本文试着以例子的方式来演示List Series DataFrame Dict 在使用中的基本操作。
dataframe是pandas的数据类型;
ndarray(数组对象)是numpy的数据类型;是一个多维数组对象,该对象由两部分组成:1 实际的数据;2 描述这些数据的元数据。
list和dict是python的数据类型;
series是pandas的一种数据类型,Series是一个定长的,有序的字典,因为它把索引和值映射起来了。
通过以下例子,可以更加清楚它们的数据表示。
一,数据用例代码
首先,建立需要的数据:
import numpy as np
import pandas as pd
from pandas import *
from numpy import *
data = DataFrame(np.arange(16).reshape(4,4),index = list('ABCD'),columns=list('wxyz'))
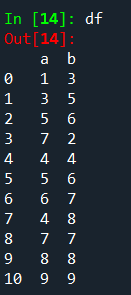
df = pd.DataFrame({'a':[1,3,5,7,4,5,6,4,7,8,9], 'b':[3,5,6,2,4,6,7,8,7,8,9]})
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo'],'value': [1, 2, 3, 5]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'],'value': [5, 6, 7, 8]})
data:

df:
df1:

df2

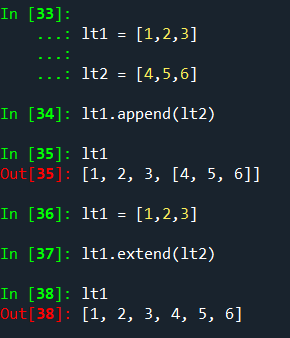
二,列表内置的方法

列表的append和extend的区别:
三,字典内置的方法
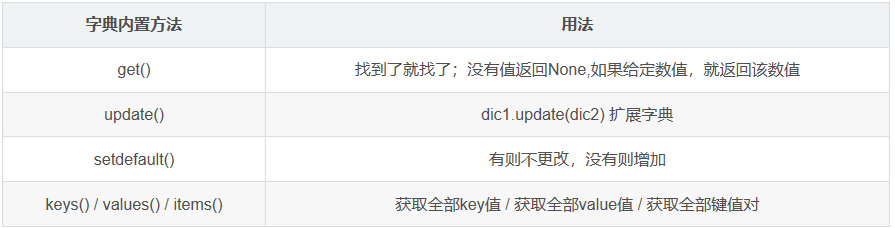
字典内置方法
按key取值 / 按key修改值 / 按key增加值
dic = {'a':1, 'b':2, 'c':3}
print(dic['a']) # 1
dic['a'] = dic['a'] + 9
print(dic) # {'a': 10, 'b': 2, 'c': 3}
dic['d'] = 666
print(dic) # {'a': 10, 'b': 2, 'c': 3, 'd': 666}
成员运算(比较的是key)
dic = {'a':1, 'b':2, 'c':3}
print('name' in dic) # False
for循环(对key循环)
dic = {'a':1, 'b':2, 'c':3}
for i in dic:
print(i)
# 打印结果:
a
b
c
keys() / values() / items()
dic = {'a':1, 'b':2, 'c':3}
print(dic.keys()) # 获取所有key值 dict_keys(['a', 'b', 'c'])
print(dic.values()) # 获取所有value值 dict_values([1, 2, 3])
print(dic.items()) # 获取所有键值对 dict_items([('a', 1), ('b', 2), ('c', 3)])
get() 取值
dic = {'a':1, 'b':2, 'c':3}
print(dic.get('a')) # 取得1
print(dic.get('qq')) # 字典中没有要找的key值,则返回None
# 打印:None
print(dic.get('qq', 66)) # 字典中没有要找的key值,又给定数值,则返回该数值
# 打印:66
update() 扩展字典
dic1 = {'a':1}
dic2 = {'b':2}
dic1.update(dic2)
print(dic1)
# 打印结果:
{'a': 1, 'b': 2}
setdefault() 有则不更改,没有则增加
dic = {'a':1, 'b':2}
dic.setdefault('a',2)
print(dic) # {'a': 1, 'b': 2}
dic.setdefault('c', 9)
print(dic) # {'a': 1, 'b': 2, 'c': 9}
通过fromkeys快速生成字典:fromkeys(seq,value)
1、说明:
指定key值和value值,快速生成字典,其中, seq -- 字典键值列表。 value -- 可选参数, 设置键序列(seq)的值
>>> sd = {}
>>> d = ["q","w","e"]
>>> sd.fromkeys(d,1)
{'q': 1, 'w': 1, 'e': 1}
2、细节
(1)注意:value值为序列的效果
>>> sd = {}
>>> d = ["q","w","e"]
>>> v = [1,2,3]
>>> sd.fromkeys(d,v)#value值为序列的效果
{'q': [1, 2, 3], 'w': [1, 2, 3], 'e': [1, 2, 3]}
(2)多次赋值时,不会追加,会覆盖
>>> d = {"s":6}
>>> s = ["q","w","e"]
>>> d = d.fromkeys(s,1)#多次赋值操作
>>> print(d)#会将原来的值覆盖
{'q': 1, 'w': 1, 'e': 1}
3、实例:
一个函数传入一个List列表,生成一个字典:所有元素作为字典的key
正确写入:
>>> def func(L):
... d_result = {}
... for i in l:
... d_result = d_result.fromkeys(L,1)#要有变量赋值,否则结果会为空
... return d_result
...
>>> s = ["q","w","e"]
>>> func(s)
{'q': 1, 'w': 1, 'e': 1}
Series/ndarray/list/DataFrame/Dict相互转化
(一)序列 Series
Series <--> DataFrame
dataframe = pd.DataFrame({"XXX1":series1,"XXX2":series2})
series = dataframe[0] #无标签时
series = dataframe["XXX"] #有标签时
Serise <--> ndarray
series = pd.Series(ndarray) #这里的ndarray是1维的
ndarray = np.array(series)
ndarray = series.values
