hystrix 作用
做资源隔离,限流,熔断,降级,运维监控.
直白说,hystrix一定程度上能保障了微服务架构系统服务的高可用性,避免了很多服务雪崩,系统彻底瘫痪的情况,提高了系统容错性
补:限流的前置还可以增加截流,被限流调的请求很可能不断地不断地再次请求,服务器也要一遍一遍的返回安抚结果(返回个简单页面啊 或者基本的信息啊),也会增加服务器负担,
当某个相同的请求发送超过一定阈值,直接对该请求截流,在客户端就截掉,使之到不了网络层,限制住。
补:开启限流可根据单位时间内请求数量限流,处理不过来的请求做降级处理
也可根据服务机器CPU负载程度做限流, 当cpu负载过高 把打过来的请求先都拒绝掉,定义个冷却时间,冷却时间结束再接受请求
补:对于请求其他服务的请求失败,可以有重试机制,重试机制可采取周期机制(100ms一次,300ms一次,500ms一次),可限定次数(如超过5次自动做降级处理 不再重试)
对于下有服务请求超时的情况,不要长时间等待,fail-fast,快速失败 防止请求大量积压,维护服务稳定性
补:极限压测+故障演练
hystrix的几大基本功能
资源隔离: 防止某一服务,或者某一任务线程在故障的情况下耗尽所有资源。 例如订单服务调用商品服务,商品服务故障导致发给商品服务的请求得不到返回,订单服务的所有线程资源被商品服务耗光。
限流: 简单理解 高峰期10万QPS,限流阻挡了9万QPS进入不了系统,保护系统不被瞬间大量QPS打崩
熔断: 当服务的一些依赖挂掉(例如mysql,redis等) 每次请求都会报错,几次请求后根据断路器进行熔断,阻止请求继续访问依赖,直到依赖恢复
降级: 高峰期10万QPS,配合限流只限制1万能打进系统正常请求,其他9万请求做降级处理(返回个简单页面等)
运维监控: 对线上请求 监控+报警+优化
资源隔离具体场景
以一个电商商品服务系统为例
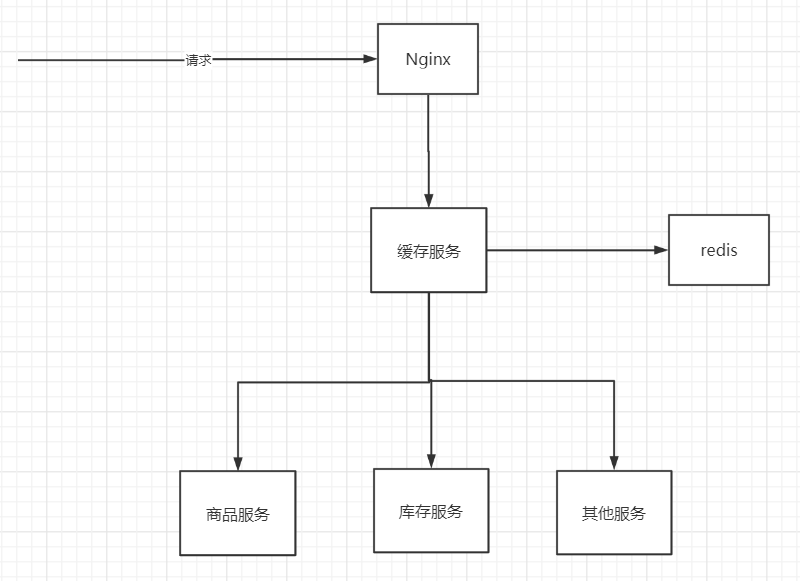
如果想查商品信息,客户端发送请求打过来落在Nginx上,先查Nginx本地缓存是否有想要的数据
如果没有向下请求缓存服务,缓存服务先找redis是否有
如果没有缓存服务请求商品服务,商品服务再查找DB。 找到商品信息返还给缓存服务,再更新redis,再更新Nginx本地缓存
同理查询库存信息 还是其他信息。
如果请求商品信息时 商品服务发生故障,打过来的请求会被阻塞住,就会导致缓存服务所有发给商品服务的请求线程都会被阻塞,导致缓存服务的资源被商品服务耗尽,没有线程再去请求其他服务
用hystrix的线程池做资源隔离,用线程池,固定请求商品服务的请求数量10,请求库存服务的线程10...限制请求每个服务的线程数,保证资源不会全被某个服务耗尽
除了线程池,hystrix还提供一种资源隔离技术-信号量
请求线程过来,线程池是自己内部创建新的线程来完成完成请求的调用,适用于请求去调用不同服务。
信号量不会创建新的线程,直接用请求来的这个线程来干活,限制了总的并发量,更为轻量。
hystrix线程池与服务接口的划分
command group --> command key --> command
调用的整体服务 --> 服务的调用的每个接口 --> 每条请求
一般来说每个command group给一个线程池,将一个服务的粒度资源隔离 (细粒度的划分也可以每个command key 有自己的线程池用来资源隔离)
command group 的意义在于 统计一个服务的信息,请求次数,超时次数,失败次数,某个服务的访问情况
hystrix底层原理
hystrix通过命令模式,将每个请求封装成一个Command,每个类型的Command对应一个线程池 (例如商品服务Command)
