之前我们介绍了tornado 的基础流程,但是还遗留了一些问题,今天我们就来解决这些遗留问题并学习新的内容
settings,使用tornado.web.Application(handler, **settings),我们却不知道这个settings到底是什么,究竟有什么作用,今天就来介绍一下。
settings是一个字典,主要保存一些配置选项
-
debug设置tornado是否在调试模式下,默认为False,即在生产模式下。 debug设置为True的生活,具有如下特点: 自动重启,tornado应用会监控源代码文件,当有保存改动时便会自动重启服务器,类似于Django,可以减少手动重启的次数,提高开发效率,如果保存代码后有错误会导致重启失败,修改错误需要手动重启,可以通过autoreload = True设置 取消缓存编译的模板:有时候我们明明修改了模板文件,但是页面显示的内容并没有变化,就是因为用的还是缓存文件。因此debug = True,可以保证每次加载的模板文件都是最新的,也可以通过compiled_template_cache=False单独设置,表示不使用已经编译好的模板缓存 取消缓存静态文件的hash值:这和取消编译模板是类似的,有时候我们修改css,但是页面颜色或者字体并没有发生变化。 有了debug=True,可以保证每次加载的静态文件都是最新的,也可以通过static_hash_cache=False单独设置,表示不使用静态文件的哈希缓存 提供追踪信息:可以通过server_traceback=True单独设置
从源码也能看出来
-
static_path设置静态文件目录, 注意:寻找静态文件是tornado去找,类似Django,你要告诉tornado要去什么地方去找静态文件 -
template_path设置模板文件目录,和设置静态文件目录类似
配置文件如下:
import os
options = {"port": 7777}
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
settings = {"static_path": os.path.join(BASE_DIR, "static"),
"template_path": os.path.join(BASE_DIR, "templates"),
"compiled_static_cache": True,
"compiled_template_cache": True,
"server_traceback": True}
关于静态文件路径和模板文件路径,再次强调,是tornado去找。而且后面还会用到模板语言,必须要让tornado知道相应的路径在哪里。
在settings中指定static_path和template_path,那么tornado便会到相应的路径下去寻找。
下面介绍一下tornado的路由,路由在上一章我们知道,是用来指定url和handler之间的映射关系。当一个url过来会进行解析,然后执行对应的handler,tornado的路由还可以加一些别的参数
view.py
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
# 该方法会在执行http方法之前执行
# 可以传入参数,这个参数则是我们在定义路由的时候指定
def initialize(self, girl1, girl2):
self.girl1 = girl1
self.girl2 = girl2
def get(self, *args, **kwargs):
print(self.girl1, self.girl2)
self.write("my name is satori")
class MashiroHandler(tornado.web.RequestHandler):
def get(self, *args, **kwargs):
# url的反向解析
# 我们在定义路由的时候可以指定一个name="xxx",那么self.reverse_url(name),便会获取相应的url
# 这便是url的反向解析,通过指定的name获取定义的url
url = self.reverse_url("satori")
self.write(f'<h1><a href="{url}">还是喜欢satori</a></h1>')
application.py
import tornado.web
from views import view
import config
# 我们可以自定义一个Application,但是要继承tornado.web下的Application
class Application(tornado.web.Application):
def __init__(self):
handlers = [
# 我们在SatoriHandler的initialize中定义了girl1和girl2
# 那么girl1和girl2就在包含相应handler的路由中定义
# 以字典的形式传值即可
(r"/satori", view.SatoriHandler, {"girl1": "satori", "girl2": "koishi"}),
# 由于我们指定了name,那么name也要在包含相应handler的路由中定义
# 但是name比较特殊,我们不能用一般的路由定义,要使用tornado.web.url()
# 然后使用self.reverse_url(name)获取到的便是name所在路由的url
# 那么在页面渲染出来的便是一个a标签
tornado.web.url(r"/koishi", view.SatoriHandler, {"girl1": "satori", "girl2": "koishi"},
name=r"satori"),
(r"/mashiro", view.MashiroHandler)
]
super(Application, self).__init__(handlers=handlers, **config.settings)
输入localhost:7777/satori,得到页面如下

