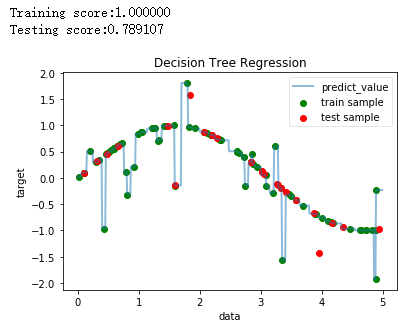
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier,DecisionTreeRegressor def creat_data(n): np.random.seed(0) X = 5 * np.random.rand(n, 1) y = np.sin(X).ravel() noise_num=(int)(n/5) # 每第5个样本,就在该样本的值上添加噪音 y[::5] += 3 * (0.5 - np.random.rand(noise_num)) return train_test_split(X, y,test_size=0.25,random_state=1) #决策树DecisionTreeRegressor模型 def test_DecisionTreeRegressor(*data): X_train,X_test,y_train,y_test=data regr = DecisionTreeRegressor() regr.fit(X_train, y_train) print("Training score:%f"%(regr.score(X_train,y_train))) print("Testing score:%f"%(regr.score(X_test,y_test))) #绘图 fig=plt.figure() ax=fig.add_subplot(1,1,1) X = np.arange(0.0, 5.0, 0.01)[:, np.newaxis] Y = regr.predict(X) ax.scatter(X_train, y_train, label="train sample",c='g') ax.scatter(X_test, y_test, label="test sample",c='r') ax.plot(X, Y, label="predict_value", linewidth=2,alpha=0.5) ax.set_xlabel("data") ax.set_ylabel("target") ax.set_title("Decision Tree Regression") ax.legend(framealpha=0.5) plt.show() # 产生用于回归问题的数据集 X_train,X_test,y_train,y_test=creat_data(100) # 调用 test_DecisionTreeRegressor test_DecisionTreeRegressor(X_train,X_test,y_train,y_test)
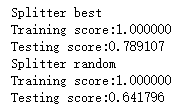
def test_DecisionTreeRegressor_splitter(*data): ''' 测试 DecisionTreeRegressor 预测性能随划分类型的影响 ''' X_train,X_test,y_train,y_test=data splitters=['best','random'] for splitter in splitters: regr = DecisionTreeRegressor(splitter=splitter) regr.fit(X_train, y_train) print("Splitter %s"%splitter) print("Training score:%f"%(regr.score(X_train,y_train))) print("Testing score:%f"%(regr.score(X_test,y_test))) # 调用 test_DecisionTreeRegressor_splitter test_DecisionTreeRegressor_splitter(X_train,X_test,y_train,y_test)
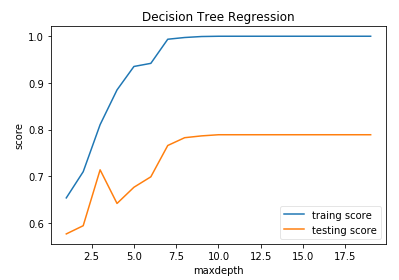
def test_DecisionTreeRegressor_depth(*data,maxdepth): ''' 测试 DecisionTreeRegressor 预测性能随 max_depth 的影响 ''' X_train,X_test,y_train,y_test=data depths=np.arange(1,maxdepth) training_scores=[] testing_scores=[] for depth in depths: regr = DecisionTreeRegressor(max_depth=depth) regr.fit(X_train, y_train) training_scores.append(regr.score(X_train,y_train)) testing_scores.append(regr.score(X_test,y_test)) # 绘图 fig=plt.figure() ax=fig.add_subplot(1,1,1) ax.plot(depths,training_scores,label="traing score") ax.plot(depths,testing_scores,label="testing score") ax.set_xlabel("maxdepth") ax.set_ylabel("score") ax.set_title("Decision Tree Regression") ax.legend(framealpha=0.5) plt.show() # 调用 test_DecisionTreeRegressor_depth test_DecisionTreeRegressor_depth(X_train,X_test,y_train,y_test,maxdepth=20)