spark核心概念
我们之前介绍了spark的核心RDD,它是spark操作的基本单元。但是对于spark集群来说你还需要它的其它概念,比如我们操作RDD的时候,资源由谁来管理、任务由谁来执行等等。
application:就是我们基于spark开发的应用程序,比如我们写的py文件,一个py文件就可以看成是一个基于spark的应用程序,它是由一个driver进程和多个executor组成。driver和executor是什么先不用管,总之记住一个基于spark的应用程序=1个driver+多个executor。driver:一个进程,运行应用程序的main方法(python中可以把if __name__ == "__main__"看成是main方法),并创建一个SparkContext对象cluster manager:集群管理器,一个用于在集群上申请资源的外部服务,比如你要用多少cpu、多少内存等等。我们使用spark-submit的时候可以有很多参数:--driver-memory、--driver-cores、--executor-memory、--executor-cores等等deploy mode:部署模式,它是用来决定driver进程到底运行在什么地方的。我们在上一篇博客中说了有两种,分别是client和cluster。如果是cluster模式:框架将启动在集群里面启动你的driver进程,并且是运行在am(后面说)里面;如果是client模式:那么提交者将会在集群外部、也就是本节点上启动driver进程。所以区别就是你的driver运行在哪里,运行在本地就是client,运行在集群里面就是cluster。work node:工作节点,用于在集群里面运行你的应用程序的代码。如果是standalone模式,那么work node就是你的节点或者说机器;如果是yarn,那么就是NodeManagerexecutor:一个启动的进程,用于在work node上运行你的应用程序。它可以执行任务、将数据保存到内存或者磁盘上,每一个应用程序都有自己独立的多个executor。也就是说,一个application可以对应多个executor,但是一个executor只会对应一个applicationtask:任务,由driver通过网络传输到executor中,它是执行的单元。比如:map、filter等等transformation操作,这些都是taskjob:由一个或多个task组成的并行计算。我们说一个transformation操作可以看成是一个task,说明task不会被立刻执行。当遇到action操作、开始真正计算的时候,对这些task的计算就形成了一个job。stage:每个job会被分割成多个小的集合,每一个小的集合就叫做一个stage。另外,一个stage的边界往往是从某个地方取数据开始,到shuffle结束。
东西有点多,我们可以梳理一下。假设我们有一个应用程序:application,那么driver负责帮我们启动并创建sc,然后发送task到executor上,executor是在work node上执行的,执行的时候需要资源,这些是cluster manager帮我们申请,另外启动的时候还可以指定deploy mode。如果当遇到了action操作,那么对多个task的并行计算就组合成了job,每个job又会被切分成多个stage。这样是不是都串起来了呢?
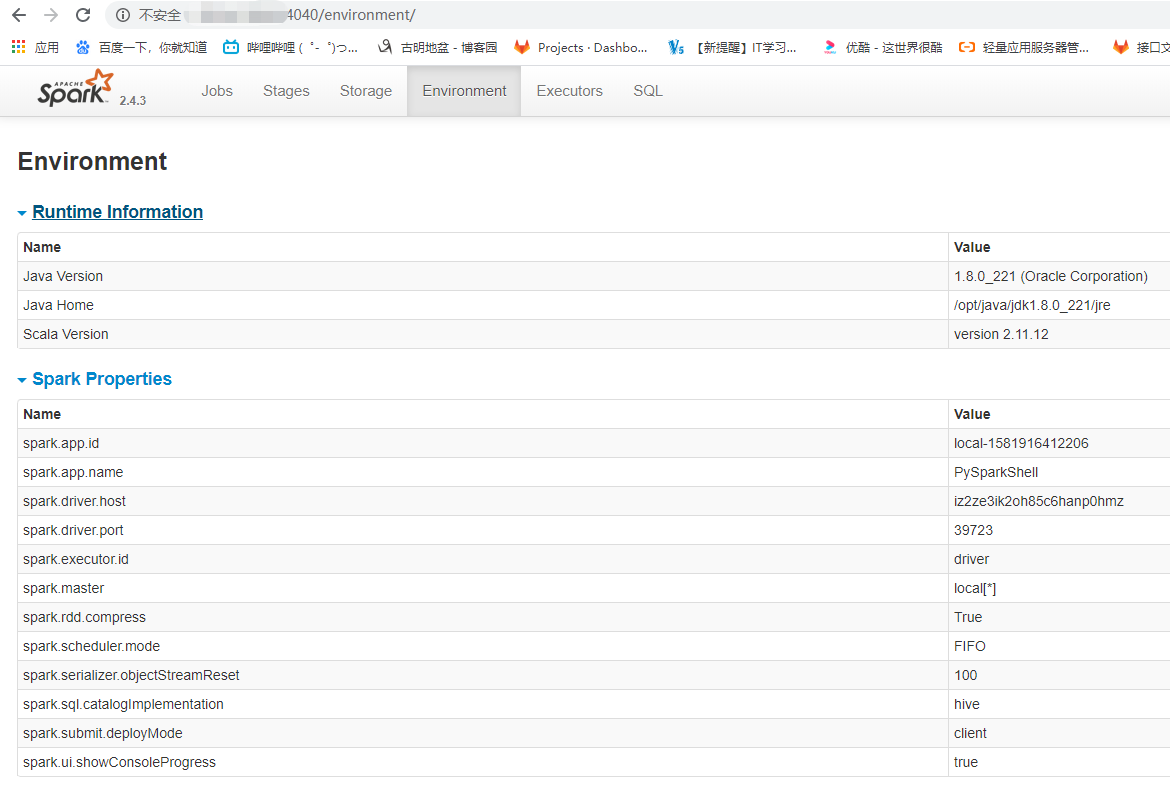
这些信息可以在4040端口上得到体现
spark运行架构以及注意事项
一个spark应用程序运行在一组独立的进程之上,意思就是多个应用程序之间是隔离的。每个应用程序都具备一个driver和一组独有的executor,多个应用程序是通过driver进程里面的SparkContext对象进行协调的。

如果要运行一个集群,那么你的SparkContext对象要能够连接到cluster manager(可以是standalone、mesos、yarn)之上,为你的应用程序申请资源。一旦建立连接,就会在集群的节点之上获得executor,为你的程序运行计算和存储数据。然后将你的应用程序的代码发送到executor,最终SparkConetxt将所有的task发送到executor上去执行,所以code和task实际上是分开的。
上面的架构图是官网上面的,这个架构还有一些很有用的地方。
