一、元组转换
数字
tu = (1) tu1 = (1,) print(tu,type(tu)) print(tu1,type(tu1))
执行输出:
1 <class 'int'>
(1,) <class 'tuple'>
字符串
tu = ('lao')
tu1 = ('lao',)
print(tu,type(tu))
print(tu1,type(tu1))
执行输出:
lao <class 'str'>
('lao',) <class 'tuple'>
列表
tu = ([1,2,3]) tu1 = ([1,2,3],) print(tu,type(tu)) print(tu1,type(tu1))
执行输出:
[1, 2, 3] <class 'list'>
([1, 2, 3],) <class 'tuple'>
总结:
对于元组:如果只有一个元素,并且没有逗号,此元素数据类型不会改变。
如果结尾有逗号,就是元组类型
元组转换为列表
tu = (1,2,3) li = list(tu) print(li)
执行输出:
[1, 2, 3]
列表转换为元组
tu = [1,2,3] li = tuple(tu) print(li)
执行输出:
(1, 2, 3)
字符串直接转换为元组是没有方法的。
除非把字符串转换为列表,再转换为元组
数字,字符串,列表,元祖,字典对应的布尔值的False分别是什么?
数字0
字符串 ''
列表 []
元组 ()
字典 {}
二、列表的坑
将索引为奇数的元素删除
li = ['laonanhai','python','alex','wusir','egon','ritian','nvsheng']
正常写法
li = ['laonanhai','python','alex','laonanhai','egon','ritian','nvsheng']
for i in li:
if li.index(i) % 2 == 1:
li.pop(li.index(i))
print(li)
执行输出:
['laonanhai', 'alex', 'laonanhai', 'ritian', 'nvsheng']
输出的结果,并不是我想要的,怎么办呢?有3种写法
第一种,使用切片,最简单的
li = ['laonanhai','python','alex','laonanhai','egon','ritian','nvsheng'] del li[1::2] print(li)
执行输出:
['laonanhai', 'alex', 'egon', 'nvsheng']
第二种,使用新列表覆盖
li = ['laonanhai','python','alex','laonanhai','egon','ritian','nvsheng']
li_1 = []
for i in range(len(li)):
if i % 2 == 0:
li_1.append(li[i])
li = li_1
print(li)
执行输出,效果同上
第三种,倒序删除。
li = ['laonanhai','python','alex','laonanhai','egon','ritian','nvsheng']
for i in range(len(li)-1,-1,-1):
if i % 2 == 1:
del li[i]
print(li)
执行输出,效果同上
倒着删除,不会影响前面的,只影响后面的。
总结:
对于list,在循环一个列表时,最好不要进行删除的动作(一旦删除,索引会随之改变),容易出错。
三、字典的坑
字典 fromkeys() 方法用于创建一个新的字典,并以可迭代对象中的元素分别作为字典中的键,且所有键对应同一个值,默认为None
dic = dict.fromkeys('abc','alex')
print(dic)
执行输出:
{'c': 'alex', 'b': 'alex', 'a': 'alex'}
使用列表创建一个新字典
dic = dict.fromkeys([1,2,3],[]) print(dic)
执行输出:
{1: [], 2: [], 3: []}
字典的第一个坑
给列表1添加一个元素
dic = dict.fromkeys([1,2,3],[])
dic[1].append('北京')
print(dic)
执行输出:
{1: ['北京'], 2: ['北京'], 3: ['北京']}
坑就来了,这3个列表,在内存中对应的是同一个列表
字典的第二个坑
将字典中含有K元素的键,对应的键值对删除
dic = {'k1':'value1','k2':'value2','name':'wusir'}
正常思路的写法:
dic = {'k1':'value1','k2':'value2','name':'wusir'}
for i in dic.keys():
if 'k' in i:
dic.pop(i)
print(dic)
执行报错:
RuntimeError: dictionary changed size during iteration
意思就是,在循环字典过程中,不允许改变字典
换一种思路,在字典中最加
dic = {'k1':'value1','k2':'value2','name':'wusir'}
count = 0
for i in dic:
dic[i+str(count)] = dic[i]
count +=1
print(dic)
执行报错,效果同上。
这题应该这么做,先将含有k的键值对,添加到列表
然后循环列表,删除字典的Key
dic = {'k1':'value1','k2':'value2','name':'wusir'}
li = []
for i in dic:
if 'k' in i:
li.append(i)
for i in li:
dic.pop(i)
print(dic)
执行输出:
{'name': 'wusir'}
总结:
在循环列表或者字典的时候,千万不要做添加或者删除操作。
四、集合
集合是没有索引,是无序的。
数据类型:
不重复,无序,它里面的元素是可哈希的。它本身是不可哈希,他不能作为字典的key
作用:
1.去重
2.数据关系测试
列表去重
列表的去重,直接转换为集合,就可以了
li = [11,11,22,22,33,33,33,44] li = list(set(li)) print(li)
执行输出:
[33, 11, 44, 22]
集合常用操作
增加
add() 添加一个元素
set1 = {'wusir','ritian'}
set1.add('女神')
print(set1)
执行输出:
{'wusir', '女神', 'ritian'}
update() 迭代增加
set1 = {'wusir','ritian'}
set1.update('abc')
