tornado的话就不带着大家看源码了,今后可能会介绍,目前只是看简单的用法,而且当前的tornado版本不高,其实说白了这是很久以前写的文档,但是由于格式的原因,所以打算用Markdown重写一次。下面我们从一个简单的服务看看tornado是怎么启动的。
import tornado.web
'''
tornado基础web框架模块
'''
import tornado.ioloop
'''
tornado的核心循环IO模块,封装了linux的epoll和BSD的kqueue,是tornado高效的基础
'''
import tornado.httpserver
'''
tornado的server模块,用来创建服务端
'''
# 类比django中的视图
# 一个业务处理类,必须继承tornado.web.RequestHandler
class IndexHandler(tornado.web.RequestHandler):
# 用于处理get请求,不能处理post请求
def get(self, *args, **kwargs):
# 对应请求的方法
# 给浏览器相应信息
self.write("<h1>欢迎来到古明地觉的避难小屋</h1>")
if __name__ == '__main__':
# 实例化一个app对象
# Application,是tornado web框架的核心应用类,是与服务器对应的接口
# 里面保存了路由映射表,我们可以使用listen方法来创建一个http服务器的实例,并绑定端口
app = tornado.web.Application([
(r"/index", IndexHandler)
])
# 绑定监听端口
'''
app.listen(8080)
'''
# 但是我们还可以用其他的方法
# 可以手动创建一个服务器,将包含一系列路由映射的app传进去
# 这和app.listen(8080)是一样的
# 注意:此时只是绑定了监听端口,但是并没有开启监听
httpserver = tornado.httpserver.HTTPServer(app)
httpserver.listen(8080)
# IOLoop.current()返回了一个IOLoop实例
# 然后start()启动实例的I/O循环,同时开启监听
tornado.ioloop.IOLoop.current().start()
执行,然后在浏览器中输入localhost:8080/index

通过访问localhost:8080/index, 界面显示了出来。但是这样有一点不好,就是端口写死了,如果我要是监听其他端口呢?这样写的话,就意味着我每修改一次端口,都要改一次代码。
显然这不具有灵活性,因此我们可以通过命令行来执行程序的时候,将端口传进去,然后用变量接收 ,tornado也为我们提供了这样一个方法
import tornado.web
import tornado.ioloop
import tornado.httpserver
import tornado.options
'''
专门用来做命令行参数解析以及全局参数的定义,存储,转换
'''
# 定义两个参数
tornado.options.define("port", default=8888, type=int)
tornado.options.define("name_list", default=[], type=str, multiple=True)
'''
函数的原型是:tornado.options.define(name, default=None, type=None, multiple=False)
name:选项的变量名,必须保证唯一性,否则报错"option 'xxx' already defined in ...."
default:默认值,如果不传的话,会使用默认值
type:设置选项变量的类型,会自动进行转换。如果定义的是int,那么会转换成int。
如果没有设置,那么会根据default的值进行转换,如果default没有设置,那么不转换
multiple:设置选项变量是否为多个值,默认为False,如果想以列表形式接收多个值,那么必须设置此选项为True
'''
# 定义业务处理类,必须要继承自tornado.web下的RequestHandler
class IndexHandler(tornado.web.RequestHandler):
def get(self, *args, **kwargs):
self.write("多睡觉,少操心")
print(tornado.options.options.name_list)
if __name__ == '__main__':
# 转换命令行参数,然后会自动将输入的参数保存到tornado.options.options中
tornado.options.parse_command_line()
app = tornado.web.Application([
(r"/index", IndexHandler)
])
httpserver = tornado.httpserver.HTTPServer(app)
# 所有的参数都在tornado.options.options下
# 这和optparse类似,算是一个属性,通过.来访问
httpserver.listen(tornado.options.options.port)
'''
其实httpserver.listen(),也可以分为两步
(1) httpserver.bind(port), 将服务器绑定到指定的端口
(2) httpserver.start(num), 默认开启一个进程,值大于0,创建对应个数个子进程,小于0,创建对应cpu核心数的子进程
所以这算是一种开启多进程的方式,但是出于一些原因,我们不建议这么用,而是手动开启多个进程,原因有三:
1.每个子进程都会从父进程中复制一份IOLoop实例,如果创建子进程之前修改了IOLoop,会影响所有的子进程
2.所有的进程都是由一个命令启动的,无法做到在不停止服务的情况下修改代码
3.所有进程共享一个端口,想要分别监控很困难
'''
tornado.ioloop.IOLoop.current().start()
通过命令行开启服务