每个应用程序都有自己独立的executor,它在程序的整个生命周期中一直存在,并且以多线程的方式运行task。这就带来一个好处,每个应用程序之间是隔离的,无论是从调度方面(每个driver调度自己的task)还是从执行方面(不同应用程序的task运行在不同的jvm之上)。然而,这也就意味着不同的应用程序(SparkContext对象)之间的数据是不能够被共享的,除非你把数据写到一个外部存储系统。spark对cluster manager是不感知的,只要它能获取到executor进程,这些进程之间就会彼此进行通信,即使在支持其它应用程序的cluster manager上运行也会变得相对容易driver进程必须要能够监听并且接收来自于executor的连接,并且我们看到图上的箭头是双向的,因为driver是要发送代码、发送任务给executor,并且executor执行的时候也是要想driver发送心跳信息,否则挂了怎么办。因此箭头是双向的,driver能够不仅要能够连接executor、还要能够接收executor的连接。因为driver能够在集群之上调度task,我们说要把task发送到executor上,所以它应该尽可能的靠近你的work node,最好是在同一片网络中,因为网络传输都需要耗费时间的。如果你真的要远程发送请求到集群之上,最好是给driver开一个RPC然后执行一些提交请求,而不是直接运行一个远离(网络意义上离的比较远)work node的driver
MapReduce和spark区分
我们说spark比MapReduce的效率要高很多,那么它们之间的差异主要体现在什么地方呢?
MapReduce
一个MR程序=一个job一个job=N个task(Map/Reduce)一个task对应一个进程task运行的时候开启进程,task执行完毕之后销毁进程。对于多个task来说,开销是比较大的,即使你能通过jvm共享
spark
一个应用程序=一个application=一个driver(创建sc)+多个executor一个application=N个job一个job=1到N个stage一个stage=1到N个task一个task对应一个线程,多个task可以并行地运行在executor中。
spark cache
spark是有缓存的,我们在计算完结果之后是可以缓存起来的,这样做能够加快速度。
>>> rdd = sc.textFile("file:///root/1.txt")
>>> rdd.count()
100000
>>> # 此时rdd就被缓存起来了,输出的什么东西先不用管,我们一会看web页面
>>> rdd.cache()
file:///root/1.txt MapPartitionsRDD[1] at textFile at NativeMethodAccessorImpl.java:0
>>> # 再次进行计算,当然这里看不出来效果。其实如果你的数据量很大的话,你第二次执行的时候会发现速度变快了
>>> rdd.count()
100000
>>> import os
>>> # 这里先看一下这个文件的大小
>>> os.stat("/root/1.txt").st_size
1150022
>>> os.stat("/root/1.txt").st_size / 1024
1123.068359375

我们看到storage里面的RDD Name,这个就是我们的文件名;Storage Level表示存储级别,默认是基于内存的;Cached Partitions表示缓存的分区数,因为默认的RDD有两个分区。关键看倒数第二个内存大小,我们看相比原来的文件大小,小了很多,这是spark内部基于缓存所做的策略;最后的是磁盘大小,没有缓存到磁盘上,所以是0。
因为RDD具有不变性,所以当我们缓存起来之后(针对于action操作),再次进行相同的操作的时候会直接从缓存里面读,而不会再次进行计算了。这样做的好处就是可以节省资源、提高效率,假设你的RDD进行了多次transformation操作,如果你不缓存的话,那么每一次action的时候,都会从源头、也就是最开始的RDD进行计算。再比如我们这里的rdd,它是读取文件得到的,如果不缓存,那么每count一次就要从磁盘上读取一次。所以根据业务的情况,你可以考虑缓存。
RDD的持久化
spark一个最重要的能力就是它可以通过一些操作来持久化(或者缓存)内存中的数据,当你持久化一个RDD,节点就会存储这个RDD的所有分区,以后可以直接在内存中计算、或者在其它的action操作时能够重用,这一特性使得之后的action操作能够变得更快(通常是10个数量级),所以缓存对于迭代式算法或者快速的交互式使用是一个非常有效的工具。
你可以通过调用persist()或者cache()方法来持久化一个RDD,当第一次action操作触发时,所有分区数据就会被保存到其他节点的内存当中。并且spark cache具有容错性:如果RDD的某个分区数据丢失了,那么会根据原来创建它的transformation操作重新计算。
我们看到持久化一个RDD有两种操作:persist和cache,那么有什么区别呢?
