楔子
PostgreSQL号称是世界上最先进的开源关系数据库,它的优化器虽然比不上商业数据库的优化器那样复杂,但对于大部分用户来说,已经比较晦涩难懂。如果搞一个投票来评选数据库中最难以理解的模块,那么非优化器莫属。在使用 PostgreSQL 数据库的过程中,你可能会遇到下面这些问题:
在你遇到一个比较糟糕的执行计划时,你是否有能力对其进行改造?当你遭遇一个莫名的慢查询时,你是否能够通过优化实现方法提升性能?当你创建的索引不为优化器所用时,你是否清楚地知道优化器的选择习性?你是否想通过等价改写一个 SQL 语句来改变执行计划,那等价改写 SQL 语句是否隐藏着某些规则?
优化器是数据库的大脑。作为经常使用数据库的后端程序猿,你是否想知道数据库的大脑在思考些什么?反之,如果对优化器不够了解,便如同猛虎没有了利爪、苍鹰没有了翅膀,在使用数据库的过程中往往心有余而力不足。因此今天我们明知山有虎,偏向虎山行,拿出愚公移山的精神,把优化器的知识消化掉。
逻辑优化
查询优化器的基本原理
让我们用一个故事来说明什么是查询优化器吧
有一个名叫雾雨魔理沙的美少女,它今年考进了地灵殿这所大学,地灵殿今年开设了数据库原理课。魔理沙对查询优化的内容不是很理解,虽然已经使出了洪荒之力,仍觉得部分原理有些晦涩难懂,于是打算问一下地灵殿的校长: 古明地觉。
古明地觉曾经是一名资深的数据库内核开发老码农,但是由于常年担任地灵殿大学的校长,很多知识都已经渐渐遗忘了。但为了避免尴尬,古明地觉决定温习一下,拿出了好多年不看的《数据库系统实现》啃了起来。
魔理沙见到了古明地觉校长,并提出了她的第一个问题: "为什么数据库要进行查询优化?"
古明地觉聊了一下额前的粉色秀发,慢条斯理的说:"不止是数据库要进行优化,你在编译 C 语言程序的时候,也可以通过编译选项 -o 来指定进行哪个级别的优化,只是查询数据库的查询优化和 C 语言的优化还有些区别。"
"什么区别呢?",魔理沙晃了晃她那充满问号的小脑袋再次提问,瞳孔里闪烁着小星星。古明地觉露出了一副宠溺的表情,继续答道: "C 语言是过程化语言,已经指定好了需要执行的每一个步骤;但 SQL 是描述性语言,只指定了 WHAT,而没有指定 HOW。这样它的优化空间就大了,你说是不是?"
魔理沙点了点头回答: "对,也就是说条条大路通罗马,它比过程语言的选择更多,是不是这样?"。古明地觉笑道: "孺子可教也,不过虽然我们知道它的优化空间大,但具体如何优化呢?"
说罢,古明地觉将身子向沙发一靠,翘上二郎腿继续说:"通常来说分成两个层面,一个是基于规则的优化,另一个是基于代价的优化。基于规则的优化也可以叫逻辑优化(或者规则优化),基于代价的优化也可以叫物理优化(或者代价优化)。"
听罢,魔理沙又提出了第二个问题: "为什么要进行这样的区分呢?优化就优化嘛,何必还分什么规则和代价呢?"
"是否对优化进行区分不是重点,有些优化器层次分得清楚些,有些优化器层次分得就不那么清楚,都只是优化手段而已",说到这里,校长古明地觉显得有点心虚,再这么问下去恐怕要被问住,于是试图引开话题:"我们继续说说 SQL 语言吧,我们说它是一种介于关系演算和关系代数之间的语言,关系演算和关系代数你看过吧?"
魔理沙想了想,好像上课时老师说过关系代数,但没有说关系演算,于是说:"接触过一点,但不是特别明白"。古明地觉得意地说:"关系演算是纯描述性的语言,而关系代数呢,则包含了一些基本的关系操作,SQL 主要借鉴的是关系演算,也包含了关系代数的一部分特点。"
古明地觉看魔理沙有些懵逼,顿了一下继续说道:"上课的时候老师有没有说过关系代数的基本操作?"。魔理沙想了想: "好像说了,有投影(SELECT)、选择(WHERE)、连接、并集、差集这几个"。古明地觉点了点头: "对,还有一个叫重命名的,一共 6 个基本操作。另外,结合实际应用在这些基本操作之上又扩展出了外连接、半连接、聚合操作、分组操作等。"
古明地觉继续回答: "SQL 语句虽然是描述性的,但是我们可以把它转化成一个关系代数表达式。而关系代数中呢,又有一些等价的规则,这样我们就能结合这些等价规则对关系代数表达式进行等价的转换。"
此时,魔理沙虽然渐渐有点豁然开朗了,但又提出了第三个问题: "进行等价转换的目的是找到性能更好的代数表达式吧?"
"对,就是这样",古明地觉投去赞许的目光。
"那么如何确定等价变换之后的表达式就能变得比之前性能更好呢?或者说为什么要进行这样的等价变换,而不是使用原来的表达式呢?"
古明地觉愣了一下,显然她没有想到魔理沙会提出这样的问题,但是基于自己多年的忽悠经验,他定了定神,回答道: "这既有经验的成分,也有量化的考虑。例如,将选择操作下推,就能优先过滤数据,那么表达式的上层计算结点就能降低计算量,因此很容易可以知道是能降低代价的。再例如,我们通常会对相关的子查询进行提升,这是因为如果不提升这种子查询,那么它执行的时候就会产生一个嵌套循环。这种嵌套循环的执行代价是 O(N^2),这种复杂度已经是最坏的情况了,提升上来至少不会比它差,因此提升上来是有价值的。"古明地觉心里对自己的临危不乱暗暗点了个赞。
古明地觉看魔理沙没有提问,继续说道:"这些基于关系代数等价规则做等价变换的优化,就是基于规则的优化。当然数据库本身也会结合实际的经验,产生一些优化规则,比如外连接消除,因为外连接优化起来不太方便,如果能把它消除掉,我们就有了更大的优化空间,这些统统都是基于规则的优化。同时这些都是建立在逻辑操作符上的优化,这也是为什么基于规则的优化也叫做逻辑优化。"
魔理沙想了想,发现自己好像对逻辑操作符不太理解,连忙问第四个问题: "逻辑操作符是啥?既然有物理优化,难道还有物理操作符吗?"
