# 导入第三方包
import pandas as pd
# 导入数据
Knowledge = pd.read_excel(r'F:\python_Data_analysis_and_mining\11\Knowledge.xlsx')
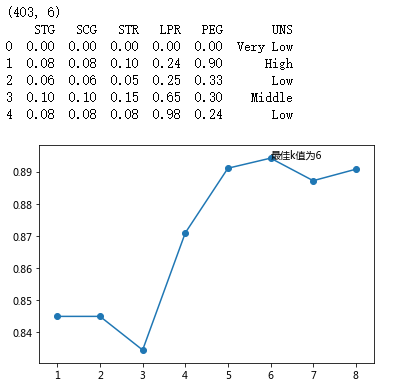
print(Knowledge.shape)
# 返回前5行数据
print(Knowledge.head())
# 构造训练集和测试集
# 导入第三方模块
from sklearn import model_selection
# 将数据集拆分为训练集和测试集
predictors = Knowledge.columns[:-1]
X_train, X_test, y_train, y_test = model_selection.train_test_split(Knowledge[predictors], Knowledge.UNS,
test_size = 0.25, random_state = 1234)
# 导入第三方模块
import numpy as np
from sklearn import neighbors
import matplotlib.pyplot as plt
# 设置待测试的不同k值
K = np.arange(1,np.ceil(np.log2(Knowledge.shape[0])))
k = []
for i in range(len(K)):
k.append(int(K[i]))
K = np.array(k)
# 构建空的列表,用于存储平均准确率
accuracy = []
for k in K:
# 使用10重交叉验证的方法,比对每一个k值下KNN模型的预测准确率
cv_result = model_selection.cross_val_score(neighbors.KNeighborsClassifier(n_neighbors = k, weights = 'distance'),
X_train, y_train, cv = 10, scoring='accuracy')
accuracy.append(cv_result.mean())
# 从k个平均准确率中挑选出最大值所对应的下标
arg_max = np.array(accuracy).argmax()
# 中文和负号的正常显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 绘制不同K值与平均预测准确率之间的折线图
plt.plot(K, accuracy)
# 添加点图
plt.scatter(K, accuracy)
# 添加文字说明
plt.text(K[arg_max], accuracy[arg_max], '最佳k值为%s' %int(K[arg_max]))
# 显示图形
plt.show()
# 重新构建模型,并将最佳的近邻个数设置为6
knn_class = neighbors.KNeighborsClassifier(n_neighbors = 6, weights = 'distance')
# 模型拟合
knn_class.fit(X_train, y_train)
# 模型在测试数据集上的预测
predict = knn_class.predict(X_test)
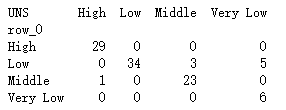
# 构建混淆矩阵
cm = pd.crosstab(predict,y_test)
print(cm)
# 导入第三方模块
import seaborn as sns
from sklearn import metrics
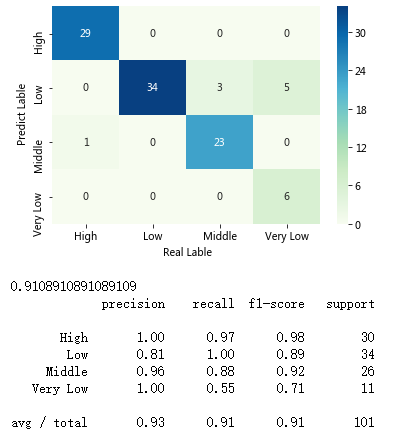
# 将混淆矩阵构造成数据框,并加上字段名和行名称,用于行或列的含义说明
cm = pd.DataFrame(cm)
# 绘制热力图
sns.heatmap(cm, annot = True,cmap = 'GnBu')
# 添加x轴和y轴的标签
plt.xlabel(' Real Lable')
plt.ylabel(' Predict Lable')
# 图形显示
plt.show()
# 模型整体的预测准确率
print(metrics.scorer.accuracy_score(y_test, predict))
# 分类模型的评估报告
print(metrics.classification_report(y_test, predict))
# 读入数据
ccpp = pd.read_excel(r'F:\python_Data_analysis_and_mining\11\CCPP.xlsx')
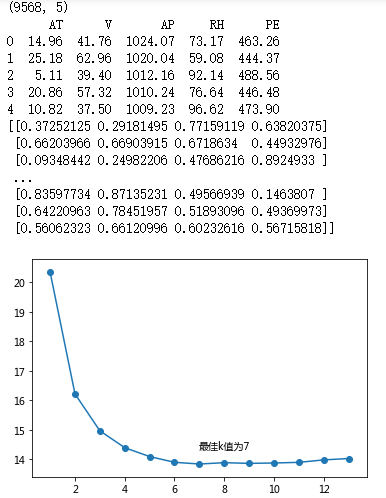
