1. 数据库的发展过程 层次模型 -->网状模型 -->关系模型 -->对象关系模型 2. 关于数据库的概念 DB:数据库(存储信息的仓库) DBMS:数据库管理系统(用于管理数据库的工具) RDBMS:关系型数据库管理系统 ORDBMS:对象关系型的数据库管理系统 3. Oracle数据库的主要特点 1)支持多用户、大事务量的处理 2)数据库安全性和完整性控制 3)支持分布式数据处理 4)可移植性 4.Oracle一些常见问题? 1)如果我只有一张表,为什么我还要创建数据库? SQL语言要求所有表都需放在数据库里。这项设计当然有它好的理由。SQL能控制多为用户同时访问表的行为。能够授予或撤销对整个数据库的访问权。这有时比控制每张表的权限要简单很多 2)创建库的命令的字母全是大写,一定要这样吗? 有些系统确实要求某些关键字采用大写形式。但SQL本身不区分大小写。也就是说,命令不大写也可以,但命令大写是良好的SQL编程惯例。 3)给数据库、表和列命名时有什么主意事项吗? 创建具有描述性的名称通常有不错的效果。有时候要多用几个单词来命名。所有名称都不能包含空格,所以使用下划线能够让你创建更具描述性的名称。命名时最好避免首字母大写,因为SQL不区分大小写。极有可能会搞错数据库。 4)为什么不能直接把BLOB当成所有文本值的类型? 因为这样很浪费空间。VARCHAR或CHAR只会占用特定空间。不会多于256字符。但BLOB需要很大的存储空间。随着数据库的增长,占用存储空间就是冒着耗尽硬盘空间的风险。另外,有些重要的字符串运算无法操作BLOB类型的数据。只能用于VARCHAR或CHAR。 5)为什么需要INT和DEC这类数值类型? 节省数据库存储空间和效率有关。为表的没列选择最合适的数据类型可以为表瘦身,还可以使数据操作更为快速。 5.Oracle关系数据库基础 1)主键:表中其中一列或几列的组合,其值能唯一标识表中每一行。 表中任何列都可以作为主键,但要满足如下条件: 任何两行都不具有相同的主键值 每个行都必须具有一个主键值(主键列不允许为null值) 主键列中的值不允许修改或更新 主键值不能重用(如果某行从表中删除,它的主键不能赋给以后的新行) 一般以id或uuid作为主键的名字 2)外键是什么: 在一个关系(参照表)中是主键,而另一个关系引用这个键。那么这个键在另一个关系中就是外键。 3)外建能干什么: 使两个关系(表)形成关联,外键只能引用参照表中的主键。保持数据一致性,完整性。 如图:
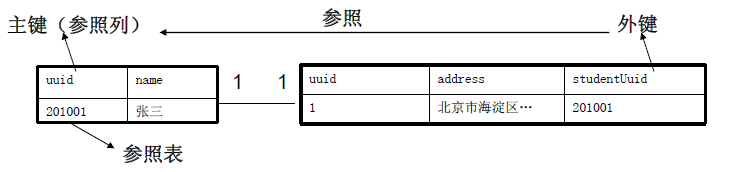
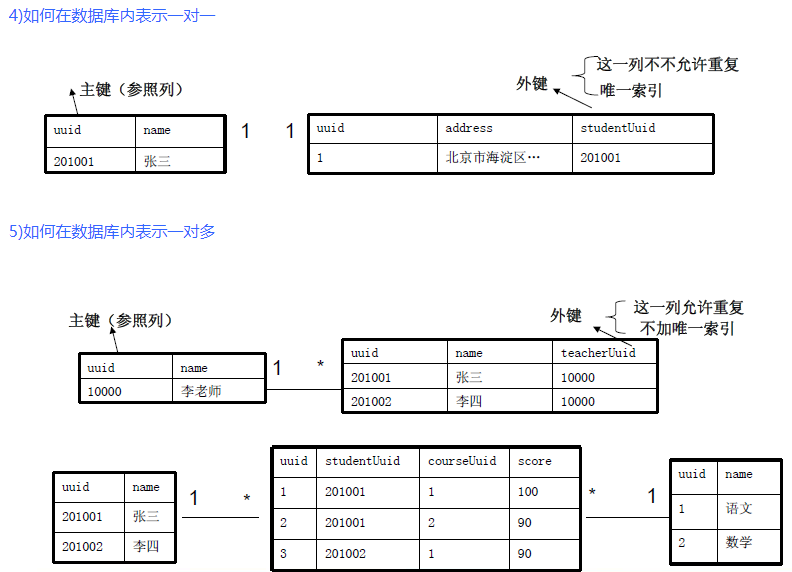
6)关系模型的完整性约束是什么? 是通过关系的某种约束条件对关系进行约束。也就是说关系的值随时间变化时应该满足一些约束条件。如年龄不能超过1000,性别必须是男或者女 7)关系模型的完整性约束能有什么? 实体完整性、参照完整性、用户自定义完整性。 实体完整性:针对基本关系而言,也就是一个二维表,主键不能为NULL 参照完整性:表之间存在关系,自然就存在关系的引用(外键),表和表之间的关系通过外键实现,外键可以为NULL或引用表的主键 用户自定义完整性:针对不同的需求定义自己的完整性约束,如不允许学生编号中出现非数字字符,性别必须是男或者女
6. Oracle自学笔记 1)数据库和表的名称不一定要大写。 2)列是存储在表中的一块数据,行是一组能够描述某个事物的列的集合。列和行构成了表。 3)创建oracle数据库。使用oracle自带的Database Configuration Assistant 来创建库 4)使用DBA身份 创建表空间。具体sql如下: create tablespace pzw datafile 'C:/oracle/pzw.dbf' SIZE 1024M REUSE AUTOEXTEND OFF extent management local segment space management auto; 5)删除用户命令 drop user pzw cascade; 6)删除表空间命令 DROP TABLESPACE pzw INCLUDING CONTENTS AND DATAFILES; 7 )查看表空间命令。 (推荐)方法一: select dbf.tablespace_name, dbf.totalspace "总量(M)", dbf.totalblocks as 总块数, dfs.freespace "剩余总量(M)", dfs.freeblocks "剩余块数", (dfs.freespace / dbf.totalspace) * 100 "空闲比例" from (select t.tablespace_name, sum(t.bytes) / 1024 / 1024 totalspace, sum(t.blocks) totalblocks from dba_data_files t group by t.tablespace_name) dbf, (select tt.tablespace_name, sum(tt.bytes) / 1024 / 1024 freespace, sum(tt.blocks) freeblocks from dba_free_space tt group by tt.tablespace_name) dfs where trim(dbf.tablespace_name) = trim(dfs.tablespace_name) 方法二: SELECT Total.name "Tablespace Name", Free_space, (total_space-Free_space) Used_space, total_space FROM (select tablespace_name, sum(bytes/1024/1024) Free_Space from sys.dba_free_space group by tablespace_name ) Free, (select b.name, sum(bytes/1024/1024) TOTAL_SPACE from sys.v_$datafile a, sys.v_$tablespace B where a.ts# = b.ts# group by b.name ) Total WHERE Free.Tablespace_name = Total.name 方法三: Select * From Dba_Tablespaces 8)创建用户。 create user pzw identified by pzw; 9)将包空间分配给用户 alter user pzw default tablespace pzw; 10)给用户授权 grant create session, create table, unlimited tablespace to pzw; 11)创建表 CREATE TABLE doughnut_list ( doughnut_name VARCHAR(10), doughnut_type VARCHAR(6), doughnut_birthday DATE ); 12)删除表 DROP TABLE doughnut_list; 13)给表中增加一列 Alter table EMP add sale number; 14)数据库插入一条数据 insert into DEPT_EMP_TABLE (DEPT_EMP_NO,emp_no,Dept_No,Joined_Date) values (009,'00002',1,to_date('2011-2-28 15:42:56','yyyy-mm-dd hh24:mi:ss')); commit; 15)数据库修改一条数据 update emp set emp_name='张惠妹',age=20,sex='女',profession='流行歌手' where emp_no = '00002'; commit; 16)数据库删除一条数据 delete emp where emp_no = '000013'; commit; 17)查询全部数据 select * from emp; 18)创建视图 create view adress_view as select * from pzw.adress;
以下为oracle演示数据操作及练习题(使用scott 登陆。默认密码tiger) 1.查看演示数据的表。 select*fromtab 或者selecttable_namefromuser_tables; 2.查看表结构(plsql操作无效。使用命名提示符 可以操作) desc dept; 3.查看员工姓名 select ENAMEfrom emp; 4.查询员工的编号和明星(sql语句不区分大小写) select empno, enamefrom emp; 5.查询所有的字段 select*fromemp; 一般建议不使用*号,使用*号不明确,建议将相关的字段写到select语句的后面,使用*号的效率比较低 6.列出员工的编号,姓名和年薪。 select empno, ename,sal*12from emp; select语句中可以使用运算符,以上存在一些问题,年薪的字段名称不太明确 7.将查询出来的字段显示为中文 select empnoas 员工编号, ename as 员工姓名, sal*12 as 年薪 from emp; 可以采用as命名别名,as可以省略 如:可以采用as命名别名,as可以省略 8.查询薪水等于5000的员工 select empno, ename, sal from emp where sal=5000; 如果是字符类型的数据进行比较的时候,是区分大小写的。 9.查询薪水不等于5000的员工 select empno, ename, sal from emp where sal<>5000; 10.