在浏览器中输入localhost:8888/index

得到界面如下,同时也打印了name_list

除了从命令行解析参数,还可以从配置文件当中解析,使用函数tornado.options.parse_config_file("config_file"),其他的用法一样。
并且配置文件的书写格式仍然要按照python语法要求,不支持字典类型。
无论是使用从命令行解析还是从配置文件中解析,tornado都会默认开启logging功能,向屏幕终端打印一些信息,如果想关闭日志
可以在命令行当中加上--logging=None,或者在代码中加入tornado.options.options.logging = None
但是实际情况这两种方法,我们都不推荐,因为比较麻烦,最好的方式是将端口等信息写在一个py文件里,然后从py文件里面读取,这样的话只需要修改py文件即可

导入config.py文件,然后使用config.options["port"]即可
此外补充一点:为什么app.listen(8080)和httpserver = tornado.httpserver.HTTPServer(app), httpserver.listen(8080)是一样的,我们可以看一下源码
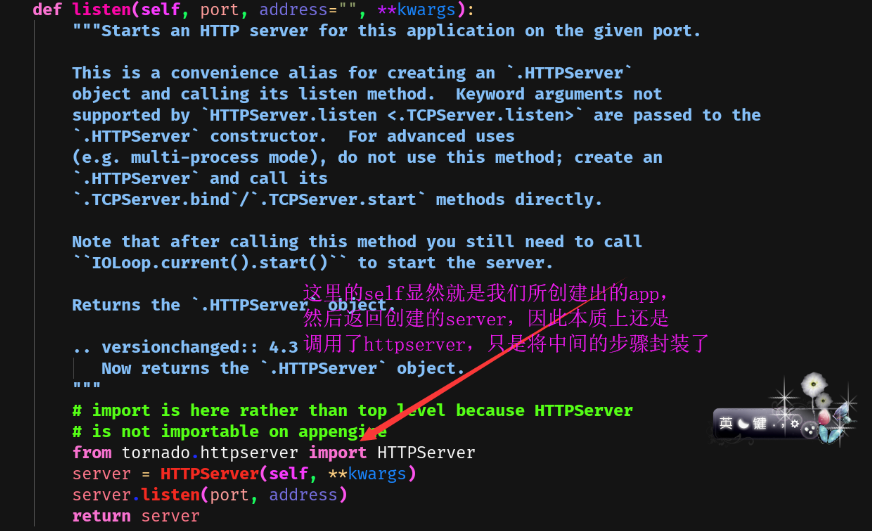
看到这里,基础流程应该大致都了解了,那么我们的代码结构也要改一改了
显然我们这里所有的代码都写在一个文件里,如果对应的handler变多,那么把所有代码都写在一个py文件里显然是非常非常不好的,况且还有配置文件,html模板,css,js等等。
因此我们必须要分级,可以将之前的代码改写一下
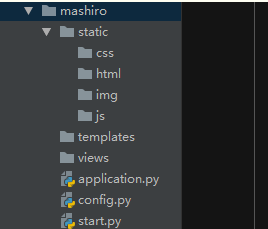