Series <--> list
series = pd.Series(list)
list = series.tolist()
list = list(series)
Series <--> dict
series = pd.Series(dict)
dict = series.to_dict()
(二) DataFrame
DataFrame <--> ndarray
ndarray = dataframe.values
dataframe = pd.DataFrame(ndarray)
DataFrame <--> list
list = dataframe.values.tolist()
dataframe = pd.DataFrame(list)
import pandas as pd
df = pd.DataFrame({'a':[1,3,5,7,4,5,6,4,7,8,9], 'b':[3,5,6,2,4,6,7,8,7,8,9]})
df['a'].values.tolist()
[1, 3, 5, 7, 4, 5, 6, 4, 7, 8, 9]
or you can just use
df['a'].tolist()
[1, 3, 5, 7, 4, 5, 6, 4, 7, 8, 9]
To drop duplicates you can do one of the following:
df['a'].drop_duplicates().values.tolist()
[1, 3, 5, 7, 4, 6, 8, 9]
list(set(df[‘a’])) # as pointed out by EdChum
[1, 3, 4, 5, 6, 7, 8, 9]
convert df to list[list]
df.values.tolist()
conver series to list
Series.tolist()
DataFrame <--> dict
dataframe = pd.DataFrame.from_dict({0:dict1, 1:dict2})
dataframe = pd.DataFrame(dict)
dict = dataframe.to_dict()
dict = dataframe[['key_col', 'value_col']].set_index('key_col').to_dict()
(dict = dict['value_col'])
(三) 其它 list
dict --> list
list = dict.values() # list of values
list = dict.keys() # list of keys
list = list(dict) # list of keys
ndarray <--> list
list = ndarray.tolist()
ndarray = np.array(list)
tuple <--> list
list = list(tuple)
tuple = tuple(list)
Index --> list
dataframe.columns.tolist()
字典的练习题
- 有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中
即: {'k1': 大于66的所有值, 'k2': 小于66的所有值}
lt = [11,22,33,44,55,66,77,88,99,90]
dic = {'k1': [], 'k2': []}
for i in lt:
if i > 66:
dic['k1'].append(i)
else:
dic['k2'].append(i)
print(dic)
2.统计s='hello alex alex say hello sb sb'中每个单词的个数
结果如:{'hello': 2, 'alex': 2, 'say': 1, 'sb': 2}
s = 'hello alex alex say hello sb sb'
dic = {}
for i in s.split():
dic.setdefault(i,s.count(i))
print(dic)
- 写代码,有如下变量,请按照要求实现每个功能 name = " aleX"
- 移除 name 变量对应的值两边的空格,并输出处理结果
name = " aleX"
print(name.strip())
- 判断 name 变量对应的值是否以 "al" 开头,并输出结果
print(name.startswith('a1'))
- 判断 name 变量对应的值是否以 "X" 结尾,并输出结果
print(name.endswith('X'))
- 将 name 变量对应的值中的 “l” 替换为 “p”,并输出结果
print(name.replace('l', 'p'))
- 将 name 变量对应的值根据 “l” 分割,并输出结果。
print(name.split('l'))
- 请输出 name 变量对应的值的第 2 个字符?
print(name[1])
- 请输出 name 变量对应的值的前 3 个字符?
print(name[0:3])
- 请输出 name 变量对应的值的后 2 个字符?
print(name[3:])
- 请输出 name 变量对应的值中 “e” 所在索引位置?
print(name.find('e'))
- 获取子序列,去掉最后一个字符。如: oldboy 则获取 oldbo。
s = 'oldboy'
print(s.rstrip('y'))
参考资料
pandas入门
https://pda.readthedocs.io/en/latest/chp5.html
pandas.DataFrame.merge 用法的官方文档
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.merge.html
dataframe = pd.DataFrame.from_dict()具体参数请参考文档:
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.from_dict.html
dict = dataframe.to_dict()具体参数请参考文档:
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_dict.html
List, Dict, Array, Series, DataFrame 相互转换
https://yam.gift/2017/02/15/2017-02-15-list-dict-series-dataframe-ndarray-transform/