古明地觉了个懒腰继续说:"比如说吧,你在 SQL 语句里写上了两个表要做一个左外连接,那么数据库怎么来做这个左外连接呢?"
魔理沙一头雾水地摇摇头,向古明地觉露出了期待的眼神。
古明地觉继续说道: "数据库表示,臣妾也无能为力呀,你说的左外连接意思我懂,但我也不知道怎么实现啊?你需要告诉我实现方法啊。因此优化器还承担了一个任务,就是告诉执行器,怎么来实现一个左外连接。"
"数据库有哪些方法来实现一个做外连接呢?它可以用嵌套循环连接、哈希连接、归并连接等。注意了,重要的事情说三遍,你看内连接、外连接是连接操作,嵌套循环连接、归并连接等也叫连接,但内连接、外连接这些就是逻辑操作符,而嵌套循环连接、归并连接这些就是物理操作符。因此,你说对了,物理优化就是建立在物理操作符上的优化。"
古明地觉:"现在让你从地灵殿出发去博丽神社,你会怎么去?"
魔理沙:"baka⑨目前在地灵殿打工,我可以骑baka⑨过去啊。"
古明地觉:"你自己先走到红魔馆,然后再从红魔馆走到博丽神社怎么样?这样也可以过去啊。"
魔理沙:"有点扎心了,这不是吃饱了撑的吗?"
古明地觉:"为什么?"
魔理沙:"很明显,我骑baka⑨一下子就飞去了,不香吗?我为啥要专门先到红魔馆再到博丽神社,还是用走的,脑子瓦特了?"
古明地觉笑了笑:"不知不觉之间,你的大脑就建立了一个代价模型,那就是性价比。优化器作为数据库的大脑,也需要建立代价模型,对物理操作符计算代价,然后筛选出最优的物理操作符来。因此,基于代价的优化是建立在物理操作符上的优化,所以也叫物理优化。"
魔理沙似乎懂了: "校长您让我去博丽神社就是一个逻辑操作符,它和我们写一个 SQL 语句要求数据库对两个表做左外连接类似;而去博丽神社的实际路径有很多种,这些就像是物理操作符,我们对这些实际的物理路径计算代价之后,就可以选出来最好的路径了。"
古明地觉掏出手机,分别打开了两个不同的地图App,输入了从地灵殿到博丽神社的信息,然后拿给魔理沙看。魔理沙发现两个 App 给出的最优路径是不一样的,若有所思的说: "看来代价模型很重要,代价模型是不是准确决定了最优路径选择得是否准确?"
古明地觉拍了拍魔理沙的屁股,笑着说: "太对了,所以我作为一个数据库内核的资深开发人员,需要不断地调整优化器的代价模型,以期望获得一个相对稳定的代价模型,不过仍然是任重道远啊。"
说罢,古明地觉一把抱起妹妹古明地恋,舌头在她的嘴巴里肆意地舞动着,然后走进了自己的闺房。留下魔理沙一人在原地一脸懵逼,不知所措。。。

关于语法树
听了校长古明地觉对查询优化器基本原理的讲解,魔理沙在学校的数据库原理课堂上顺风顺水,每天吃饭睡觉打豆豆,日子过得非常悠哉。不过眼看就到了数据库原理实践课,老师给出的题目是分析一个数据库的某一模块的实现。魔理沙千挑万选,终于选定了要分析 PostgreSQL 数据库的查询优化器的实现,据说 PostgreSQL 数据库的查询优化器层(相)次(当)清(复)晰(杂),具有教科书级的示范作用。
可是当魔理沙下载了 PostgreSQL 数据库的源代码,顿时就懵圈了,虽然平时理论说得天花乱坠,但到了实践的时候却发现,理论和实际对应不上。魔理沙深深陷入代码细节中不可自拔,查阅了好多资料,结果是读破书万卷,下笔如有锤,一点进展都没有。于是魔理沙又想到了与 PostgreSQL 有着不解之缘的校长古明地觉,想必他一定能站得更高,看得更远,于是魔理沙骑着baka⑨再次去拜访校长古明地觉。
魔理沙找到刚和妹妹行完咸湿之事、气喘吁吁、大汗淋漓的校长古明地觉,意味深长的说:"PostgreSQL 的查询优化器功能比较多,恐怕一次说不完,我们分成几次来说清楚吧。"
魔理沙表示:"的确是,我在看查询优化器代码的时候觉得无从下手。虽然一些理论学过了,但不知道代码和理论如何对应,而且还有一些优化规则好像我们讲数据库原理的时候没有涉及,毕竟理论和实践之间还是有一些差距。"
PostgreSQL 查询执行的基本流程
校长古明地觉打开电脑,调出 PostgreSQL 的代码说:"我们先来看一下 PostgreSQL 一个查询执行的基本流程。"然后调出了一张图。
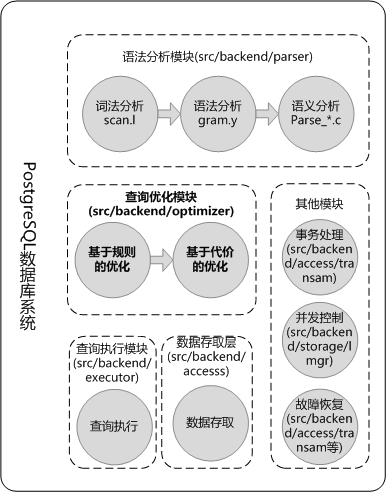
"这张图是我自己画的,这种图已经成了优化器培训开篇的必备图了,我们有必要借助这张图来看一下 PostgreSQL 源码的大体结构,了解查询优化器所处的位置。"古明地觉一边指点着电脑屏幕,一边继续说:"我们要执行一条 SQL 语句,首先会进行词法分析,也就是说把 SQL 语句做一个分割,分成很多小段段……,这每一个小段也叫作一个token"。魔理沙连忙抢答:"我们在学编译原理的时候老师说了,分成的小段段可以是关键字、标识符、常量、运算符和边界符,是不是分词之后就会给这些小段段赋予这些语义?"