查询工作岗位不等于manager的员工 select empno,ename,sal,job from emp where job<> 'manager'; 在sql语句中如果是字符串采用单引号,引起来,不同于java中采用双引号,如果是数值型也可以引起来,只不过是数值类型数据当成字符串来处理 11.查询薪水为1600到3000的员工(第一种方式,采用>=和<=) select empno, ename, sal from emp where sal>=1600 and sal<=3000; 查询薪水为1600到3000的员工(第一种方式,采用between ...and...) select empno,ename,sal,job from emp where salbetween 1600and 3000; between ….and …,包含最大值和最小值 between ….and …,不仅仅可以应用在数值类型的数据上,还可以应用在字符数据类型上 between ….and …,对于两个参数的设定是有限制的,小的数在前,大的数在后 12.查询津贴为空的员工 select * from emp where commis null; 13.查询津贴不为空的员工 select * from emp where commis not null; 14.工作岗位为MANAGER,薪水大于2500的员工。 select empno, ename, sal from emp where job='MANAGER'and sal>2500; and表示并且的含义,表示所有的条件必须满足 15.查询出job为manager和job为salesman的员工。 select * from emp where job='MANAGER'or job='SALESMAN'; or,只要满足条件即可,相当于或者 16.查询薪水大于1800,并且部门编号为20 或者 30的 select * from emp where sal>1800and (deptno=20or deptno=30); 17.查询出job为manager和job为salesman的员工 select * from emp where jobin('MANAGER','SALESMAN'); 18.查询job不等于MANAGER并且不能与SALESMAN的员工(第一种写法) select * from emp where job<> 'MANAGER' and job <> 'SALESMAN'; 19 .查询job不等于MANAGER并且不能与SALESMAN的员工(第二种写法) select * from emp where jobnot in('MANAGER','SALESMAN'); 20.查询以M开头的所有员工 select * from emp where ename like 'M %'; 21.查询以T结尾的所有员工 select * from emp where ename like '%T'; 22.查询以O结尾的所有员工 select * from emp where ename like '%O%'; 23.查询姓名中第一个字符为A的所有员工 select * from emp where ename like '_A%'; Like可以实现模糊查询,like支持%和下划线匹配 Like中%和下划线的差别? %匹配任意字符出现任意次数 下划线只匹配一个任意字符出现一次 Like语句是可以应用在数值类型的数据上的,但是如果没有使用引号括起来的话,那么不能使用%和下划线。类似于等号的操作,如果使用引号括起来的话,那么可以使用%和下划线,将数值类型的数据转换为字符类型后进行处理。 24.按照薪水由小到大排序 s elect * from emporder by sal; 如果存在where子句那么order by必须放到where语句的后面 25.手动指定按照薪水由小到大排序 select * from emp order by saldesc; 26. 按照薪水和姓名排序 select * from emp order by sal desc ,ename desc; 如果采用多个字段排序,如果根据第一个字段排序重复了,会根据第二个字段排序 select * from emp order by sal asc; 26.手动指定按照薪水由大到小排序 select * from emporder by sal desc; 27.按照薪水升序(使用字段的位置来排序) select * from emp order by 6; 不建议使用此种方式,采用数字含义不明确,程序不健壮 28.查询员工.将员工姓名全部转换成小写。 select lower(ename)from emp; 29.查询job为manager的员工 select * from emp where job=upper('manager'); 30.