persist:接收一个缓存级别,默认是基于内存cache:直接调用了persist所以如果不传参数,两者是一样的,如果需要指定缓存级别,那么需要调用persist。
此外,每一个持久化的RDD都能以不同的缓存级别进行存储,比如:持久化数据到磁盘、或者在内存中持久化、甚至还可以是用序列化java对象的方式(节省空间),通过节点进行备份。而缓存级别是通过StorageLeval对象进行设置的,然后传递给persist,如果是基于内存持久化,也可以调用cache。
那么缓存级别都有哪些呢?
MEMORY_ONLY:内存MEMORY_AND_DISK:内存和磁盘MEMORY_ONLY_2:内存,但是存两份MEMORY_AND_DISK:内存和磁盘,存两份DISK_ONLY:只存磁盘OFF_HEAP:存储在堆外,但是不推荐,这个官方说了实验性支持,还不是很完美。
class StorageLevel(object):
def __init__(self, useDisk, useMemory, useOffHeap, deserialized, replication=1):
self.useDisk = useDisk # 是否使用磁盘
self.useMemory = useMemory # 是否使用内存
self.useOffHeap = useOffHeap # 是否使用堆外
self.deserialized = deserialized # 是否反序列化
self.replication = replication # 副本系数,默认是1
def __repr__(self):
return "StorageLevel(%s, %s, %s, %s, %s)" % (
self.useDisk, self.useMemory, self.useOffHeap, self.deserialized, self.replication)
def __str__(self):
result = ""
result += "Disk " if self.useDisk else ""
result += "Memory " if self.useMemory else ""
result += "OffHeap " if self.useOffHeap else ""
result += "Deserialized " if self.deserialized else "Serialized "
result += "%sx Replicated" % self.replication
return result