"对的!看来你对《编译原理》的第 1 章很熟悉嘛",古明地觉笑着说。
"当然,我最擅长写 Hello World",魔理沙害羞地挠了挠头。
"好吧,Let’s 继续,PostgreSQL 的分词是在 scan.l 文件中完成的。它可能分得更细致一些,比如常量它就分成了 SCONST、FCONST、ICONST 等,不过基本的原理是一样的。进行分词并且给每个单词以语义之后,就可以去匹配 gram.y 里的语法规则了。gram.y 文件里定义了所有的 SQL 语言的语法规则,我们的查询经过匹配之后,最终形成了一颗语法树"
"语法树?我还听过什么查询树、计划树,这些树要怎么区分呢?",魔理沙红着脸,一脸娇嗔的问道。因为她发现校长的手此时正在自己的股间上下游动,宛如在抚摸一座上好的美玉一般。
"一个查询语句在不同的阶段,生成的树是不同的,这些树的顺序应该是先生成语法树,然后得到查询树,最终得到计划树,计划树就是我们说的执行计划"
"那为什么要做这些转换呢?",魔理沙不解地问。
"我们通过词法分析、语法分析获得了语法树,但这时的语法树还和 SQL 语句有很紧密的关系。比如我们在语法树中保存的还是一个表的名字,一个列的名字,但实际上在 PostgreSQL 数据库中,有很多系统表,比如 PG_CLASS 用来将表保存成数据库的内部结构。当我们创建一个表的时候,会在 PG_CLASS、PG_ATTRIBUTE 等系统表里增加新的元数据,我们要用这些元数据的信息取代语法树中表的名字、列的名字等。"
魔理沙想了想,说:"这个取代的过程就是语义分析?这样就把语法树转换成了查询树,而查询树是使用元数据来描述的,所以我们在数据库内核中使用它就更方便了?"
看着魔理沙迷离的眼神,古明地觉继续说:"我们可以把查询树认为是一个关系代数表达式。"
魔理沙定了定神,问道:"关系代数表达式?上次我问你查询优化原理的时候你是不是说基于规则的优化就是使用关系代数的等价规则对关系代数表达式进行等价变换,所以查询优化器的工作就是用这个查询树做等价变换?"
"恭喜你,答对了",古明地觉暗暗赞许魔理沙的理解力和记忆力,继续说:"我们在得到查询树的时候,理论上已经可以了,但是还不完美,我们还要将查询树输入到查询优化器中,经过逻辑优化(规则优化)和物理优化(代价优化),最终得到一颗最优的查询树。而我们要做的,就是查看查询优化器如何产生这颗最优的计划树。"
魔理沙恍然大悟:"oh~,意思就是我们先经过分词,得到一个个的小段段、也就是token,然后对这些token建立一个语法树,然后再对语法树进行语义分析,也就是使用PostgreSQL内部的元数据对语法树中表名、列名进行替换,从而得到查询树。尽管此时查询树理论上已经可以执行了,但它不是最优解,我们还要经过一些之前说的优化,然后得到一个最优计划树。这个计划树,才是最终执行的。"
古明地觉吻了魔理沙的嘴巴,回答她:"恭喜你,答对了"。
逻辑优化示例
午饭过后,古明地觉一个地灵殿公园的长椅上抽起了烟,魔理沙好奇的看着她并问道:"我在其它地方看到有些爷爷抽的是自己种的烟叶,自给自足还省钱。你现在抽的烟和那些爷爷自己用烟叶卷的烟,之间有什么区别呢?"
"自己种的烟叶直接用报纸卷了抽,没有过滤嘴,会吸入有害颗粒物,而且烟叶的味道也不如现在改进的香烟",说到这里古明地觉好像想到了什么,继续说:"这就像是查询优化器的逻辑优化,查询树输入之后,需要进行持续的改进。无论是自己用报纸卷的烟,还是在超市买的成品烟,都是香烟,但是通过改进之后,香烟的毒害作用更低、香型更丰富了。逻辑优化也是这个道理,通过改进查询树,能够得到一个更好的计划树"
"那逻辑优化是如何在已有的查询树上增加香型的呢?"