同时在pycharm中也打印了girl1和girl2的值

同时在pycharm中也打印了girl1和girl2的值
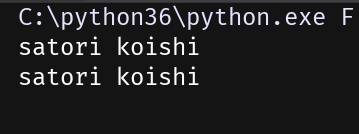
两个url的handler是一样的
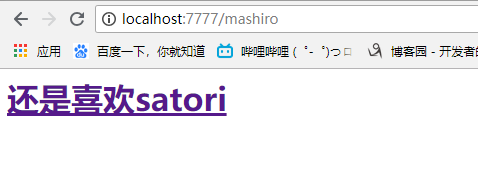
最后再来输入localhost:7777/mashiro,也显示了相应的字符串,而且是一个被渲染为一个a标签,我们点击一下
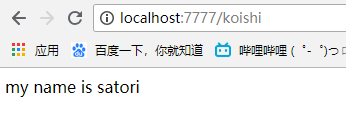
又跳转回去了,因为name="satori"所在路由的url是r"/koishi",那么通过在MashiroHandler中进行反向解析获取到的url就是r"/koishi"
那么点击之后会再次跳转到localhost:7777/koishi,从而执行SatoriHandler
从而在pycharm中再次输出,总共三次

利用http协议向服务器传递参数
1.提取url当中的特定部分
application.py
import tornado.web
from views import view
import config
# 我们可以自定义一个Application,但是要继承tornado.web下的Application
class Application(tornado.web.Application):
def __init__(self):
handlers = [
# 可以支持正则表达式,我们定义了三个分组
# 那么用户输入的内容会根据分组依次对应传到handler的get函数里面
(r"/satori/(w+)/(w+)/(w+)", view.SatoriHandler),
# 由于我们指定了分组的名字,就类似于关键字参数
# adj1、adj2、adj3会分别对应get函数里面的adj1、adj2、adj3
(r"/mashiro/(?P<adj1>w+)/(?P<adj2>w+)/(?P<adj3>w+)", view.MashiroHandler)
]
super(Application, self).__init__(handlers=handlers, **config.settings)
view.py
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self, adj1, adj2, adj3):
# 这里的参数会和分组的顺序保持一致
self.write(f"<h1>satori {adj1}, {adj2}, {adj3}</h1>")
class MashiroHandler(tornado.web.RequestHandler):
def get(self, adj2, adj3, adj1):
# 由于在路由中指定了名称,那么函数中参数的顺序便无所谓了
self.write(f"<h1>mashiro {adj1}, {adj2}, {adj3}</h1>")
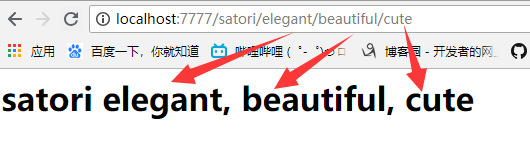
在浏览器中输入满足路由映射的url,会发现按照顺序依次打印了出来
再来试试另一个路由
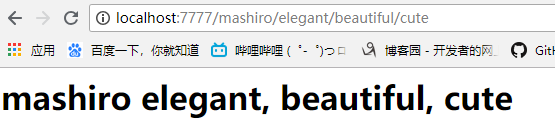
可以看到即便我们在MashiroHandler中定义的参数没有什么顺序,但是在页面中依旧按照我们输入url的顺序打印了出来,
这是因为我们定义路由的时候指定了名字,那么在执行get函数的时候,相当于adj1="elegant", adj2="beautiful", adj3="cute",
2.get方式传递参数
当我们输入localhost:7777/satori?a=1&b=2&c=3的时候,可以在程序当中获取相应的a,b,c的值。
可以回想一下requests,requests.get函数中有一个params参数,传入{"a": 1, "b": 2, "c": 3},便会自动和请求的url进行组合,从而得到类似于上面的新的url
那么反过来获取相应的a,b,c的值也是可以的
application.py
import tornado.web
from views import view
import config
# 我们可以自定义一个Application,但是要继承tornado.web下的Application
class Application(tornado.web.Application):
def __init__(self):
handlers = [
(r"/satori", view.SatoriHandler),
]
super(Application, self).__init__(handlers=handlers, **config.settings)
view.py
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self):
'''
函数的原型是self.get_argument(name, strip=True)
其实这个函数是self.get_query_argument(用于获取get请求的参数)和self.get_body_argument(用于获取post请求的参数)两个的函数的组合
而self.get_argument既可以用于get也可以用于post,因此我们一般都使用self.get_argument
参数:
name:返回get请求参数字符串中指定参数的值
如果出现多个同名参数,返回最后一个
strip:是否过滤掉两边的空格,默认为True表示过滤
'''
a = self.get_argument("a")
b = self.get_argument("b")
c = self.get_argument("c")
d = self.get_arguments("d")
self.write(f"参数a={a}, 参数b={b}, 参数c={c}, 参数d={d}")