# 所以我们需要哪一种就可以直接通过StorageLevel这个类来调用,并且我们看到创建的方式也很简单
# 如果支持什么,就给对应的参数传递True即可,不支持的传递Flse
# DISK_ONLY就只给第一个参数useDisk传递True,其它都是False
# MEMORY_AND_DISK就是第一、和第二个参数为True,其它为False
# 带2的,就给副本系数传个2,比较简单
StorageLevel.DISK_ONLY = StorageLevel(True, False, False, False)
StorageLevel.DISK_ONLY_2 = StorageLevel(True, False, False, False, 2)
StorageLevel.MEMORY_ONLY = StorageLevel(False, True, False, False)
StorageLevel.MEMORY_ONLY_2 = StorageLevel(False, True, False, False, 2)
StorageLevel.MEMORY_AND_DISK = StorageLevel(True, True, False, False)
StorageLevel.MEMORY_AND_DISK_2 = StorageLevel(True, True, False, False, 2)
StorageLevel.OFF_HEAP = StorageLevel(True, True, True, False, 1)
如果不想缓存了,可以使用unpersist,不需要参数。但是注意:persist是惰性的,只有在遇到一次action操作的时候,才会缓存RDD的分区数据,但是unpersist是立刻执行的。
到底使用哪种缓存
我们看到StorageLevel支持很多缓存策略,那么我们到底该选择哪一种呢?官方给了如下建议。
如果你的RDD能够使用默认的缓存策略搞定,就使用默认策略。这是最有效率的选择,它能允许RDD上的操作运行的尽可能的快。针对于java和scala,我们不用看不要把数据写到磁盘,除非你的数据非常的昂贵,不能允许有任何丢失的风险。否则重头计算甚至都比从磁盘读取块。如果你想快速的错误恢复,那么可以使用副本存储策略。比如你的一个分区数据丢了,但是你有两个副本,所以会去选择另一个副本,而不会重新计算。其实所有的存储策略,都可以通过重新计算丢失数据来提供完整的容错,但是副本的存在可以让你在不计算丢失数据的情况下继续运行task。如果副本为1,那么丢了只能重新计算了,但是副本为2,丢了1个还有1个,直接去取就可以了,就不用重新计算了。
spark血缘关系
还记得RDD的五大特性吗?其中有一条说:RDD依赖于一系列其它的RDD。每个RDD进行transformation操作的时候都会生成一个新的RDD,如果当前操作的RDD的某个分区数据丢了,那么会从上一个RDD重新计算丢失的分区数据。我们说这些RDD就像父亲、儿子一样,一代一代的传下去,它们之间是具有血缘关系的。