古明地觉:"我总结,PostgreSQL 在逻辑优化阶段有这么几个重要的优化——子查询 & 子连接提升、表达式预处理、外连接消除、谓词下推、连接顺序交换、等价类推理"。然后又抽了一口烟,接着说:"从代码逻辑上来看,我们还可以把子查询 & 子连接提升、表达式预处理、外连接消除叫做逻辑重写优化,因为他们主要是对查询树进行改造。而后面的谓词下推、连接顺序交换、等价类推理则可以称为逻辑分解优化,他们已经把查询树蹂躏得不成样子了,已经到了看香烟不是香烟的地步了"
古明地觉:"我总结,PostgreSQL 在逻辑优化阶段有这么几个重要的优化——子查询 & 子连接提升、表达式预处理、外连接消除、谓词下推、连接顺序交换、等价类推理"。然后又抽了一口烟,接着说:"从代码逻辑上来看,我们还可以把子查询 & 子连接提升、表达式预处理、外连接消除叫做逻辑重写优化,因为他们主要是对查询树进行改造。而后面的谓词下推、连接顺序交换、等价类推理则可以称为逻辑分解优化,他们已经把查询树蹂躏得不成样子了,已经到了看香烟不是香烟的地步了"
"可是我们的数据库原理课上并没有说有逻辑重写优化和逻辑分解优化啊。"
"嗯,是的,这是我根据 PostgreSQL 源代码的特征自己总结的,不过它能比较形象地将现有的逻辑优化区分开来,这样就能更好地对逻辑优化进行提炼、总结、分析"。古明地觉想了一下觉得如果把所有的逻辑优化规则都说完有点多,于是对小明说:"我们就从中挑选一两个详细说明吧,我们就借用关系代数表达式来说一下谓词下推和等价类推理吧。"
魔理沙想了想说:"选择下推和等价类是逻辑分解优化中的内容了,可是逻辑重写优化里还有子查询提升、表达式预处理、外连接消除这些大块头你还没有给我讲解过呀。"
古明地觉表示:"这些先留给你自己去理解,如果理解不了再来找我吧。逻辑优化的规则实际上还是比较多的,但可以逐个击破,也就是他们之间通常而言并没有多大的关联。当然最后,这些东西我都会慢慢地告诉你。"
魔理沙问:"选择下推是为了尽早地过滤数据,这样就能在上层结点降低计算量,是吧?"
"是的",古明地觉点了点头,"还是通过SQL语句来说明一下吧,顺便我们把等价类推理也说一说。比如说有两张表,一张教师表(teacher)、一张课程表(course),教师表里面保存了教师的id和姓名,课程表里面保存了教师的id和课程的名字。如果我们想要获得编号为 5 的老师的姓名、以及承担的所有课程名字,我们可以这么写:"
select t.t_name, c.c_names
from teacher as t, course as c
where t.t_id = 5 and t.t_id = c.t_id
"魔理沙,你看这个关系代数表达式怎么下推选择操作?"
魔理沙看着关系代数表达式思考了一会,说:"我看这个t.t_id = 5比较可疑,因为这是先对teacher表和course表做笛卡尔积,然后选择t_id=5的。如果我能将t_id=5先作用在teacher表、过滤掉一部分数据,这样笛卡尔积产生的数据会少很多,因为此时只是teacher表中t_id=5的记录和course表做笛卡尔积,而不是全部记录"。说罢,魔理沙敲出了将t_id=5下推之后的SQL语句
select t.t_name, c.c_names
from course as c, (select * from teacher where t_id=5) as t
where t.t_id = c.t_id
古明地觉说:"对,你这样下推下来的确能降低计算量。那你再看看,既然下推这么好,是不是投影也能下推?",魔理沙看了一下,发现只需要对 cname 进行投影,顿时想到了,course表虽然有t_id、c_id、c_names三个列,但是我们只需要使用 c_names 就够了嘛,于是魔理沙在电脑上敲了投影下推的关系代数表达式。
select t.t_name, c.c_names
from (select c_names from course) as c, (select * from teacher where t_id=5) as t
where t.t_id = c.t_id
古明地觉看到,拍了一下魔理沙的脑袋:"笨蛋,你这样写的话,c这张表里面就只有c_names这一个字段了,那么t.t_id = c.c_id还有办法执行吗?",魔理沙顿时领悟了,如果只在course上对c_names做投影是不行的,上层结点所有的表达式都需要考虑到,于是修改了表达式:
select t.t_name, c.c_names
from (select c_names, t_id from course) as c, (select * from teacher where t_id=5) as t
where t.t_id = c.t_id
"这还差不多",古明地觉笑着说,又拍了一下魔理沙的脑袋:"这是使用的投影的串接率,也是一个非常重要的关系代数等价规则,目前我们对这个SQL的优化主要是使用了选择下推和投影下推。在做笛卡尔积之前,先做了过滤,这样笛卡尔积的计算量会变小。"
然后魔理沙似乎发现了什么,问道:"你看,我们选择t.t_id=5并且t.t_id = c.t_id,那么我们是不是可以推理出一个c.t_id = 5的新约束条件呢?这样还可以把这个条件下推到course表中,这样就又能降低笛卡尔积的运算量。"
古明地觉回答她:"是的,这就是等价推理。PostgreSQL 在查询优化的过程中,会将约束条件中等价的部分都记录到等价类中,这样就能根据等价类生成新的约束条件。比如示例的语句中就会产生一个等价类 {t.t_id, c.t_id, 5},这是一个含有常量的等价类,是查询优化器比较喜欢的等价类,这种等价类可以得到列属性和常量组合成的约束条件,通常都是能下推的。"
魔理沙心理面很高兴,自己通过仔细观察,得到了等价类的优化,感觉有了学习的动力,心里美滋滋的,然后问:"那上面的 SQL 语句还有什么可优化的吗?"
古明地觉观察了一下这个语句说:"我们已经在 teacher表上进行了 t.t_id = 5 的过滤,在 course 表上也做了 c.c_id = 5 的过滤,这就说明在做笛卡尔积时,实际上已确定了 t.t_id = c.t_id = 5。也就是说 t.t_id = c.t_id 这个约束条件已经隐含成立了,也就没什么用了,我们可以把它去掉,最终形成一个这样的 SQL 语句。"
select t.t_name, c.c_names
from (select * from teacher where t_id=5) as t,
(select t_id, c_names from course where t_id=5) as c
古明地觉说:"经过选择下推、投影下推和等价类推理,我们对这个 SQL 语句或者说关系代数表达式进行了优化,最终降低了计算量。"
魔理沙感觉对谓词下推已经理解了,哈哈一笑:"看上去也不复杂嘛,我发现了可以下推的选择我就下推,完全没有问题啊",古明地觉翻了翻白眼:"甚矣,我从未见过如此厚颜无耻之人。我们现在看的这个例子,只不过是最简单的一种情况啊,你就这样大言不惭,你的人生字典里还有羞耻二字吗?"
