一般情况下,我们都是用手工操作的方式来对浏览器进行各种操作 。 实际上,
只要我们安装一个自动化操作组件, Python 就可以让我们的很多操作实现自动化 。
Selenium 组件
在开发网页时,用户接口的测试向来是一件相当不容易的事情,如果用手动方
式进行测试的各种操作,不仅效率低而且容易出错 。 Selenium 的出现就是为了解决
这个问题,它可以通过指令实现对网页操作的自动化,从而完成自动测试的功能。
除此之外, Selenium 还可以将许多其他的网页操作实现自动化,井能在指定时间自
动运行,功能相当强大。
安装 Selenium
使用 Se l enium 前,我们首先必须安装 Selenium 组件,安装命令如下:
pip install selenium
下载 Chrome WebDriver
要自动操作 Google Chrome 浏览器,还须安装相关的驱动程序,请根据自己的
操系统( Linux, Mac, Windows )下载 Chrome WebDriver ,网址如下:
http://chromedriver.storage.googleapis.com/index.html?path=2.27/
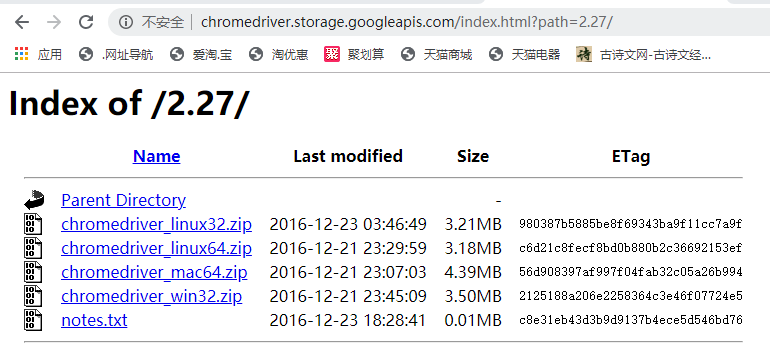
下载文件chromedriver_win32.zip即可。即使电脑是64位也没有关系,因为你安装的谷歌是32位的
解压之后,将chromedriver.exe放到谷歌浏览器的安装目录中:在开始菜单中,找到谷歌浏览器,然后右键“打开文件位置”,我的是C:Program Files (x86)GoogleChromeApplication
将谷歌浏览器的安装目录,添加到系统环境变量path中。




创建 Google Chrome 浏览器对象后,就可以通过 getO 方法连接到指定网址,最
后用 quit()方法关闭浏览器。 以百度网的连接和退出为例,代码如下 :
from selenium import webdriver browser= webdriver.Chrome() browser.get('http://www.baidu.com') browser.quit()
我们还可以把要浏览的网站建立一个列表,这样就能依次访问这些网站。如先 打开 Chrome 浏览器,把窗 口 最大化,然后每 3 秒打开一个列表 中的网站 , 最后关 闭 浏览器 。
from time import sleep from selenium import webdriver urls = ['http://www.baidu.com','http://news.sina.com.cn/','http://www.wsbookshow.com'] browser = webdriver.Chrome() browser.maximize_window for url in urls: browser.get(url) sleep(3) browser.quit()
查找网页元素
如果我们想要与网页进行互动,比如,我们要单击下单锻钮、超链接或要输入
文字 ,那么我们必须先获得网页元素,这样才能对这些特定元素进行操作 。
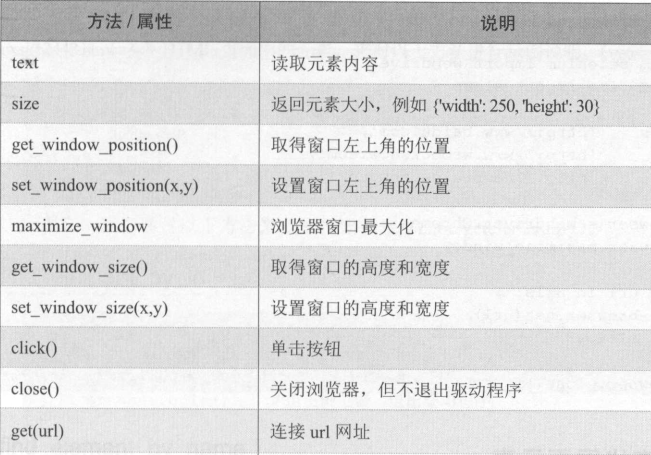
Selenium Webdriver API 提供了 多种获取网页元素的方法。 如下表所示 :