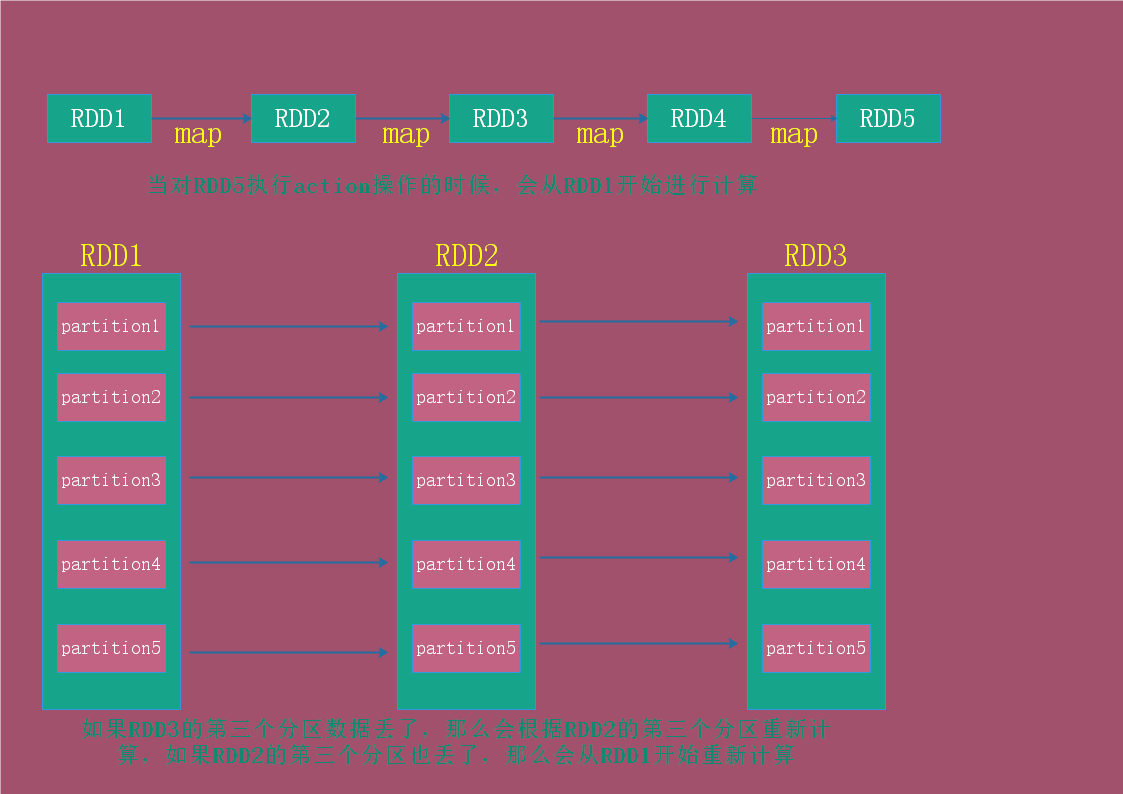
所以每个RDD之间是有血缘关系的,如果数据丢失,那么会根据父RDD重新计算丢失的数据,而不是重新计算。
spark dependency
我们说每个RDD是依赖于其它RDD的,但是RDD之间的依赖关系也分为两种,一种是窄依赖(Narrow),一种是宽依赖(Wide),我们看看这两种依赖之间有什么区别。
窄依赖:父RDD的一个partition最多被子RDD的一个partition所使用宽依赖:父RDD的一个partition会被子RDD的多个partition所使用,有shuffle操作(后面说)
窄依赖
像我们说的map、filter、甚至是union,它们都是窄依赖。窄依赖的一个特点就是可以进行流水线式的操作,一个接一个。

蓝色表示RDD,橙色表示分区partition,我们上面的几种转换都是窄依赖,因为父RDD的一个partition至多被子RDD使用一次。所以我们看到窄依赖是可以像流水线一样,一直往下走。如果在MapReduce中计算1 + 2 + 3要怎么做呢?要先计算1 + 2,然后把结果落地到磁盘,然后再从磁盘读取再和3进行运算。但是对于spark来说,窄依赖是可以一直在内存中持续操作的。
宽依赖
我们说宽依赖的话,那么父RDD的一个partition会被子RDD使用多次,也就是父RDD的一个分区会被子RDD的多个分区所使用。
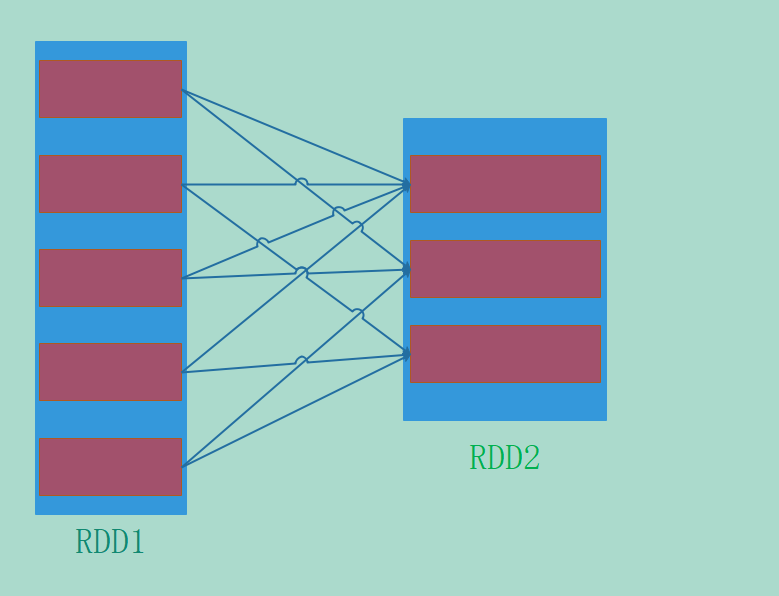
所以宽依赖就像这样,一个父RDD的partition会被子RDD的多个partition所引用。
那么它和窄依赖有什么区别呢?显然如果是窄依赖,那么子RDD在数据丢失的时候直接根据父RDD对应的分区进行计算即可,即使这个子RDD对应多个父RDD,也是很简单的。但是宽依赖就不一样了,如果是宽依赖的话,那么子RDD在分区数据丢失之后,再根据父RDD重新计算是一件比较麻烦的事情,因为涉及到了shuffle操作,这里再一次提到了shuffle,但我们现在还是先不说。首先shuffle的英文是洗牌,你可以理解为打乱,比如我们说的ByKey,是根据key来操作的,如果分区数据丢了,那么是不是需要从父RDD那里找到所有对应的key呢?相比窄依赖,这显然是一件非常麻烦的事情。
shuffle
一些行为会触发shuffle操作,shuffle是spark用于重新分配数据的一种机制,以便对不同partition里面的数据进行分组。
那么什么地方会发生shuffle操作呢?我们可以想一下reduceByKey,reduceByKey会生成一个新的RDD,所有相同的key对应的value都会组合在一起,形成一个列表,基本上所有的ByKey操作都会涉及到shuffle。
