内容来自《Hadoop技术内幕:深入解析YARN架构设计与实现原理》第2章:http://book.51cto.com/art/201312/422022.htm
Hadoop版本变迁
当前Apache Hadoop版本非常多,本小节将帮助读者梳理各个版本的特性以及它们之间的联系。在讲解Hadoop各版本之前,先要了解Apache软件发布方式。对于任何一个Apache开源项目,所有的基础特性均被添加到一个称为“trunk”的主代码线(main codeline),当需要开发某个重要的特性时,会专门从主代码线中延伸出一个分支(branch),这被称为一个候选发布版(candidate release),该分支将专注于开发该特性而不再添加其他新的特性,待bug修复之后,经过相关人士投票便会对外公开成为发布版(release version),并将该特性合并到主代码线中。需要注意的是,多个分支可能会同时进行研发,这样,版本高的分支可能先于版本低的分支发布。
由于Apache以特性为准延伸新的分支,故在介绍Apache Hadoop版本之前,先介绍几个独立产生Apache Hadoop新版本的重大特性:
Append:HDFS Append主要完成追加文件内容的功能,也就是允许用户以Append方式修改HDFS上的文件。HDFS最初的一个设计目标是支持MapReduce编程模型,而该模型只需要写一次文件,之后仅进行读操作而不会对其修改,即“write-once-read-many”,这就不需要支持文件追加功能。但随着HDFS变得流行,一些具有写需求的应用想以HDFS作为存储系统,比如,有些应用程序需要往HDFS上某个文件中追加日志信息,HBase需使用HDFS具有 Append功能以防止数据丢失等。
HDFS RAID:Hadoop RAID模块在HDFS之上构建了一个新的分布式文件系统DistributedRaidFileSystem(DRFS),该系统采用了Erasure Codes增强对数据的保护,有了这样的保护,可以采用更低的副本数来保持同样的可用性保障,进而为用户节省大量存储空间。
Symlink:让HDFS支持符号链接。符号链接是一种特殊的文件,它以绝对或者相对路径的形式指向另外一个文件或者目录(目标文件),当程序向符号链接中写数据时,相当于直接向目标文件中写数据。
Security:Hadoop的HDFS和MapReduce均缺乏相应的安全机制,比如在HDFS中,用户只要知道某个block的blockID,便可以绕过NameNode直接从DataNode上读取该block,用户可以向任意DataNode上写block;在MapReduce中,用户可以修改或者杀掉任意其他用户的作业等。为了增强Hadoop的安全机制,从2009年起,Apache专门抽出一个团队,从事为Hadoop增加基于Kerberos和Deletion Token的安全认证和授权机制的工作。
MRv1:正如前面所述,第一代MapReduce计算框架由三部分组成:编程模型、数据处理引擎和运行时环境。其中,编程模型由新旧API两部分组成;数据处理引擎由MapTask和ReduceTask组成;运行时环境由JobTracker和TaskTracker两类服务组成。
MRv2/YARN:MRv2是针对MRv1在扩展性和多框架支持等方面的不足而提出来的,它将MRv1中的JobTracker包含的资源管理和作业控制两部分功能拆分开来,分别将由不同的进程实现。考虑到资源管理模块可以共享给其他框架使用,MRv2将其做成了一个通用的YARN系统,YARN系统的引入使得计算框架进入了平台化时代。
