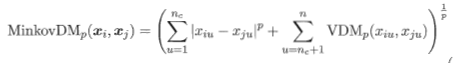无监督学习:允许我们在对结果无法预知时接近问题,在“无监督学习”中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。
9.1 聚类任务
常见的无监督学习任务:聚类、密度估计、异常检测等。
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇”。
聚类算法:聚类算法吧族群或数据点分割为一系列的组,使得相同簇的数据点比其他簇的点更接近。分隔具有相似性状的组,分配到簇中。
聚类既能作为一个单独过程,用于寻找数据的内在分布结构,也可作为分类等其他学习任务的前驱过程。
9.2 性能度量
聚类性能度量亦称“有效性指标”,与监督学习中的性能度量作用相似。
什么样的聚类结果比较好呢:“物以类聚”,我们希望聚类结果的“簇内相似度”高且“簇间相似度”低。
聚类性能度量大致有两类:一类是将聚类结果与某个“参考模型”进行比较,称为“外部指标”;另一类是直接考察聚类结果而不利用任何参考模型,称为“内部指标”。
对数据集D={x1,x2,...,xm},假定通过聚类给出的簇划分为C={C1,C2,...,Ck},参考模型给出的簇划分为C*={C1*,C2*,...,Cs*},相应的,令λ和λ*分别表示C和C*对应的簇标记向量
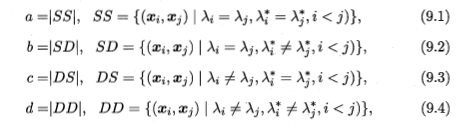
a+b+c+d=m(m-1)/2,(m为数据集D中的数据个数)
聚类性能度量外部指标:
Jaccard系数: JC = |A∩B|/|A∪B| = |SS|/|SS∪SD∪DS|=a/(a+b+c)
FM指数: FMI = 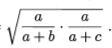
Rand指数: RI = (a+d)/ (a+b+c+d)=2(a+d)/ m(m-1)
上述性能度量的结果值均在[0,1]区间,值越大越好。

聚类性能度量的内部指标:
DB指数: 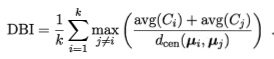
Dunn指数: 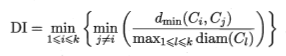
DBI值越小越好,DI值越小越好
9.3 距离计算
对函数dist(·,·),若他是一个“距离度量”,则需满足一些基本性质:
非负性:dist(xi,xj)>=0;
同一性:dist(xi,xj) = 0,当且仅当xi=xj;
对称性:dist(xi,xj) = dist(xj,xi);
直递性:dist(xi,xj) <= dist(xi,xk)+dist(xk,xj)
给定样本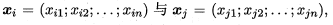 最常用的是“闵可夫斯基距离”
最常用的是“闵可夫斯基距离”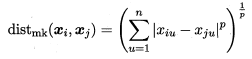
p=2,闵可夫斯基距离即欧氏距离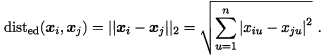
p=1时,闵可夫斯基距离即曼哈顿距离
闵可夫斯基可用于有序属性;
对于无序属性可采用VDM,令mu,a表示在属性u上取值为a的样本数,mu,a,i表示在第i个样本簇中在属性u上取值为a的样本数,k为样本簇数,则属性u上两个离散值a与b之间的VDM距离为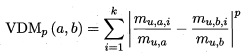
于是,将闵可夫斯基距离和VDM结合可处理混合属性