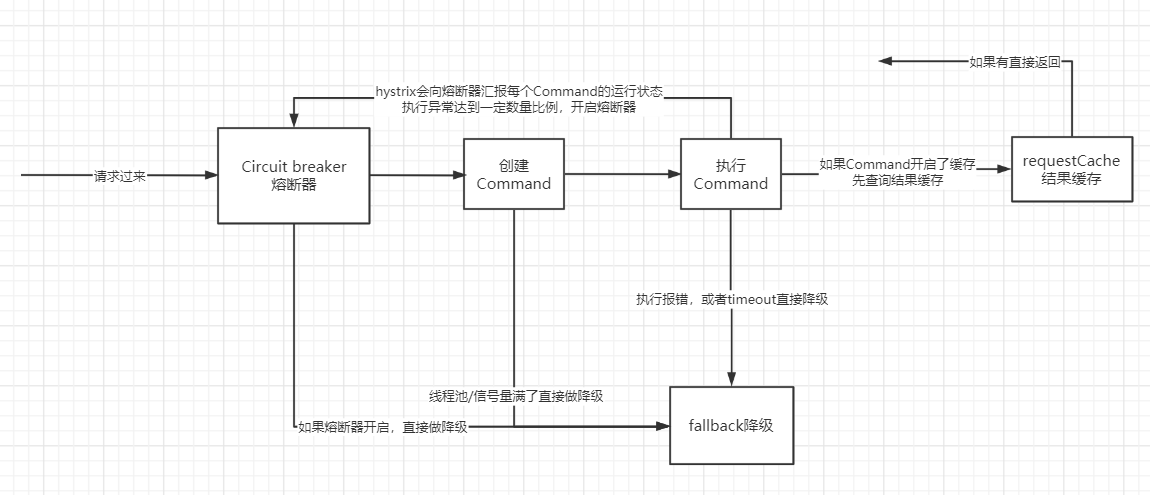
请求过来,为请求创建Command
如果Command开启了缓存(配置的一个参数) ,会先向requestCache查询调用服务的结果,如果有直接返回
每个Command执行完会上报自己的执行结果状态给熔断器Circuit breaker,成功,失败,超时,拒绝,熔断器会统计这些数据
如果一个Command执行报错或者超时会直接做fallback降级处理。
如果同一类型Command的线程池或信号量已经满了,再来的请求会直接做fallback降级
如果熔断器已经开启了,那么所有的请求都直接做降级处理
什么时候会开启熔断器Circuit breaker?
1.上报熔断器的Command请求数量短时间内达到阈值(例如1秒内达到100个),这是熔断器回去判断是否需要开启
2.统级所有上报的Command请求结果异常的数量是否达到一定比例(例如60%),达到预配置的比例会直接开启
开启熔断器后,熔断器由close状态 切换到 open状态,所有请求全部做fallback降级
经过一段时间后,会从open状态 切换到 half-open状态,试着让少量请求通过熔断器 试试能不能正常调用,再决定是否open 还是close
fallback降级一般的处理方式
降级返回默认值,给个友好提示 (对不起,系统开小差了呃..)
返回缓存里面的值,或者(例如从redis或者ehcache尽量取一些值,拼成一个结果返还给客户端)
不同的command执行方式,其fallback为空或者异常时的返回结果不同
执行command
执行Command就可以发起一次对依赖服务的调用
要执行Command,需要在4个方法中选择其中的一个:execute(),queue(),observe(),toObservable()
execute():调用后直接block住,属于同步调用,直到依赖服务返回单条结果,或者抛出异常
queue():返回一个Future,属于异步调用,后面可以通过Future获取单条结果
observe():订阅一个Observable对象,Observable代表的是依赖服务返回的结果,获取到一个那个代表结果的Observable对象的拷贝对象
toObservable():返回一个Observable对象,如果我们订阅这个对象,就会执行command并且获取返回结果
调用HystrixObservableCommand.construct()或HystrixCommand.run()来实际执行这个command
HystrixCommand.run()是返回一个单条结果,或者抛出一个异常
HystrixObservableCommand.construct()是返回一个Observable对象,可以获取多条结果
如果HystrixCommand.run()或HystrixObservableCommand.construct()的执行,超过了timeout时长的话,那么command所在的线程就会抛出一个TimeoutException
如果timeout了,也会去执行fallback降级机制,而且就不会管run()或construct()返回的值了
这里要注意的一点是,我们是不可能终止掉一个调用严重延迟的依赖服务的线程的,只能说给你抛出来一个TimeoutException,但是还是可能会因为严重延迟的调用线程占满整个线程池的
即使这个时候新来的流量都被限流了。。。
如果没有timeout的话,那么就会拿到一些调用依赖服务获取到的结果,然后hystrix会做一些logging记录和metric统计