首先a,b无需解释,至于c,由于我们是self.get_argument,所以只会获取最后一个,但是对于d,使用self.get_arguments,会获取一个列表,如果只有一个值,获取的仍是个列表,列表只有一个元素
3.post方式传递参数
首先templates目录里面创建一个html文件 ,satori.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>古明地觉</title>
</head>
<body>
<form action="/satori" method="post">
姓名:<input type="text" name="name">
<p></p>
性别:<input type="text" name="gender">
<p></p>
登场:<input type="text" name="from">
<p></p>
昵称:
<input type="checkbox" name="nickname" value="少女觉">少女觉
<input type="checkbox" name="nickname" value="觉大人">觉大人
<input type="checkbox" name="nickname" value="小五">小五
<input type="submit" value="提交">
</form>
</body>
</html>
application.py
import tornado.web
from views import view
import config
# 我们可以自定义一个Application,但是要继承tornado.web下的Application
class Application(tornado.web.Application):
def __init__(self):
handlers = [
(r"/satori", view.SatoriHandler),
]
super(Application, self).__init__(handlers=handlers, **config.settings)
view.py
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self):
# self.write表示写入字符串
# self.render表示将一个模板读取进来,进行渲染(替换掉模板语言),返回给用户
# 而且我们只是指定了文件名,tornado居然能找得到,因为我们在settings中定义了template_path
# 因此在执行self.render的时候tornado会自动到相应目录下去寻找模板文件
self.render("satori.html")
def post(self, *args, **kwargs):
# 我们在表单中定义了name="xxx"
# 因此self.get_argument的参数就是name
gender = self.get_argument("gender")
name = self.get_argument("name")
_from = self.get_argument("from")
nickname = self.get_arguments("nickname")
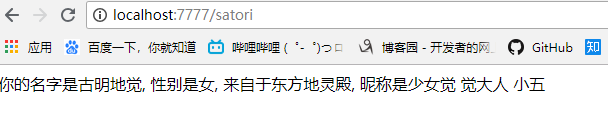
self.write(f"你的名字是{name}, 性别是{gender}, 来自于{_from}, 昵称是{' '.join(nickname)}")
浏览器中输入如下:

点击提交之后
HTTPServerRequest对象
想一下我们使用requests模块访问得到的response一样,这个response是服务端给我们返回的信息,如果加上了request表示客户端向服务端请求时的信息
因此request:请求,response:响应
所以tornado的request作用就是储存了请求的相关信息
- method:http请求的方式
- host:请求的主机名
- uri:请求的完整资源地址,包括路径和get参数查询部分,注意是uri不是url
- path:请求的路径部分
- query:请求参数部分
- version:使用的http版本
- headers:请求的协议头是一个字典类型
- body:请求体数据
- remote_ip:客户端ip
view.py,其他的文件不变
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self):
self.write("<h1>请求的信息如下:</h1>")
self.write(f"<h2>self.request.method={self.request.method}</h2>")
self.write(f"<h2>self.request.host={self.request.host}</h2>")
self.write(f"<h2>self.request.uri={self.request.url}</h2>")
self.write(f"<h2>self.request.path={self.request.path}</h2>")
self.write(f"<h2>self.request.version={self.request.version}</h2>")
self.write(f"<h2>self.request.headers={self.request.headers}</h2>")
self.write(f"<h2>self.request.body={self.request.body}</h2>")
self.write(f"<h2>self.request.remote_ip={self.request.remote_ip}</h2>")
输入localhost:7777/satori,得到页面如下

