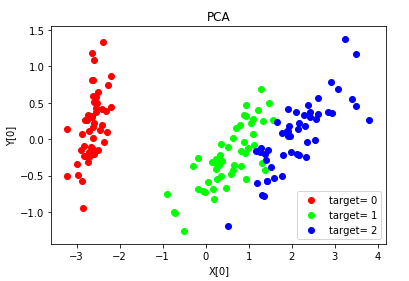
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,decomposition def load_data(): ''' 加载用于降维的数据 ''' # 使用 scikit-learn 自带的 iris 数据集 iris=datasets.load_iris() return iris.data,iris.target #PCA降维 def test_PCA(*data): X,y=data # 使用默认的 n_components pca=decomposition.PCA(n_components=None) pca.fit(X) print('explained variance ratio : %s'% str(pca.explained_variance_ratio_)) # 产生用于降维的数据集 X,y=load_data() # 调用 test_PCA test_PCA(X,y)
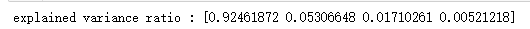
def plot_PCA(*data): ''' 绘制经过 PCA 降维到二维之后的样本点 ''' X,y=data # 目标维度为2维 pca=decomposition.PCA(n_components=2) pca.fit(X) # 原始数据集转换到二维 X_r=pca.transform(X) ###### 绘制二维数据 ######## fig=plt.figure() ax=fig.add_subplot(1,1,1) # 颜色集合,不同标记的样本染不同的颜色 colors=((1,0,0),(0,1,0),(0,0,1),(0.5,0.5,0),(0,0.5,0.5),(0.5,0,0.5),(0.4,0.6,0),(0.6,0.4,0),(0,0.6,0.4),(0.5,0.3,0.2)) for label ,color in zip( np.unique(y),colors): position=y==label ax.scatter(X_r[position,0],X_r[position,1],label="target= %d"%label,color=color) ax.set_xlabel("X[0]") ax.set_ylabel("Y[0]") ax.legend(loc="best") ax.set_title("PCA") plt.show() # 调用 plot_PCA plot_PCA(X,y)