print(set1)
执行输出:
{'wusir', 'c', 'ritian', 'b', 'a'}
删
remove() 删除一个元素
set1 = {'wusir','ritian'}
set1.remove('wusir')
print(set1)
执行输出:
{'ritian'}
pop() 随机删除
pop() 是有返回值的
set1 = {'wusir','ritian'}
print(set1.pop())
print(set1)
执行输出:
{'ritian'}
clear() 清空集合
set1 = {'wusir','ritian'}
set1.clear()
print(set1)
执行输出:
set()
del 删除集合
set1 = {'wusir','ritian'}
del set1
集合没有改的方法
查
查只能for循环
set1 = {'wusir','ritian'}
for i in set1:
print(i)
执行输出:
ritian
wusir
五、集合关系测试
交集( &或者intersection)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 & set2)
print(set1.intersection(set2))
执行输出:
{4, 5}
{4, 5}
并集( |或union)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 | set2)
print(set1.union(set2))
执行输出:
{1, 2, 3, 4, 5, 6, 7, 8}
{1, 2, 3, 4, 5, 6, 7, 8}
反交集( ^或 symmetric_difference)
和交集,取反的结果,也就是说,删除相同的,保留不同的。
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 ^ set2)
print(set1.symmetric_difference(set2))
执行输出:
{1, 2, 3, 6, 7, 8}
{1, 2, 3, 6, 7, 8}
差集( - 或difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 - set2)
print(set1.difference(set2))
执行输出:
{1, 2, 3}
{1, 2, 3}
子集(issubset)
判断一个集合是否被另外一个集合包含
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set1.issubset(set2))
执行输出:
True
超集(issuperset)
判断一个集合是否包含另外一个集合
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set2.issuperset(set1))
执行输出:
True
集合关系测试,记符合就可以了,英文字母太长了,不好记。
frozenset()将集合转换为可哈希的类型,可以作为字典的key
set1 = {'barry','wusir'}
set2 = frozenset(set1)
print(set2)
执行输出:
frozenset({'barry', 'wusir'})
六、深浅copy
li_1 = [1,2,3] li_2 = li_1 li_2.append(456) print(li_1) print(li_2)
执行输出:
[1, 2, 3, 456]
[1, 2, 3, 456]
执行结果是一样的。
对于赋值运算,指向的是同一个内存地址。字典,列表,集合都一样
copy
li_1 = [1,2,3] li_2 = li_1.copy() li_2.append(111) print(li_1) print(li_2)
执行输出:
[1, 2, 3]
[1, 2, 3, 111]
copy不是指向一个,在内存中开辟了一个内存空间
li_1 = [1,2,3] li_2 = li_1.copy() li_2.append(111) print(id(li_1)) print(id(li_2))
执行输出:
2204788806984
2204788808776
发现,内存地址是不一样的。
2层列表copy
li_1 = [1,2,[1,2,3],4] li_2 = li_1.copy() #内部列表添加一个值 li_1[2].append(666) print(li_1) print(li_2)
执行输出:
[1, 2, [1, 2, 3, 666], 4]
[1, 2, [1, 2, 3, 666], 4]
为什么呢?因为内部的列表内存地址是独立的一个,一旦修改,其他引用的地方,也会生效。
对于浅copy来说,第一层创建的新的内存地址
而从第二层开始,指向的都是同一个内存地址
copy一般很少用,面试会考到。
深copy必须要导入一个模块copy
import copy li_1 = [1,2,[1,2,3],4] li_2 = copy.deepcopy(li_1) #内部列表添加一个值 li_1[2].append(666) print(li_1) print(li_2)
执行输出:
[1, 2, [1, 2, 3, 666], 4]
[1, 2, [1, 2, 3], 4]
深copy,每一层,是完全用新的内存地址
浅copy,第一层是新的,从第二层开始,共用一个内存地址
对于深copy来说,两个是完全独立的,改变任意一个的任何元素(无论多少层),另一个绝对不改变
面试题:
下面的例子,l2是深copy还是浅copy
l1 = [1,2,3,[22,33]] l2 = l1[:] l1[3].append(666) print(l2)
执行输出:
[1, 2, 3, [22, 33, 666]]
对于切片来说,它是属于浅copy
七、编码补充
s = 'alex'
s1 = s.encode('utf-8') #unicode --> utf-8 编码
s2 = s.encode('gbk') #unicode --> gbk 解码
#utf-8转成unicode
s3 = s1.decode('utf-8')
print(s3)
执行输出:
alex
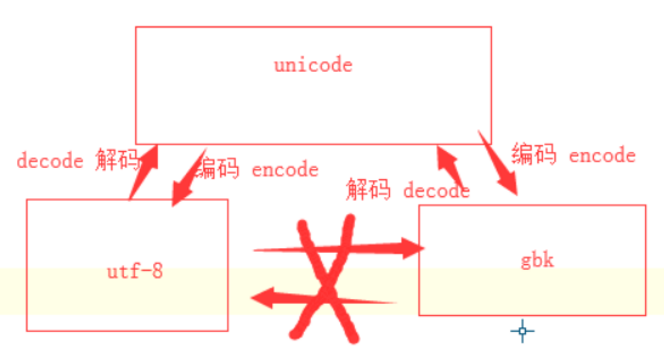
utf-8和gbk不能直接互相转化
必须通过unicode才可以。
s = '老男孩'
s1 = s.encode('gbk') #unicode转换为gbk
s2 = s1.decode('gbk') #gbk转换为unicode
s2.encode('utf-8') #unicode转换为utf-8
print(s2)
执行输出:
老男孩