views/view.py
import tornado.web
class IndexHandler(tornado.web.RequestHandler):
def get(self, *args, **kwargs):
self.write('<h1 style="text-align: center">my name is satori</h1>')
application.py
import tornado.web
from views import view
import config
# 我们可以自定义一个Application,但是要继承tornado.web下的Application
class Application(tornado.web.Application):
def __init__(self):
# 进行路由映射,导入views下的view
# 不同的业务肯定有不同的view,我们这里就只创建一个view
handlers = [
(r"/index", view.IndexHandler)
]
# 我们自己定义的handler最终肯定要交给父类去执行一下
# 同时将我们config下的settings使用**打散,传进去
super(Application, self).__init__(handlers=handlers, **config.settings)
config.py
options = {"port": 7777}
# 这里的settings,后面再说,先随便传一个
settings = {"aa": "bb"}
start.py
import tornado.ioloop
import tornado.httpserver
from application import Application
import config
app = Application()
server = tornado.httpserver.HTTPServer(app)
server.listen(config.options["port"])
tornado.ioloop.IOLoop.current().start()
可以看到,这与我们之前写在一个py文件里面的内容基本上一样的,但是我们很好地将各个部分进行了分离,不同的部分放在了不同的py文件里。像view,当我们建立网站的内容比较多的时候,所有的业务对应的handler写在一个view文件里也不好。因此定义一个views文件夹,里面存放多个view,每一个业务对应一个view。
然后执行start,也就是启动文件
可以看到开启服务是没有问题的
而且像django或者golang里的beego框架一样,调用命令创建项目的时候,框架会直接帮你创建好相应文件夹和文件。以后我们创建tornado项目,便也可以按照这种模式,手动创建相应文件夹,每个部分完成每个部分的功能。
各个部分之间分离,不会受到彼此的影响。config写配置,views写handler,也就是业务处理逻辑,application则是写路由映射关系,static则是静态文件,templates是模板,而最后的start则是启动文件,将其他的模块导入进来,然后启动。
最后还有一个小插曲,关于tornado的原理,tornado的高性能主要来源于两方面,一个是基于epoll的IO多路复用,另一个是异步。异步以后再说,先来看看tornado的IO多路复用
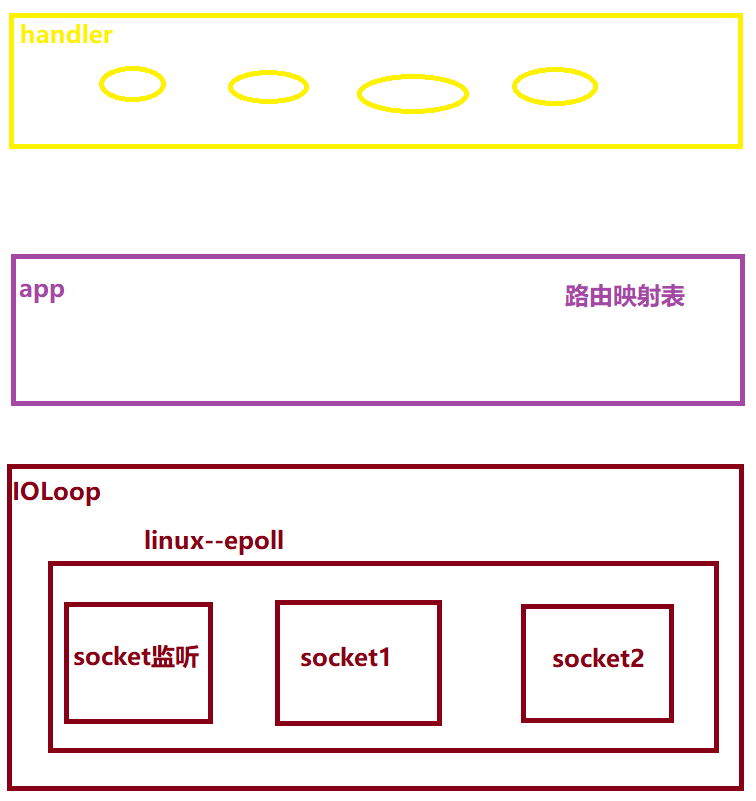
首先tornado封装了epoll,这个epoll就相当于是我们的管家。首先创建一个socket,这个socket只是用来监听新链接的到来,不做请求处理。当一个新链接过来时,会专门创建一个与之交互的socket,同时将监听的socket所获取的链接移到新创建的socket上面。
然后用于监听的socket继续监听,每当新来一个链接就创建一个socket与之进行交互。socket建好了,但是对方不一定就发了请求。
于是管家epoll就不断地循环监听这些socket,而我们的IOLoop是全局总调度器,它不用去亲自去监听是否有活跃的socket,因为管家epoll已经帮忙做了。
那么IOLoop的任务就是不断地问epoll,有没有活跃的socket。就这样不停地询问,直到epoll说有了,然后便将获取到的请求进行路由映射,找到对应的handler,执行相应的业务逻辑。