NameNode Federation:针对Hadoop 1.0中NameNode内存约束限制其扩展性问题提出的改进方案,它使NameNode可以横向扩展成多个,其中,每个NameNode分管一部分目录,这不仅使HDFS扩展性得到增强,也使HDFS具备了隔离性。
NameNode HA:大家都知道,HDFS NameNode存在NameNode内存约束限制扩展性和单点故障两个问题,其中,第一个问题通过NameNode Federation方案解决,而第二个问题则通过NameNode热备方案(NameNode HA)实现。
到2013年8月为止,Apache Hadoop已经出现四个大的分支,如图2-5所示。
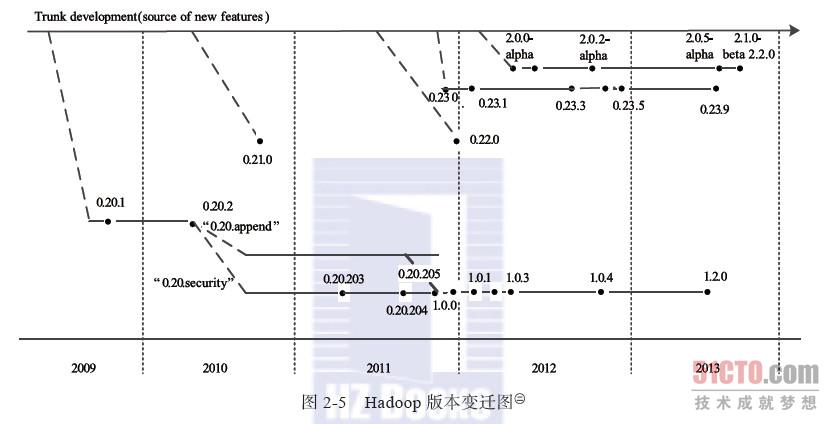
Apache Hadoop的四大分支构成了三个系列的Hadoop版本。
(1)0.20.X系列
0.20.2版本发布后,几个重要的特性没有基于trunk而是在0.20.2基础上继续研发。值得一提的主要有两个特性:Append与Security。其中,含Security特性的分支以0.20.203版本发布,而后续的0.20.205版本综合了这两个特性。需要注意的是,之后的1.0.0版本仅是0.20.205版本的重命名。0.20.X系列版本是最令用户感到疑惑的,因而它们具有的一些特性,trunk上没有,反之trunk上有的一些特性0.20.X系列版本却没有。
(2)0.21.0/0.22.x系列
这一系列版本将整个Hadoop项目被分割成三个独立的模块,分别是 Common、HDFS和MapReduce。HDFS和MapReduce都对Common模块有依赖,但是MapReduce对HDFS并没有依赖,这样,MapReduce可以更容易运行在其他的分布式文件系统之上,同时,模块间可以独立开发。具体各个模块的改进如下:
Common模块:最大的新特性是在测试方面添加了Large-Scale Automated Test Framework和fault injection framework。
HDFS模块:主要增加的新特性包括支持追加操作与建立符号连接、Secondary NameNode改进(secondary namenode被剔除,取而代之的是checkpoint node同时添加一个backup node的角色,作为NameNode的冷备)、允许用户自定义block放置算法等。
MapReduce模块:在作业API方面,开始启动新MapReduce API,但仍然兼容老的API。
0.22.0在0.21.0基础上修复了一些bug并进行了部分优化。
(3)0.23.X系列
0.23.X是为了克服Hadoop在扩展性和框架通用性方面的不足而提出来的,它包括基础库Common、分布式文件系统HDFS、资源管理框架YARN和运行在YARN上的MapReduce四部分,其中,新增的可对接入的各种计算框架(如MapReduce、Spark等)进行统一管理,该发行版自带MapReduce库,而该库集成了迄今为止所有的MapReduce新特性。
(4)2.X系列
同0.23.x系统一样,2.X系列属于下一代Hadoop,与0.23.X相比,2.X增加了NameNode HA和Wire-compatibility等新特性。
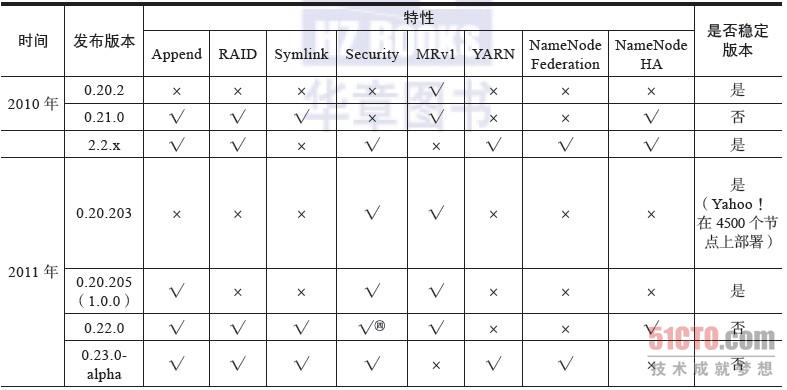
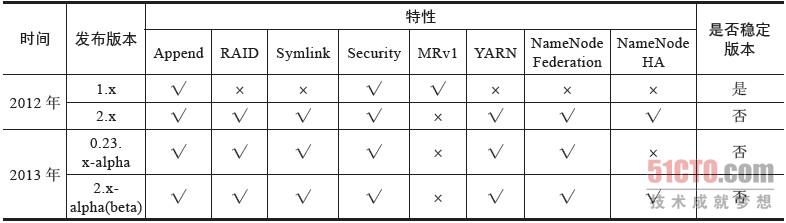
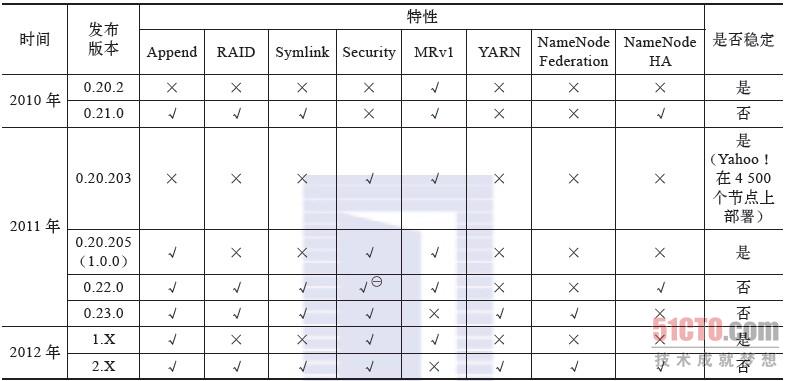
表2-1总结了Hadoop各个发布版的特性以及稳定性。
表2-1 Hadoop各个发布版特性以及稳定性
(2)