魔理沙撅了撅嘴:"我的人生没有字典"
"我们这个例子有一个问题,它是内连接,因此我们可以肆意妄为地将选择下推下来,可以没羞没臊地做等价类推理。但如果是外连接,还能这么做吗?",古明地觉嘴角微微上扬,露出一次弧度。
"额(⊙o⊙)…",魔理沙陷入了沉思。
物理优化
通过古明地觉和魔理沙的对话,相信我们对逻辑优化的部分已经有了一个简单的了解,逻辑优化也叫基于规则的优化,这种优化方式比较呆板、不够灵活,就是按照定义好的规则硬性地进行等价变换,于是就催生了新的优化方法——物理优化。物理优化又叫基于代价的优化,今天我们再次跟着古明地觉、魔理沙和新成员芙兰朵露一起来探讨一下 PostgreSQL 优化器是怎么计算路径代价的,又是怎么筛选路径的。对这些内容已经了如指掌的朋友可以跳过这个导读,直接开始后面的内容学习
统计信息和选择率
"咚咚咚……",地灵殿大门外传来了敲门声,古明地觉打开门一看,原来是以前的同事芙兰朵露,芙兰朵露是专门从事数据库查询优化开发的码农,也有十几年从业经验了。古明地觉感到非常 Happy,因为这两天给魔理沙讲查询优化器讲得有些吃力,今天芙兰朵露来了正好可以帮上忙:"芙兰同志,我的学生魔理沙最近要做数据库原理实践,总来问我优化器的问题,可我对优化器也是一知半解,这下你来了可以帮帮忙不?"
"这难不倒我,随时都可以",芙兰拍了拍自己的飞机场,自信的说。
魔理沙对芙兰早有耳闻,接到古明地觉电话后迅速赶到,见面不久便吐起了苦水:"我最近正在查看基于代价的优化,感觉付出了很多代价,但收获甚微,期望今天能得到芙兰姐姐的指导"
芙兰表示交给我吧,直接切入正题:"说到代价,我觉得有个东西是绕不过去的,就是统计信息和选择率。PostgreSQL 的物理优化需要计算各种物理路径的代价,而代价估算的过程严重依赖于数据库的统计信息。统计信息是否能准确地描述表中的数据分布情况是决定代价准确性的重要条件之一。"
魔理沙说:"古明地觉校长和我说过,数据库有很多物理路径,这些物理路径也叫物理算子。和逻辑算子不同,物理算子是查询执行器的执行方法,我们只需要计算物理算子每个步骤的代价,汇总起来就是路径的代价了,那要统计信息有什么用呢?"
芙兰回答:"是的,我们就是要计算一个物理算子的代价,但是物理算子的计算量并不是一成不变的。"说着他从旁边的书桌上拿来纸和笔,写了两个 SQL 语句。
SELECT A+B FROM TEST_A WHERE A > 1;
SELECT A+B FROM TEST_A WHERE A > 100000000;
然后问魔理沙:"你看,这两个语句可以用同样的物理算子来完成,但是它们的计算量一样吗?"
魔理沙心想:A > 1 和 A > 1000000000 都是过滤条件,经过过滤之后,它们产生的数据量就不同了,这样投影中的 A + B 的计算次数就不同了,所以它们的代价应该是不同的,那它和统计信息有什么关系呢?思考了一下,顿时灵光一闪,"我知道了,我在计算物理算子的代价的时候,要知道 A > 1 之后还剩下多少数据或者 A > 1000000000 之后还剩下多少数据,如果我们提前对表上的数据内容做了统计,剩下多少数据就不难计算了,所以必须要有统计信息。"
芙兰点了点头:"嗯,通过统计信息,代价估算系统就可以了解一个表有多少行数据、用了多少个数据页面、某个值出现的频率等,然后就能根据这些信息计算出一个约束条件能过滤掉多少数据,这种约束条件过滤出的数据占总数据量的比例称为选择率。"
魔理沙继续问:"那么统计信息是什么形式的呢?"
芙兰挠挠头说:"这个还真是有点麻烦,我们说常用的统计信息的形式就是 distinct 率、NULL 值率、高频值、直方图、相关系数这些,它们分别有不同的作用。比如说 distinct 率,你可以获知某一列有多少个独立值,这种信息对于像性别这种列就显得特别有用。NULL 值率呢,在统计的过程中,NULL 值是不好处理的,因此把它独立出来,形成 NULL 值率,这样在高频值、直方图这些形式中就不用考虑 NULL 值的情况了。高频值属于奇异值,顾名思义,就是出现得比较多的一些列值。去掉了 NULL 值,再去掉高频值,剩下的值可以用来做一个等频的直方图。"
古明地觉看魔理沙有点跟不上,于是补充了一下:"统计信息嘛,主要的还是高频值、直方图和相关系数,实际上我建议还是不要纠结于统计信息有哪些形式,只要知道它是用来算代价的就可以了。"
芙兰对古明地觉说:"这怎么可以,我还没有说统计信息是如何生成的呢!比如它通过了两阶段采样,然后对样本进行统计时使用的统计方法,哪些值可以作为高频值,直方图有几个桶,相关系数是怎么计算的,相关系数在计算索引扫描路径代价的时候怎么用的……而且我和你说,PostgreSQL 还出了基于多列的扩展统计信息,多列统计信息分成了哪些类型,分别是什么含义,各自是怎么计算的,还有选择率是怎么结合统计信息计算的,这些我还没说呢……"
古明地觉无奈地说:"像你这样讲优化器,岂不是要出一本书了?"