print(ccpp.shape)
print(ccpp.head())
# 导入第三方包
from sklearn import model_selection
from sklearn.preprocessing import minmax_scale
# 对所有自变量数据作标准化处理
predictors = ccpp.columns[:-1]
X = minmax_scale(ccpp[predictors])
print(X)
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, ccpp.PE, test_size = 0.25, random_state = 1234)
# 设置待测试的不同k值
K = np.arange(1,np.ceil(np.log2(ccpp.shape[0])))
k = []
for i in range(len(K)):
k.append(int(K[i]))
K = np.array(k)
# 构建空的列表,用于存储平均MSE
mse = []
for k in K:
# 使用10重交叉验证的方法,比对每一个k值下KNN模型的计算MSE
cv_result = model_selection.cross_val_score(neighbors.KNeighborsRegressor(n_neighbors = k, weights = 'distance'),
X_train, y_train, cv = 10, scoring='neg_mean_squared_error')
mse.append((-1*cv_result).mean())
# 从k个平均MSE中挑选出最小值所对应的下标
arg_min = np.array(mse).argmin()
# 绘制不同K值与平均MSE之间的折线图
plt.plot(K, mse)
# 添加点图
plt.scatter(K, mse)
# 添加文字说明
plt.text(K[arg_min], mse[arg_min] + 0.5, '最佳k值为%s' %int(K[arg_min]))
# 显示图形
plt.show()
# 重新构建模型,并将最佳的近邻个数设置为7
knn_reg = neighbors.KNeighborsRegressor(n_neighbors = 7, weights = 'distance')
# 模型拟合
knn_reg.fit(X_train, y_train)
# 模型在测试集上的预测
predict = knn_reg.predict(X_test)
# 计算MSE值
a = metrics.mean_squared_error(y_test, predict)
print(a)
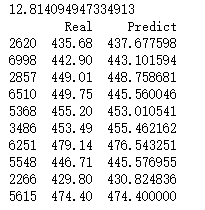
# 对比真实值和实际值
b = pd.DataFrame({'Real':y_test,'Predict':predict}, columns=['Real','Predict']).head(10)
print(b)
# 导入第三方模块
from sklearn import tree
# 预设各参数的不同选项值
max_depth = [19,21,23,25,27]
min_samples_split = [2,4,6,8]
min_samples_leaf = [2,4,8,10,12]
parameters = {'max_depth':max_depth, 'min_samples_split':min_samples_split, 'min_samples_leaf':min_samples_leaf}
# 网格搜索法,测试不同的参数值
grid_dtreg = model_selection.GridSearchCV(estimator = tree.DecisionTreeRegressor(), param_grid = parameters, cv=10)
# 模型拟合
grid_dtreg.fit(X_train, y_train)
# 返回最佳组合的参数值
print(grid_dtreg.best_params_)

# 构建用于回归的决策树
CART_Reg = tree.DecisionTreeRegressor(max_depth = 21, min_samples_leaf = 10, min_samples_split = 6)
# 回归树拟合
CART_Reg.fit(X_train, y_train)
# 模型在测试集上的预测
pred = CART_Reg.predict(X_test)
# 计算衡量模型好坏的MSE值
a = metrics.mean_squared_error(y_test, pred)
print(a)