本书介绍的Hadoop YARN设计思想适用于所有Apache Hadoop 2.x版本,但涉及具体的体现(指源代码级别的实现)时,则以Apache Hadoop 2.2.0及更高稳定版本为主。
《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》第2章:http://book.51cto.com/art/201312/422133.htm
Hadoop版本变迁
到2012年5月为止,Apache Hadoop已经出现四个大的分支,如图2-1所示。
Apache Hadoop的四大分支构成了四个系列的Hadoop版本。
1. 0.20.X系列
0.20.2版本发布后,几个重要的特性没有基于trunk而是在0.20.2基础上继续研发。值得一提的主要有两个特性:Append与Security。其中,含Security特性的分支以0.20.203版本发布,而后续的0.20.205版本综合了这两个特性。需要注意的是,之后的1.0.0版本仅是0.20.205版本的重命名。0.20.X系列版本是最令用户感到疑惑的,因为它们具有的一些特性,trunk上没有;反之,trunk上有的一些特性,0.20.X系列版本却没有。
2. 0.21.0/0.22.X系列
这一系列版本将整个Hadoop项目分割成三个独立的模块,分别是 Common、HDFS和MapReduce。HDFS和MapReduce都对Common模块有依赖性,但是MapReduce对HDFS并没有依赖性。这样,MapReduce可以更容易地运行其他分布式文件系统,同时,模块间可以独立开发。具体各个模块的改进如下。
Common模块:最大的新特性是在测试方面添加了Large-Scale Automated Test Framework和Fault Injection Framework。
HDFS模块:主要增加的新特性包括支持追加操作与建立符号连接、Secondary NameNode改进(Secondary NameNode被剔除,取而代之的是Checkpoint Node,同时添加一个Backup Node的角色,作为NameNode的冷备)、允许用户自定义block放置算法等。
MapReduce模块:在作业API方面,开始启动新MapReduce API,但老的API仍然兼容。
0.22.0在0.21.0的基础上修复了一些bug并进行了部分优化。
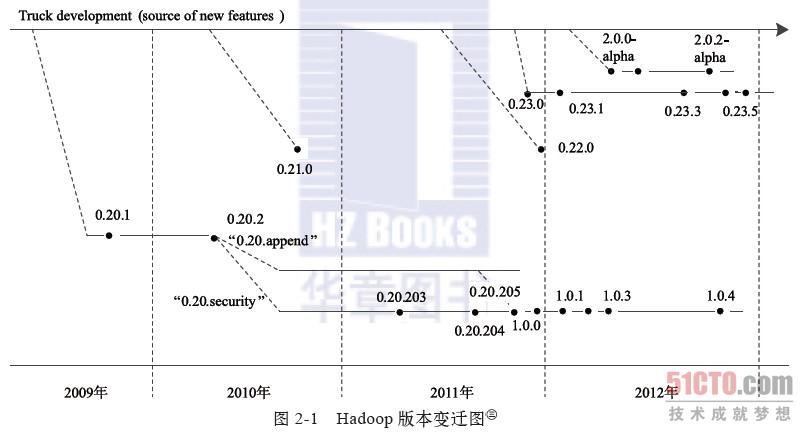
3. 0.23.X系列
0.23.X是为了克服Hadoop在扩展性和框架通用性方面的不足而提出来的。它实际上是一个全新的平台,包括分布式文件系统HDFS Federation和资源管理框架YARN两部分,可对接入的各种计算框架(如MapReduce、Spark等)进行统一管理。它的发行版自带MapReduce库,而该库集成了迄今为止所有的MapReduce新特性。
4. 2.X系列
同0.23.X系列一样,2.X系列也属于下一代Hadoop。与0.23.X系列相比,2.X系列增加了NameNode HA和Wire-compatibility等新特性。
表2-1总结了Hadoop各个发布版的特性以及稳定性。
表2-1 Hadoop各个发布版的特性以及稳定性
本书之所以以分析Apache Hadoop 1.0.0为主,主要是因为这是一个稳定的版本,再有其为1.0.0,具有里程碑意义。Apache发布这个版本,也是希望该版本成为业界的规范。需要注意的是,尽管本书以分析Apache Hadoop 1.0.0版本为主,但本书内容适用于所有Apache Hadoop 1.X版本。