tornado.httputil.HTTPFile对象
接收到的是一个文件对象,属性有name,body,content_type
filename: 文件名
body: 文件的数据实体
content_type: 文件类型
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>古明地觉</title>
</head>
<body>
<!--如果想上传文件,那么必须要加上enctype="multipart/form-data"-->
<form action="/satori" method="post" enctype="multipart/form-data">
<input type="file" name="picture">
<input type="file" name="picture">
<input type="file" name="txt">
<input type="submit" value="提交">
</form>
</body>
</html>
import tornado.web
import os
class SatoriHandler(tornado.web.RequestHandler):
def get(self):
self.render("satori.html")
def post(self, *args, **kwargs):
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
file_dict = self.request.files
'''
关于这里的file_dict,要详细的说一下
首先我们在html文件中,写了如下代码
<input type="file" name="picture">
<input type="file" name="picture">
<input type="file" name="txt">
那么在文件上传提交之后,我们获取file_dict便是一个字典
file_dict = {
"picture": [{"filename": "xxx", "body": "xxx", "content_type": "xxx"},
{"filename": "xxx", "body": "xxx", "content_type": "xxx"}],
"txt": [{"filename": "xxx", "body": "xxx", "content_type": "xxx"}]
}
我们在html中定义了name="picture"和name="txt"两个上传文件的input,那么"picture"和"txt"就是这个file_dict的两个key
每个key,分别对应一个列表。每个列表中存储的字典,便包含了上传文件的信息。因为可能上传多个文件,所以有多个字典。
比如我们这里的picture,列表里面就有两个字典,因为我们以name="picture"上传两个文件。
如果只有一个文件,那么key对应的value仍是一个列表,只不过这个列表里面只有一个字典,比如我们这里的txt
example:我们上传了,satori.jpg(name="picture")、koishi.jpg(name="picture")、mmp.txt(name="txt")
那么file_dict如下:
file_dict = {
"picture": [{"filename": "satori.jpg", "body": b"二进制文件内容", "content_type": "img/jpeg"},
{"filename": "koishi.jpg", "body": b"二进制文件内容", "content_type": "img/jpeg"}],
"txt": [{"filename": "mmp.txt", "body": b"二进制文本内容", "content_type": "text/plain"}]
}
'''
# 接下来便以上面的example进行上传
'''
name依次循环--->"picture","txt"
'''
for name in file_dict:
'''
file_arr依次循环--->[{"filename": "satori.jpg", "body": b"二进制文件内容", "content_type": "img/jpeg"},
{"filename": "koishi.jpg", "body": b"二进制文件内容", "content_type": "img/jpeg"}],
[{"filename": "mmp.txt", "body": b"二进制文本内容", "content_type": "text/plain"}]
'''
file_arr = file_dict[name]
'''
file_obj依次循环--->"{filename": "satori.jpg", "body": b"二进制文件内容", "content_type": "img/jpeg"},
{"filename": "koishi.jpg", "body": b"二进制文件内容", "content_type": "img/jpeg"},
{"filename": "mmp.txt", "body": b"二进制文本内容", "content_type": "text/plain"}
'''
for file_obj in file_arr:
# filename:文件名
filename = file_obj["filename"]
# body:文件内容
body = file_obj["body"]
# 文件类型
content_type = file_obj["content_type"]
# 创建了一个upload_files目录,专门用来存放上传的文件
with open(os.path.join(BASE_DIR, "upload_files", filename), "wb") as f:
f.write(body)
self.write(f"{filename}上传成功,文件类型为{content_type}<br>")

点击提交
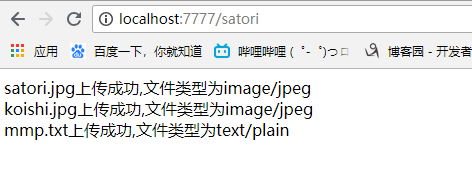
再来看看upload_files目录,有没有上传的文件

显然上传是成功了的,以上操作便可以完成文件的上传
响应输出
1.self.write
原型:self.write(chunk)
作用:将数据写到缓冲区
import tornado.web
import json
class SatoriHandler(tornado.web.RequestHandler):
def get(self):
self.write("我是self.write")
self.write("我的作用是将数据写到缓冲区")
# self.write还可以写入json文件
dic = {"name": "古明地觉", "from": "东方地灵殿"}
# 可以手动转化为json文件,那么Content-Type属性值为text/html
self.write(json.dumps(dic))
# 也可以直接利用write方法写入字典,那么Content-Type属性值为application/json
self.write(dic)
# self.finish(),表示手动关闭当次请求通道
# 在self.finish()下面就不要在self.write了,否则报错
self.finish()

