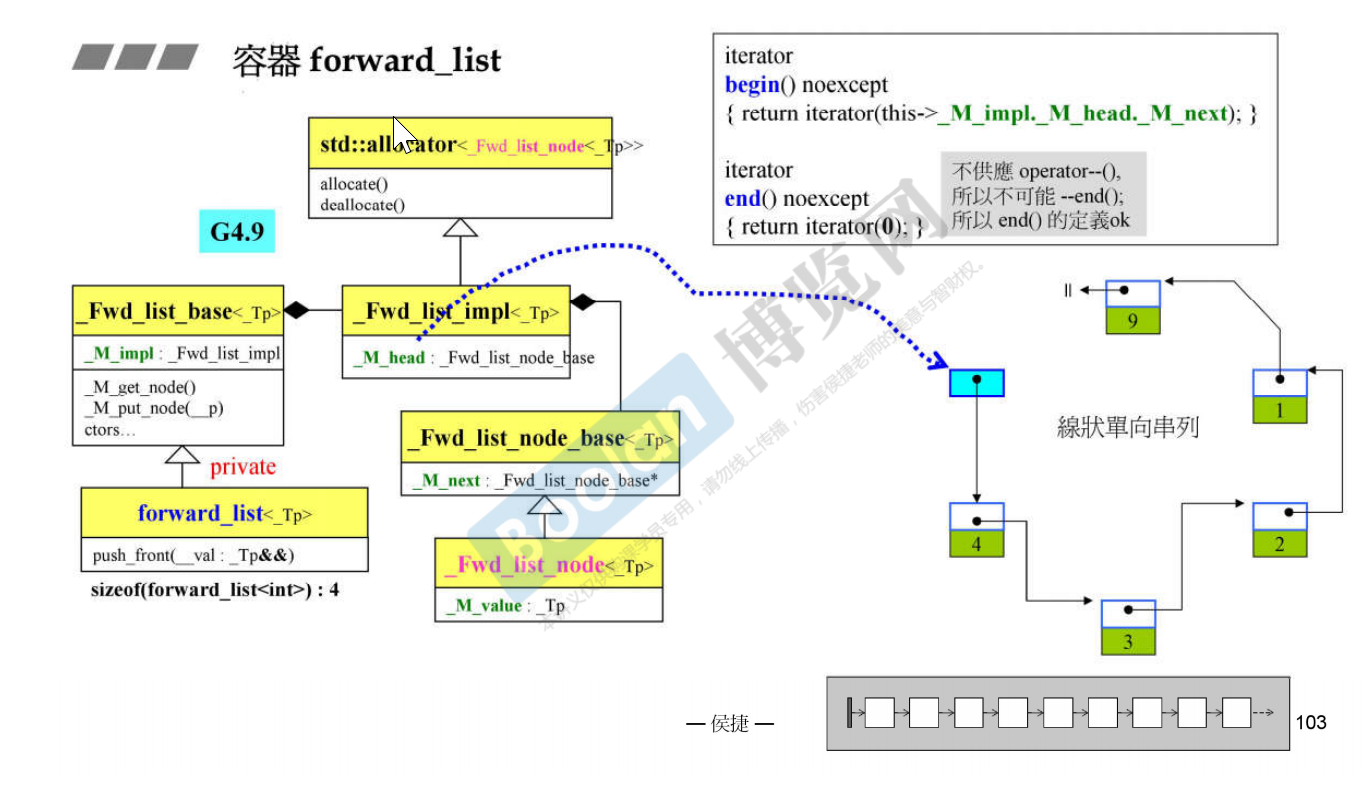
与list类似,forward_list的“头”仍然指向一个“虚无的”节点,对begin的获取则只需要取一位next即可。
GCC4.9版本中对forward_list的end指针的构造是直接传递0,而现VS2019使用MSVC版本则是传递一个nullptr,本质上是一样的
如何快速获取list的尾元素
应该不会有人直接暴力遍历一遍吧?
// 假设l为一个int的链表
cout << *(--l.end()) << endl;
既然list是循环链表,那么能通过尾巴的++操作访问到头部吗
据我目前所知,不能
Map,Set等关联式容器问题
insert操作返回的是什么
对于唯一元素容器来说(非multi),insert操作会返回std::pair<iterator, bool>
std::map<int, std::string> myMap;
std::map<int, std::string>::iterator iterator;
bool myBool;
auto returnPair = myMap.insert({ 1, "10" });
std::cout << std::boolalpha << returnPair.second << std::ends;
std::tie(iterator, myBool) = myMap.insert(std::make_pair(1, "100")); // 使用tie解包pair
std::cout << std::boolalpha << myBool << std::ends;
std::tie(std::ignore, myBool) = myMap.insert(std::make_pair(2, "100")); // 使用占位符
std::cout << std::boolalpha << myBool << std::ends;
// C++ 17
auto [newIterator, newBool] = myMap.insert(std::make_pair(3, "300"));
std::cout << std::boolalpha << newBool << std::endl;
输出结果为true false true true
题外话
std::tie一般是和std::tuple搭配使用的,但是它也兼容std::pair。std::pair具有first和second能用于访问第一和第二元素,而std::tuple没有。
int myInt;
std::string myStr;
bool myBool;
// 通过上面三个变量访问tuple的数据 较为麻烦
std::tie(myInt, myStr, myBool) = std::make_tuple(1, "123", true);
// C++17
auto [newInt, newStr, newBool] = std::make_tuple(2, "456", false);
unorded_multimap和multimap怎么遍历他们中重复的元素
unorded_multimap
unordered_multimap<string, int> peopleMap = {{"Mike", 10}, {"Mike", 20}, {"Jelly", 18}, {"Mike", 15}, {"Zed", 23}};
using umpIterator = unordered_multimap<string, int>::iterator;
pair<umpIterator , umpIterator> range = peopleMap.equal_range("Mike");
for (auto it = range.first; it != range.second; ++it)
cout << it->first << ends << it->second << endl;
multimap
multimap<string, int> peopleMap = {{"Mike", 10}, {"Mike", 20}, {"Jelly", 18}, {"Mike", 15}, {"Zed", 23}};
iterator_traits<decltype(peopleMap.begin())>::value_type::first_type name = "Mike";
for (auto it = peopleMap.lower_bound(name); it != peopleMap.upper_bound(name); ++it)
cout << it->first << ends << it->second << endl;
为什么vector使用的是push_back而不是push_front
因为vector中的数据在内存上是连续的,vector每次扩容的时候都会以当前大小的两倍去申请,也就是说在已经分配好内存的“末尾”添加一个元素是十分方便的。如果是从头进的话,那么代表vector里头的每个元素都要往后移动一位,也就意味着要执行数组当前容量次的拷贝操作,十分耗时耗空间
其他
C++中的link和编译是怎么进行的
一句话系列
不允许auto推断数组类型
以下操作是错误的,编译不通过
auto arr[3] = {1, 2, 3};