芙兰痛苦表示:"那好吧,统计信息我们就说到这里,但是它确实是代价计算的基石。魔理沙同学,你理解了它的作用就可以了。"
古明地觉继续神秘地说:"实际上统计信息往往也不准,你想想本来就是采样的结果嘛,样本是否显著压根就不好说,而且随着应用程序对表的更新,统计信息可能更新不及时,那就更会出现偏差。更严重的是,如果我们遇到 a > b 这样的约束条件,使用统计信息计算选择率也很不好计算,即使算出来,也可能不准。"
芙兰也赞同:"是的,统计信息确实也有不准确的问题。我听说有个数据库用户,他家后院出了一口泉水,他爸爸觉得是吉兆,去找风水大师看。风水大师掐指一算说:你儿子每次遇到数据库性能慢就知道更新统计信息,可是统计信息太水了,都从你家后院冒出来了。"
三个人顿时开怀大笑,然后古明地觉和芙兰同时向魔理沙露出了让人毛骨悚然的笑容。
关于物理路径
事毕,魔理沙说:"不如给我说说物理路径吧,代价算来算去,最终还是为了物理路径计算代价嘛。校长和我说过它大体分成扫描路径和连接路径,我查过一些说明,知道扫描路径有顺序扫描路径、索引扫描路径、位图扫描路径等;而连接路径通常有嵌套循环连接路径、哈希连接路径、归并连接路径,另外还有一些其他的路径,比如排序路径、物化路径等。"
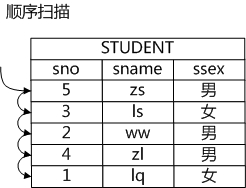
芙兰表示:"是的,我们就来说说这些路径的含义吧。如果要获得一个表中的数据,最基础的方法就是将表中的所有的数据都遍历一遍,从中挑选出符合条件的数据,这种方式就是顺序扫描路径。顺序扫描路径的优点是具有广泛的适用性,各种表都可以用这种方法,缺点自然是代价通常比较高,因为要把所有的数据都遍历一遍"。与此同时古明地觉在纸上画了个图,说:"这个图大概就是顺序扫描路径。"
芙兰继续说:"将数据做一些预处理,比如建立一个索引,如果要想获得一个表的数据,可以通过扫描索引获得所需数据的地址,然后通过地址将需要的数据获取出来。尤其是在选择操作带有约束条件的情况下,在索引和约束条件共同的作用下,表中有些数据就不用再遍历了,因为通过索引就很容易知道这些数据是不符合约束条件的。更有甚者,因为索引上也保存了数据,它的数据和关系中的数据是一致的,因此如果索引上的数据就能满足要求,只需要扫描索引就可以获得所需数据了。也就是说在扫描路径中还可以有索引扫描路径和快速索引扫描路径两种方式。"
古明地觉则为芙兰捧哏,在纸上画出了索引扫描和快速索引扫描的图。
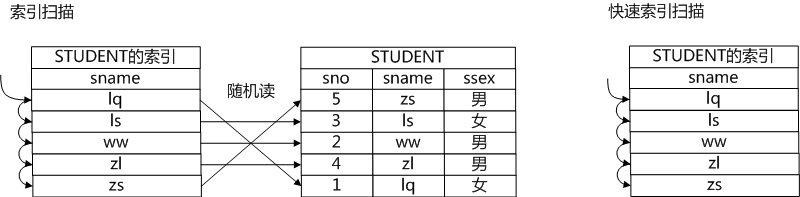
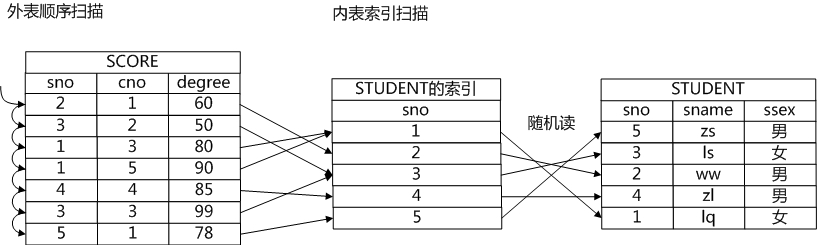
索引扫描随机读的问题
魔理沙看到图上写了随机读三个字,问道:"我看这个索引扫描有随机读的问题,这个问题能否解决掉呢?也就是说既利用了索引,还避免了随机读的问题,有这样的办法吗?"
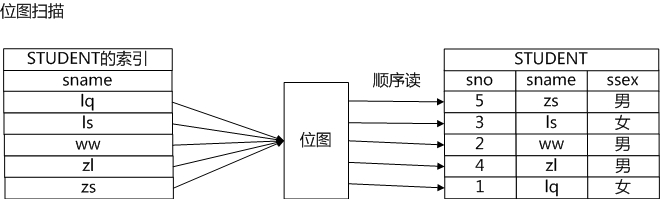
芙兰说:"索引扫描路径确实带来随机读的问题,原因是索引中记录的是数据元组的地址,索引扫描是通过扫描索引获得元组地址,然后通过元组地址访问数据,索引中保存的“有序”的地址,到数据中就可能是随机的了。位图扫描就能解决这个问题,它通过位图将地址保存起来,把地址收集起来之后,然后让地址变得有序,这样就通过中间的位图把随机读消解掉了",古明地觉则继续在纸上画出了位图扫描的示意图。
古明地觉补充说道:"扫描过程中还会结合一些特殊的情况,有一些非常高效的扫描路径,比如 TID 扫描路径。TID 实际上是元组在磁盘上的存储地址,我们能够根据 TID 直接就获得元组,这样查询效率就非常高了"。
芙兰也点了点头继续说:"扫描路径通常是执行计划中的叶子结点,也就是在最底层对表进行扫描的结点。扫描路径就是为连接路径做准备的,扫描出来的数据就可以给连接路径来实现连接操作了。"
古明地觉在纸上画一边说:"要对两个关系做连接,受笛卡尔积的启发,可以用一个算法复杂度是 O(mn) 的方法来实现,我们叫它嵌套循环连接(Nested Loop Join) 方法。这种方法虽然复杂度比较高,但是和顺序扫描一样,胜在具有普适性"
芙兰说:"嵌套循环连接这种方法的复杂度比较高,看上去没什么意义,但是如果嵌套循环连接的内表的路径是一个索引扫描路径,那么算法的复杂度就会降下来。索引扫描的算法复杂度是 O(logn),因此如果嵌套循环连接的内表是一个索引扫描,它整体的算法复杂度就变成了 O(mlogn),看上去这样也是可以接受的。"
哈希连接
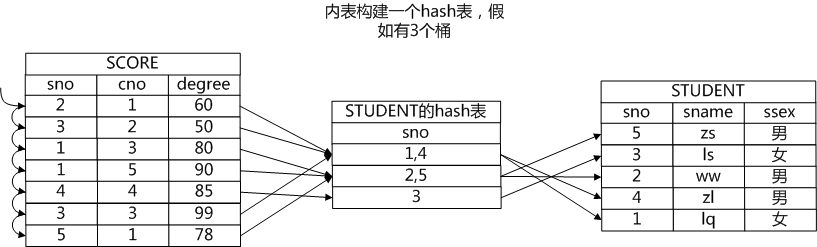
魔理沙点了点头:"嗯,索引实际上是对数据做了一些预处理,我想如果哈希连接(Hash Join)方法就是将内表做一个哈希表,这样也等于将内表的数据做了预处理,也能方便外表的元组在里面探测吧?"