2.self.set_header(name, value)
作用:手动设置一个名为name,值为value的响应头字段
参数:name,字段名称,value,字段值
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self):
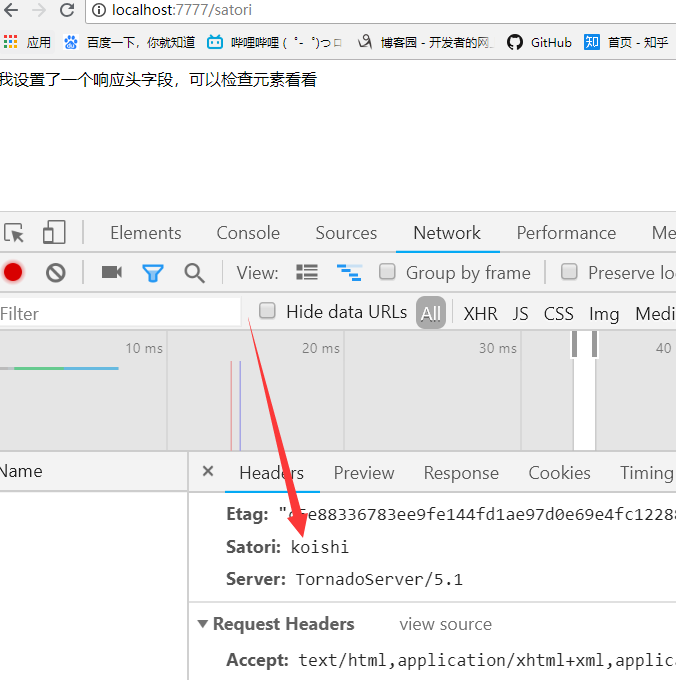
self.set_header("satori", "koishi")
self.write("我设置了一个响应头字段,可以检查元素看看")
3. set_default_header()
作用:在执行http方法之前被调用,可重写该方法预先设置默认的headers
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def set_default_headers(self):
self.set_header("zgg", 666)
self.set_header("mmp", 250)
def get(self):
self.set_header("satori", "koishi")
self.set_header("love", "satori")
self.write("我在两个地方设置了响应头字段")