查询姓名以M开头所有的员工 select * from emp wheresubstr(ename, 1,1)='M'; 方法的第二个参数表示的是查询字符的位置,0,1都表示第一个字符,负数表示从结尾开始的位置,第三个参数表示截取字符串的长度。 31.取得员工姓名的长度 select length(ename) from emp; 32.取得工作岗位为MANAGER的所有员工 select * from emp where job=trim('MANAGER '); trim会去首尾空格,不会去除中间的空格 33.查询1986-02-20入职的员工(第一种方法,与数据库的格式匹配上) select * from emp where HIREDATE='20-2月 -81'; 查询1982-02-20入职的员工(第二种方法,将字符串转换成date类型) select * from emp where hiredate=to_date('1981-02-20 00:00:00', 'YYYY-MM-DD HH24:MI:SS'); to_date可以将字符串转换成日期,具体格式to_date(字符串,匹配格式) 34.查询1981- 02-30以后入职的员工,将入职日期格式为yyyy-mm-dd hh:mm:ss select empno, ename,to_char(hiredate,'yyyy-mm-dd hh24:mi:ss')from emp where hiredate>to_date('1981-02-2000:00:00', 'YYYY-MM-DD HH24:MI:SS'); 35.查询员工薪水加入前分位 select empno, ename, to_char(sal, '$999,999') from emp; 36.查询薪水加入千分位和保留两位小数 select empno, ename, to_char(sal, '$999,999.00') fromemp; 将数字转换成字符串,格式 控制符 说明 9 表示一位数字 0 位数不够可以补零 $ 美元符 L 本地货币符号 . 显示小数 , 显示千分位 37.将字符串转换成数值 select * from emp where sal>to_number('1,500','999,999'); 38.取得员工的全部薪水,薪水+津贴 select empno, ename, sal, comm, sal+nvl(comm,0) fromemp; 39.如果job为MANAGER薪水上涨10%,如果job为SALESMAN工资上涨50%(case … when … then …end) select empno, ename, job, sal, (casejobwhen 'MANAGER' thensal*1.1when 'SALESMAN' thensal*1.5end)as newsal from emp; 40.如果job为MANAGER薪水上涨10%,如果job为SALESMAN工资上涨50%(decode) select empno, ename, job, sal, decode(job,'MANAGER', SAL*1.1, 'SALESMAN',sal*1.5) as newsal from emp; 41.四舍五入 select round(1234567.4567, 2) from dual; Dual是oracle提供的,主要为了方便使用,因为select的时候需要用from 42.聚合函数 count 取得记录数 sum 求和 Avg 取平均 Max 取最大的数 min 取最小的数 43.取得所有员工人数 select count(*) from emp; Count(*)表示取得所有记录,忽略null,为null值也会取得 44.取得津贴不为null的员工数 select count(comm) from emp; 采用count(字段名称),不会取得为null的纪录 45.取得工作岗位的个数 select count(distinctjob) from emp; Distinct可以去除重复的纪录 46.取得薪水的合计 select sum(sal) from emp; 47取得薪水的合计(sal+comm) select sum(sal+nvl(comm, 0)) from emp; 48.取得平均薪水 select avg(sal) from emp; 49.取得最高薪水 select max(to_char(hiredate, 'yyyy-mm-dd')) from emp; 50.取得最小薪水 select min(sal) from emp; 51.取得最早入职的员工 select min(hiredate) from emp; 52.