芙兰也点了点头:"假设哈希表有 N 个桶,内表数据均匀地分布在各个桶中,那么哈希连接的时间复杂度就是 O(m * n /N),当然,这里我们没有考虑上建立哈希表的代价。"
古明地觉则在纸上画出了哈希连接的示意图,并补充道:"哈希连接通常只能用来做等值判断。"
归并连接
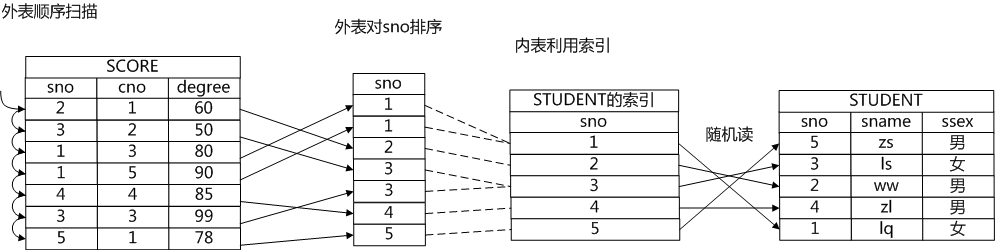
芙兰:"如果将两个表先排序,那么就可以引入第三种连接方式:归并连接(Merge Join)。这种连接方式的代价主要浪费在排序上。如果两个关系的数据量都比较小,那么排序的代价是可控的,归并连接就是适用的。另外如果关系上有有序的索引,那就可以不用单独排序了,这样也比较适用归并连接。你看我画的这个归并连接的示意图,外表是需要排序的,而内表则借用了原有的索引的顺序,消除了排序的时间,降低了物理路径的代价。"
"这些路径属于 SPJ 路径,在 PostgreSQL 的优化器中,通常会先生成 SPJ 的路径,然后在这基础上再叠加 Non-SPJ 的路径,比如说聚集操作、排序操作、limit 操作、分组操作……",芙兰继续补充。
关于代价的计算
魔理沙:"可是算来算去,物理路径的代价还是有选不准的时候啊。"
芙兰:"最优路径选得不准是谁的原因?那就是代价模型不行啊。代价模型不行赖谁?那就是程序员没建好啊,所以要怪就怪到程序员自己头上。"
魔理沙:"可是我看 PostgreSQL 的代价计算已经很复杂了啊。"
芙兰:"但数据库的周边环境更复杂啊。你想想,在实际应用中,数据库用户的配置硬件环境千差万别,CPU 的频率、主存的大小和磁盘介质的性质都会影响执行计划在实际执行时的效率。"
古明地觉:"虽然在代价估算的过程中,我们无法获得绝对真实的代价,但是绝对真实的代价也是不必要的。因为我们只是想从多个路径(Path)中找到一个代价最小的路径,只要这些路径的代价是可以相互比较的就可以了。因此可以设定一个相对的代价的单位 1,同一个查询中所有的物理路径都基于这个相对的单位 1 来计算的代价,这样计算出来的代价就是可以比较的,也就能用来对路径进行挑选了。"
芙兰:"PostgreSQL 采用顺序读写一个页面的 IO 代价作为单位 1,而把随机 IO 定为了顺序 IO 的 4 倍。"
魔理沙:"我知道,这个我查过相关的书。首先,目前的存储介质很大部分仍然是机械硬盘,机械硬盘的磁头在获得数据库的时候需要付出寻道时间。如果要读写的是一串在磁盘上连续的数据,就可以节省寻道时间,提高 IO 性能。而如果随机读写磁盘上任意扇区的数据,那么会有大量的时间浪费在寻道上。其次,大部分磁盘本身带有缓存,这就形成了主存→磁盘缓存→磁盘的三级结构。在将磁盘的内容加载到内存的时候,考虑到磁盘的 IO 性能,磁盘会进行数据的预读,把预读到的数据保存在磁盘的缓存中。也就是说如果用户只打算从磁盘读取 100 个字节的数据,那么磁盘可能会连续地读取磁盘中的 512 字节(不同的磁盘预读的数量可能不同)并将其保存到磁盘缓存。如果下一次是顺序读取 100 个字节之后的内容,那么预读的 512 字节的数据就会发挥作用,性能会大大增加。而如果读取的内容超出了 512 字节的范围,那么预读的数据就没有发挥作用,磁盘的 IO 性能就会下降",魔理沙说了一大串,然后自豪表示:"怎么样,我说的对吧。"
芙兰:"你说得对,目前 PostgreSQL 的查询优化大量考虑了随机 IO 和顺序 IO 所带来的性能差别,在这方面做了不少优化。但是现在的磁盘技术越来越发达了,以后随机 IO 和顺序 IO 是不是还差这么多,就值得商榷了。"
代价基准单位
魔理沙:"那到底还有哪些代价基准单位呢?"