注意:shuffle是一个比较昂贵的操作,因为它涉及磁盘IO、数据序列化、网络IO
我们最后再用一张图,来展示一下窄依赖、宽依赖、以及shuffle操作。
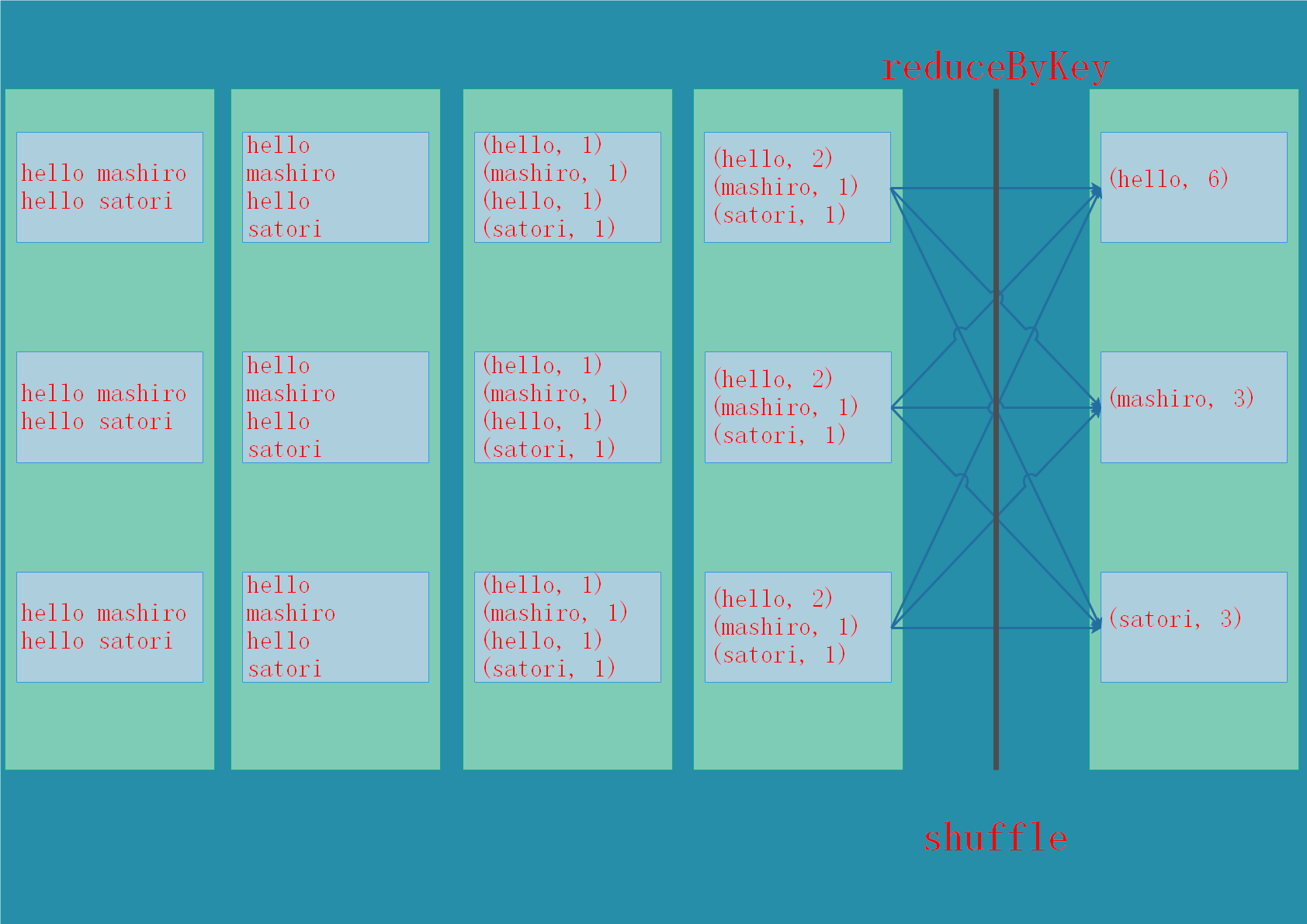
每当遇到一个shuffle操作时,就会被拆分成两个stage。还记得stage吗?我们说一个stage的边界往往是从某个地方取数据开始,到shuffle结束。
spark调优前戏
我们开发一个应用程序是比较简单的,但是这个程序执行的时候所表现出来的性能也是需要我们关注的,下面我们就来看看spark调优。
不过在看spark调优之前,我们需要能够监控我们应用程序,而监控的方式我们是通过webUI。每一个SparkContext对象都会启动一个webUI,默认端口是4040,如果被占用会尝试+1,变成4041,比如我们通过pyspark shell启动的时候也是可以的,因为默认创建了一个SparkContext对象。webUI上面展示了很多有用的信息,其中包括:
一系列stage和taskRDD的大小信息和内存使用情况执行环境信息运行的executor信息。
但是这里面存在一个问题,那就是当我们在执行作业的时候是可以通过4040端口查看的,但是程序结束那么这个端口就打不开了,因为程序结束SparkContext也没了。但是,我们想知道这个程序执行的怎么样,占用了多少内存、cpu、以及花了多长时间等等;而且如果程序挂了怎么办,或者程序执行的时候突然速度急剧下降,但是当我们想找出原因的时候,却看不到信息,这显然是不行的。
为了能够在程序结束之后也能看到webUI上面的信息,我们需要在程序启动之前设置一个参数:将spark.eventLog.enable设置为true,那么这个参数在什么地方设置呢?首先spark目录下的conf目录下有一个spark-defaults.conf,如果没有一般会存在一个对应.template,我们copy一份改成相应的名字即可。
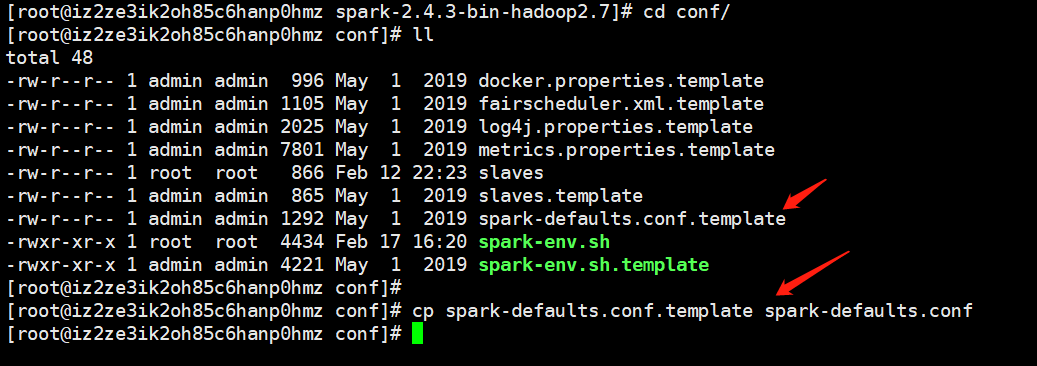
然后我们打开文件、设置参数。

就不打开注释了,直接拷贝一份即可,指定为true以及设置日志路径。但是这个路径不会自动创建,我们指定的是/directory,如果你的hdfs上没有这个目录,那么pyspark会启动不起来。
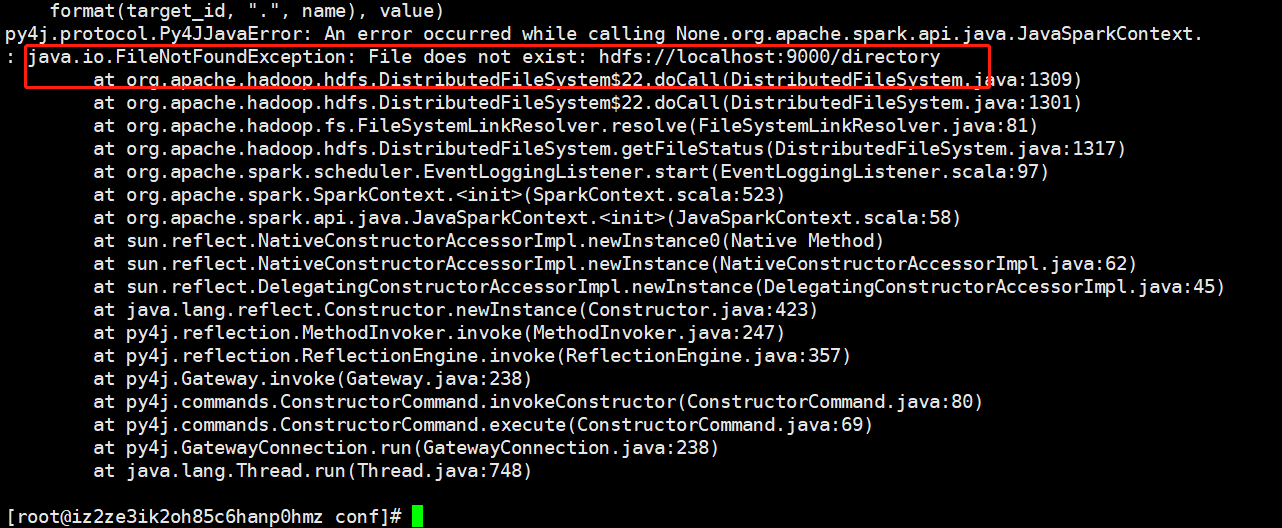
因此我们需要手动创建这个目录,hdfs dfs -mkdir /directory,然后录就可以正常启动了。