可以将这些聚合函数都放到select中一起使用 select count(*), sum(sal), avg(sal), max(sal),min(sal) from emp; 53.取得每个岗位的工资合计,要求显示岗位名称和工资合计。 select job, sum(sal) from empgroupby job; 采用group by,非聚合函数所使用的字段必须参与分组, Group by中不能使用聚合函数 如果使用了order by,order by必须放到group by后面 54。取得每个岗位的平均工资大于2000 select job, avg(sal) from emp group by job having avg(sal) >2000; 分组函数的执行顺序: 1、 根据条件查询数据 2、 分组 3、 采用having过滤,取得正确的数据 55. 显示每个员工信息,并显示所属的部门名称 select ename ,dname from emp a ,dept b where a.deptno = b.deptno; 以上查询也称为“内连接”,指查询相等的数据 56.取得员工和所属的经理的姓名 select a.ename, b.ename from emp a, emp b wherea.mgr=b.empno; 以上称为“自连接”,只有一张表连接,具体的查询方法 57.(内连接)显示薪水大于2000的员工信息,并显示所属的部门名称 SQL99语法: select ename,sal,dname from emp a join dept b on a.deptno = b.deptno where sal>2000; SQL92语法 select ename,sal,dname from emp a, dept b where a.deptno=b.deptno and sal > 2000; Sql92语法和sql99语法的区别:99语法可以做到表的连接和查询条件分离,特别是多个表进行连接的时候,会比sql92更清晰 58.(外连接)显示薪水大于2000的员工信息,并显示所属的部门名称,如果某一个部门没有员工。那么该部门也必须显示出来 select dname,ename from emp a right join dept b on a.deptno = b.deptno; 59.查询员工名称和所属经历的名称,如果没有上级经理,也要查询出来 Select e.ename, m.ename mname from emp e, emp mwhere m.empno(+) = e.mgr; 60.查询员工信息,查询哪些人是管理者,要求显示出其员工编号和员工姓名 select ename,ename from emp where empno in (select distinct mgr from emp where mgr is not null); 61.查询那些人的薪水高于员工的平均薪水,需要显示员工编号,员工姓名,薪水。 select empno, ename, sal from emp where sal>(selectavg(sal) from emp); 分析思路:首先根据文字描述找出被依赖的条件,逐次分析 62.查询各个部门的平均薪水所属的等级,需要显示部门编号,平均薪水,等级编号 select a.deptno, a.avg_sal, b.grade from (select deptno, avg(sal) avg_sal fromemp group by deptno) a, salgrade b where a.avg_sal between b.losal and b.hisal; 关键点:将子查询看作一张表 63.查询员工信息以及部门名称 Select e.empno, e.ename, e.deptno, (select dname from dept where deptno = e.deptno) as dname from emp e 64.union可以合并集合(相加) select * from emp where job='MANAGER' union select* from emp where job='SALESMAN' 65.minus可以移出集合(相减) 查询部门编号为10和20的,取出薪水大于2000的。 select * from emp where deptno in(10, 20) minus select* from emp where sal>2000 66.rownum隐含字段 select rownum, a.* from emp a; 67.取得前5条数据 select * from emp where rownum <=5; 68.取得薪水最好的前5名 select empno, ename, sal from (select empno,ename, sal from emp order by sal desc)whererownum <=5