古明地觉:"基于磁盘 IO 的代价单位当然就是和 Page 有关的了,也就是说我们刚才说的顺序 IO 和随机 IO 都属于 IO 方面的基准代价。让牛二哥给你介绍一下 CPU 方面的代价基准单位吧。"
芙兰:"CPU 方面的基准单位有哪些呢?比如说我们通过 IO 把磁盘页面读到了缓存,但我们要处理的是元组啊,所以还需要把元组从页面里解出来,还要处理元组,这部分主要消耗的是 CPU,所以会有一个元组处理的代价基准单位。另外,我们在投影、约束条件里有大量的表达式,这些表达式求解也主要消耗 CPU 资源,所以还有一个表达式代价的基准单位。"
芙兰:"现在 PostgreSQL 增加了很多并行路径,因此它也产生了通信代价,这个也需要计算的。"
魔理沙听罢,表示:"那我们就能得到一个这样的公式。"
总代价 = CPU 代价 + IO 代价 + 通信代价
芙兰:"总结得不错,这样就可以计算每种物理路径的代价,就可以对路径进行筛选了,最后挑选出来的路径就是最优路径。"
关于最优路径
芙兰表示说了这么多肚子有些饿了,然后三人使用App搜索附近的饭店,突然古明地觉像是想到了什么,说:"我们可以创业搞一个 AI 点评,只推荐最优的饭店,我准确地找到了吃货们的痛点,这里面隐含着很大的商机啊!"
芙兰瞥了她一眼:"AI 推荐当然好,可是要推荐得准才行啊。一个人一个口味,你这个需求太智能了,我估计不好弄。"
魔理沙:"我最近在算法课上学过一些最优解问题的解决方法,应该能用得上。"
芙兰叹口气说:"可是这些方法用到优化器里都不一定够用,何况用到一个更加智能的项目上呢?"
"嗯?优化器里也用到最优解问题的方法了吗?我们学过动态规划、贪心算法……",魔理沙如数家珍的说起来。
古明地觉:"用到了啊, 虽然物理路径看上去也不多,但实际上枚举起来,它的搜索空间也不小。例如,在扫描路径中,我们就可以有顺序扫描、索引扫描和位图扫描。假如一个表上有多个索引,就可能产生多个不同的索引扫描,那么哪个索引扫描路径好呢?还有,索引扫描和顺序扫描、位图扫描相比,哪个好呢?"
数据库路径的搜索方法
古明地觉看着魔理沙迷离的眼神继续说:"数据库路径的搜索方法通常有 3 种类型:自底向上方法、自顶向下方法、随机方法,而 PostgreSQL 采用了其中的两种方法。"
"采用了哪两种方法",芙兰明知故问
"采用了自底向上和随机方法,其中自底向上的方法是采用动态规划方法,而随机方法采用的是遗传算法。"
魔理沙:"你们说的好高深啊"
古明地觉:"可以让芙兰先给你说说怎样用动态规划方法搜索最优物理路径。"
最优物理路径
芙兰拿出纸来画了几个圈,然后说:"这代表四个表,自底向上嘛,所以是从底下向上堆积"

"动态规划方法首先考虑两个表的连接,其中优先考虑有连接关系的表进行连接。两个表的连接可以建立一个新的表,我们把这些新表叫做第二层。"芙兰通过连线,产生了一些新的表。
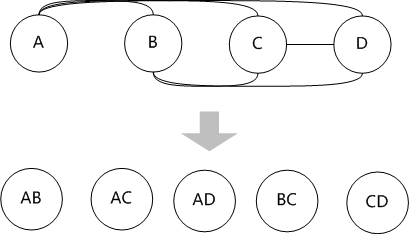
"第二层的表和第一层的表再连接,可以生成基于三个表连接的新的‘表’,这样就又向前推进了一层,产生了第三层。"
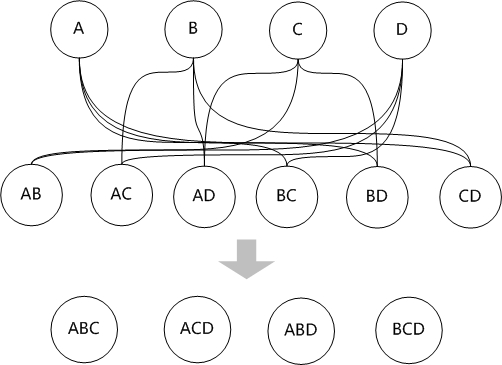
"然后再用第三层的表和第一层的表进行连接,最终生成整个问题的最优路径。"

"可是,这不就是穷举吗?"小明问道。
芙兰解释道:"动态规划有两个特点,一个是要重复地利用子问题的解,这样能减少计算量,降低复杂度;另外一点就是通过子问题的最优解能够构造出最终的最优解,也就是说需要具有最优子结构的性质,所以动态规划的复杂度和穷举是不一样的。"
古明地觉:"还有,虽然你看图里的连线比较多,但在实际情况里,并不是所有的圈圈之间都能产生连线,连接关系也有个合法性的问题嘛,所以复杂度是可以控制住的。"
魔理沙感觉好像明白了一点,然后赶紧追问:"那遗传算法呢?"
芙兰突然意识到了什么,说:"哎哎哎,我们不是在搜索饭店吗,怎么就说起最优路径了?先点餐吧,再晚饭都没得吃了。"
于是三个人又热火朝天地搜起饭店来……
小结
随着芙兰、古明地觉和魔理沙的对话结束,我们也要开始真正地进入主要内容了……欢迎走进 PostgreSQL 优化器的大门,这次我们就没完了。相关内容会在后面的博客中