然后启动sbin目录下的start-history-server.sh就可以记录历史运行信息了,默认端口是18080,页面上会展示已完成和未完成的任务信息,至于端口怎么改我们后面说。但是还没完,我们还需要配置一个参数,spark.history.fs.logDirectory,这个参数表示日志的存储目录,默认是在本地,但是我们需要让它指向我们刚才配置的hdfs路径,在spark-env.sh里面配置。
# 怎么配置呢?凡是以start-history开头的都要配置在SPARK_HISTORY_OPTS里面,以"-Dx=y"的形式指定
# 把下面这一行拷贝进去即可,这个 export有没有都无所谓
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://localhost:9000/directory"
此时我们就算基本配置完成了,然后启动sbin/start-history-server.sh


此时还没有已完成的任务,因为我们刚刚启动嘛,现在我们来提交一个任务,先走一个。spark-submit --master local[*] 1.py
# 1.py内容如下
from pyspark import SparkContext
sc = SparkContext()
rdd = sc.parallelize([1, 2, 3, 4, 5])
print(rdd.map(lambda x: x + 1).collect())
此时我们再来看看页面。
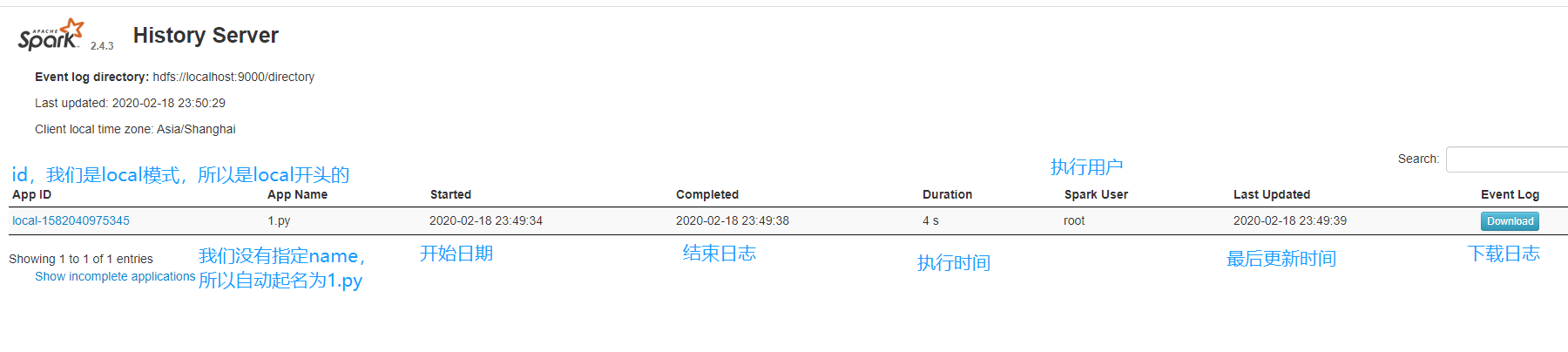
看到没,有信息了吧。如果你的作业是凌晨跑的,那么第二天上班的时候也能看。不然的话,如果作业凌晨三点挂了怎么办,第二都不知道为什么挂了。我们注意到在左下角还有show incomplete applications,显示未完成的任务,如果你的任务挂掉了也是可以看到信息的,这就很方便了。
这对调优是非常有帮助的,不然你的作业有多少个stage、stage里面有多少个并行计算的task、每个task计算的时候处理了多少数据、花了多长时间等等你都不知道,而配置了history,那么这些信息都能够清晰的展示在页面上,这对调优是很有帮助的。如果停止的话,可以使用stop-history-server.sh
那么页面上的数据是从哪里过来的呢,显然是从hdfs上的、我们刚才配置的/directory目录里面的文件来的,运行日志会写在文件里面,是一大堆的json串,页面上的信息就是根据这些json串解析出来的,有兴趣的话可以自己去看一下。
spark调优的几个方面
序列化
序列化有什么作用呢?我们说shuffle是经过网络传输、磁盘IO的,而且在做缓存的时候、对于你内存的节省使用、以及进程之间的通信都是要涉及到序列化的。