在以上各个方法名称中的 element 后面加上 s ,会返回特定查找的元素列表。
下面我们通过用 Chrom 浏览器访问http://www.wsbookshow.com/bookshow/jc/bkcxsj/12442.html这个 HTh伍页面中的元素,来对以上方法进行示例说明。
from selenium import webdriver #导入webdriver url='http://www.wsbookshow.com/bookshow/jc/bk/cxsj/13054.html' #以此链接为例 browser=webdriver.Chrome() #生成Chrome浏览器对象(结果是打开Chrome浏览器) browser.get(url) #在浏览器中打开url
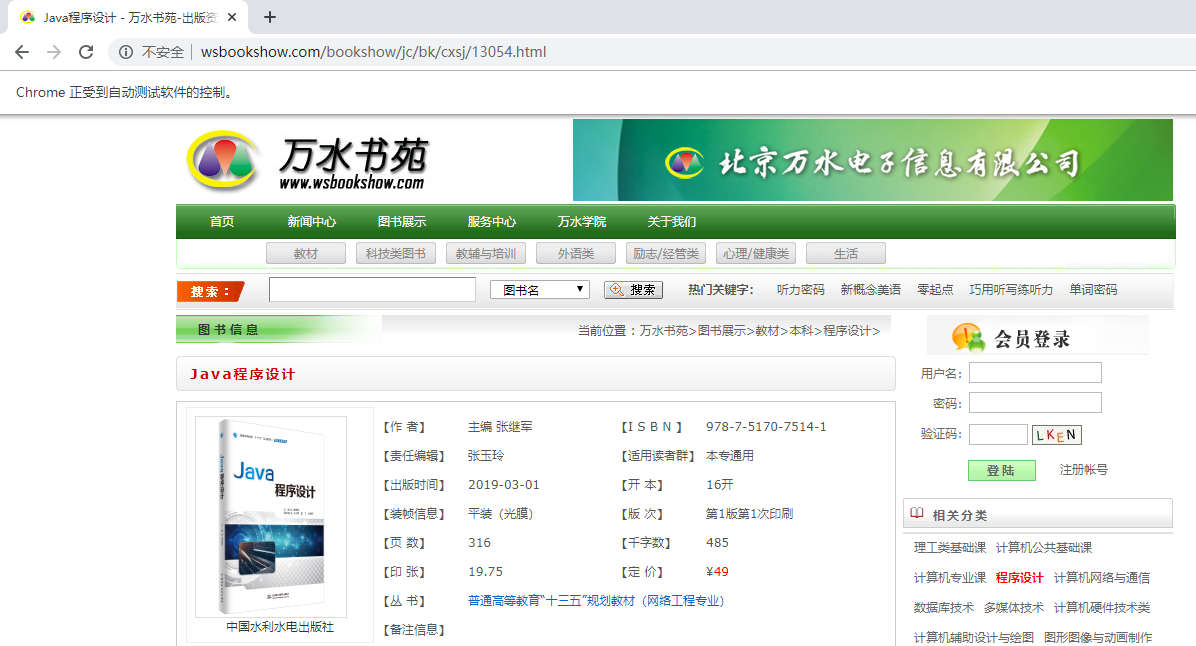
login_form=browser.find_element_by_id("menu_1") ##查找id="menu_1"的元素 print(login_form.text) #显示元素内容 #browser.quit() #退出浏览器,退出驱动程序

username=browser.find_element_by_name("username") #查找name="username"的元素 password=browser.find_element_by_name("pwd") #查找name="pwd"的元素
login_form=browser.find_element_by_xpath("//input[@name='arcID']") login_form=browser.find_element_by_xpath("//div[@id='feedback_userbox']")
continue_link=browser.find_element_by_link_text('科技类图书') continue_link=browser.find_element_by_link_text('英语')
heading1=browser.find_element_by_tag_name('h1') content=browser.find_elements_by_class_name('topbanner') content=browser.find_elements_by_css_selector('.topsearch') #print(content.get_property) browser.quit() #退出浏览器,退出驱动程序