4. self.set_status(status_code, reason=None)
作用:为相应设置状态码
参数:status_code,状态码值,为int,如果reason=None,那么状态码必须合法。
reason,描述状态码的词组,为string
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self):
self.set_header("satori", "koishi")
self.set_header("love", "satori")
# 404是合法的状态码,所以可以不指定reason
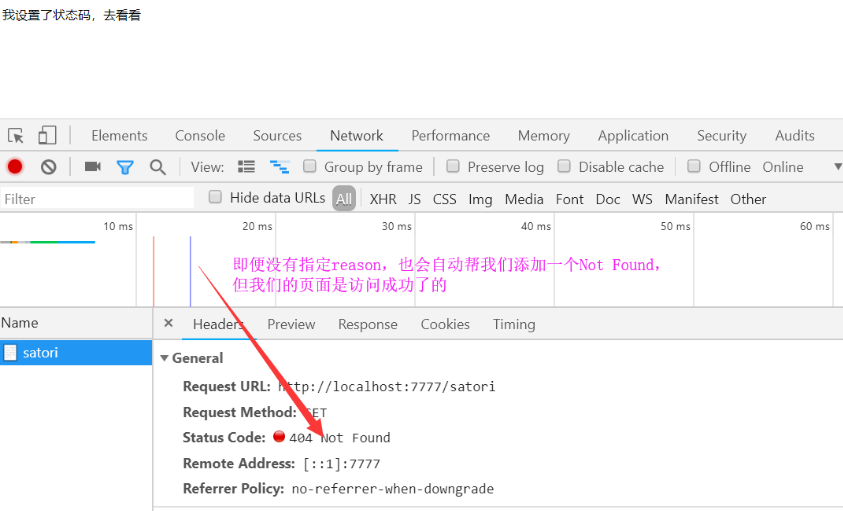
self.set_status(status_code=404)
self.write("我设置了状态码,去看看")
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self):
self.set_header("satori", "koishi")
self.set_header("love", "satori")
# 404是合法的状态码,指定一下reason
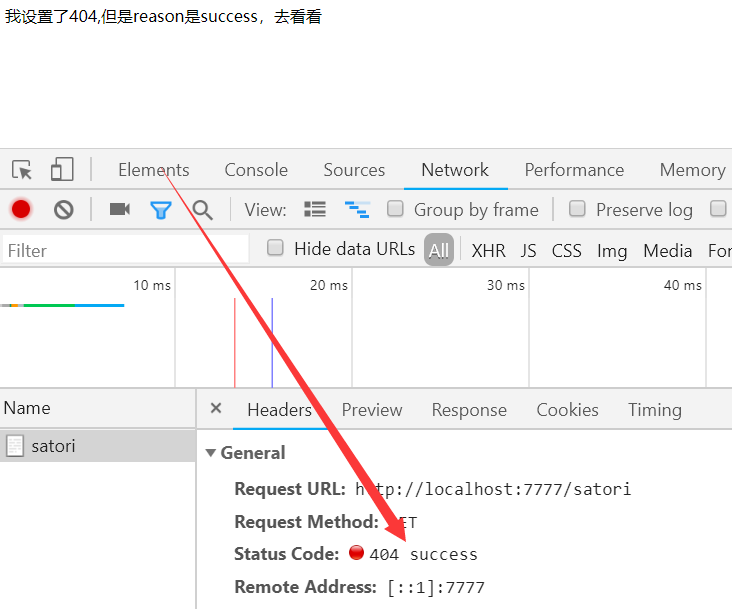
self.set_status(status_code=404, reason="success")
self.write("我设置了404,但是reason是success,去看看")
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self):
self.set_header("satori", "koishi")
self.set_header("love", "satori")
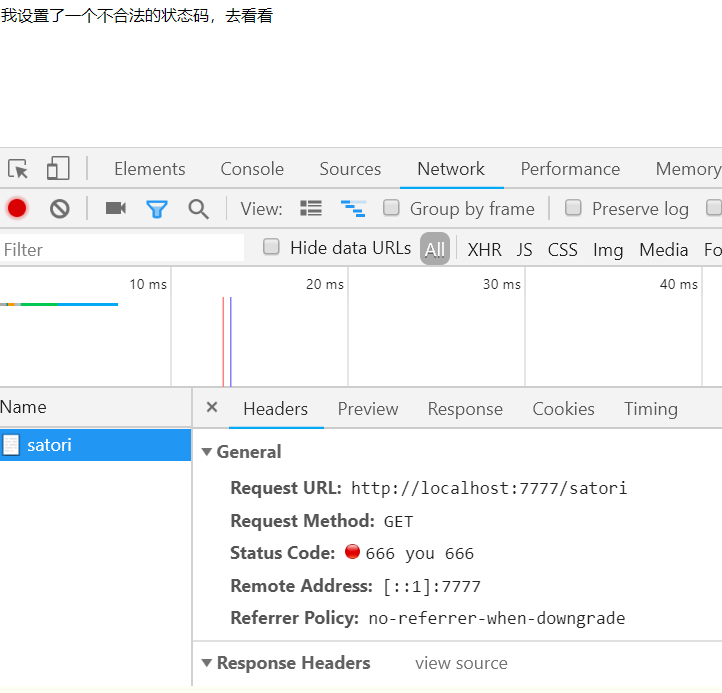
# 指定一个不存在的状态码,这时候要指定reason,否者状态码后面的描述是Unknow
# 因为我们在指定404的时候,这些合法的状态码都是有意义的
# 如404代表页面未找到,200代表成功,所以即使我们不指定reason,也会自动帮你添加
# 但是如果指定一个不存在的状态码,那么最好指定reason
self.set_status(status_code=666, reason="you 666")
self.write("我设置了一个不合法的状态码,去看看")
5. self.redirect(url)
作用:重定向到某个url
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self):
self.redirect("http://www.baidu.com")
输入网址回车,会自动跳转到百度
6. self.send_error(status_code=500, **kwargs)
作用:抛出http错误状态码,默认为500,抛出错误后,tornado会自动调用write_error进行处理,并返回给页面
注意:在self.send_error之后就不要再响应输出了
7. self.write_error(status_code=500, **kwargs)
作用:用来处理self.send_error抛出的异常,并返回给浏览器错误界面
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def write_error(self, status_code, **kwargs):
# self.send_error传入的状态码,会自动传入write_error当中
# self.write_error和self.send_error中的status_code是相同的
if status_code == 404:
self.set_status(404, "damn it!!!")
self.write("你妹的,活该资源找不到")
def get(self):
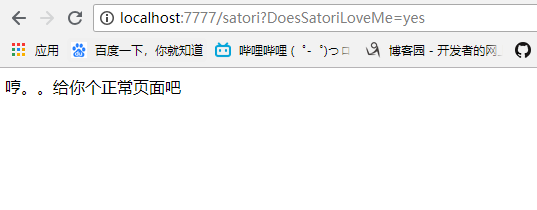
DoesSatoriLoveMe = self.get_argument("DoesSatoriLoveMe")
if DoesSatoriLoveMe in ["yes", "YES", "Yes"]:
self.write("哼。。给你个正常页面吧")
else:
self.send_error(404)

tornado请求与响应就先到这,下一节将介绍tornado的接口调用顺序与模板