序列化该怎么选择呢?首先序列化在任何的分布式程序的性能方面都扮演了一个重要的角色,如果序列化之后的速度比较慢、或者序列化之后的大小比较大,那么就会降低性能。因此,你需要对spark应用程序进行调优。而spark目的是在序列化之后的速度和大小之间取得一个平衡,它提供了两种序列化方式:
java序列化:默认会采用java那一套序列化方式,java什么的不稀罕、懒得说,有兴趣的话可以自己百度或谷歌。kyro序列化:spark可以使用kyro库(版本2)序列化对象,并且它的速度要比java序列化快10个数量级、之后的大小也比java小。但是spark没有采用的原因是,这种序列化方式不支持所有的序列化类型,为了最好的性能,你需要事先在应用程序里面注册你要使用的类。但是官方针对的是scala,python的话则没有说。
内存管理
对内存方面的调优有三个要考量的因素:1.你的对象使用了多少内存。2.访问这些对象的成本。3.垃圾回收所带来的开销。
所以spark对内存的使用主要涉及到两个部分:执行和存储。执行所用的内存主要涉及shuffle、join、sort、aggregate等操作,而存储所用的内存则涉及缓存和传递数据。在spark中,执行和存储共享一片内存区域:如果执行没有使用内存,那么存储可以获得所有的内存,反之亦然。但是,如果在必要的情况下,执行可以抢夺存储所用的内存;但是为了避免全部抢光,所以可以设置一个阈值,如果存储到达这个阈值,执行就不能再抢存储的内存了。
广播变量
使用广播变量能够极大地降低内存的使用,如果你的task大小比较大,那么你可以考虑使用广播变量。
>>> # 创建广播变量
>>> data = sc.broadcast([1, 2, 3])
>>> # 调用value方法能够获取值
>>> data.value
[1, 2, 3]
>>>
数据本地性
数据本地性对spark job的性能有着很大的影响,假设我们数据存在hdfs上,我们的作业提交到yarn上去执行。如果我们的作业和数据在同一台节点上,那么计算会非常快;但要是不在同一台节点,那么肯定要把一方移动另一方所在的节点上,这样的话相比数据和计算在同一台节点相比,性能肯定会降低。于是我们要移动计算,而不是移动数据,而且即便要移动也要选好位置。
因此数据本地性就是指数据离计算到底有多近,基于数据的当前位置,数据本地性有以下几个级别,从最近到最远:
PROCESS_LOCAL:数据和代码在同一个jvm里面,这是最理想的情况,但是很少会遇到NODE_LOCAL:数据和代码在同一个节点,但是不在同一个jvm里面,这比PROCESS_LOCAL要慢一些,因为数据要在两个进程之间移动。但是生产上能保证NODE_LOCAL就算是非常不错的了。NO_PREF:数据在任何地方都能很快的访问到,没有所谓的本地行可言。RACK_LOCAL:数据在相同的机架上面,但是在不同的server上面。ANY:数据在其它地方,不在同一个机架上。