安装Git
安装依赖软件
yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel asciidoc
yum install gcc perl-ExtUtils-MakeMaker
编译Git
cd /usr/local/src/
tar -zxvf git-2.1.2.tar # 解压下载好的tar包
cd git-2.1.2
make prefix=/usr/local/git all
make prefix=/usr/local/git install
echo "export PATH=$PATH:/usr/local/git/bin" >> ~/.bashrc
source ~/.bashrc
输入git --version查看
安装PostgreSQL
# 安装对应的postgresql的yum源
rpm -Uvh https://download.postgresql.org/pub/repos/yum/9.4/redhat/rhel-7-x86_64/pgdg-centos94-9.4-3.noarch.rpm
yum update # 更新yum
# 执行安装命令
yum install postgresql94-server postgresql94-contrib
# 检查是否安装成功
rpm -qa| grep postgres

# 初始化数据库
/usr/pgsql-9.4/bin/postgresql94-setup initdb

# 启动服务并设置为开机启动
systemctl enable postgresql-9.4
systemctl start postgresql-9.4
# 访问postgresql
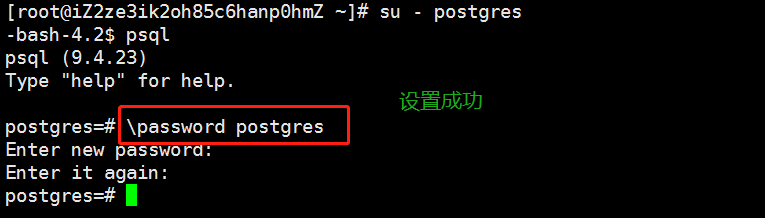
su - postgres
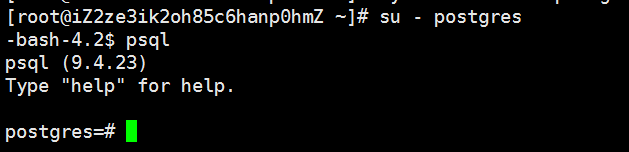
# 设置postgres用户密码
# 会自动有一个postgres用户,设置密码
password postgres
安装MySQL
下载rpm包: wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm安装rpm: rpm -ivh mysql-community-release-el7-5.noarch.rpm更新yum源: yum update安装mysql服务端: yum install mysql-server初始化mysql:mysqld --initialize启动mysql:systemctl start mysqld查看mysql运行状态,这一步可以省略:systemctl status mysqld查看版本,如果出现了版本输出,说明正确安装了:mysqladmin --version
我这里输出为:mysqladmin Ver 8.42 Distrib 5.6.45, for Linux on x86_64
设置密码
默认安装完之后是没有密码的,使用这一行设置密码。不过会提示你,在命令行设置密码不安全,所以别让人偷看哦,不过是可以设置成功的
mysqladmin -u root password "new_password"
- 进入mysql
mysql -u root -p
会提示你输入密码,输入刚才设置的密码,然后就进入了mysql命令行
安装单机版ElasticSearch
介绍
elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口,百度是这么告诉我的。里面出现的Lucene也是一个用于搜索的引擎,但是elasticsearch对其做了封装,提供了更友好的api,并且可扩展性非常好,而且安装简单。
太多的概念我就不说了,网上一大堆,下面来看看怎么安装。
安装
安装的话可以使用docker,但是这里我们还是采用下载tar包的方式。我的安装目录为/opt/elasticsearch,记得顺便安装一下jdk。
首先进入官网下载,https://www.elastic.co/cn/downloads/elasticsearch,最新版本是7.5.2,直接点击下载即可,但我这里使用的不是最新版,而是5.6.16版本的,具体使用哪个版本由你自己决定。
丢进去解压即可,最后目录长这个样子。启动文件在bin目录里面,为了执行方便,可以加到环境变量里面。
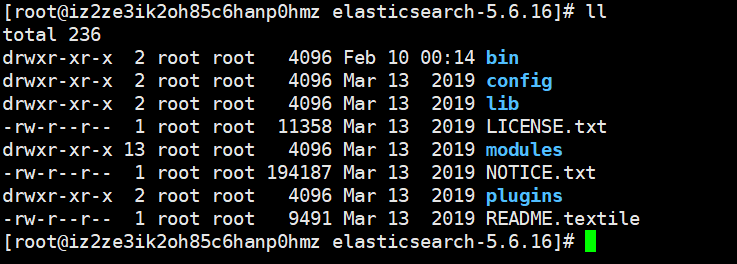
所有大数据组件目录基本上都差不多,目录的含义应该不用我介绍了。
不过我们需要改一个配置文件,因为es有一个特点就是不能以root来启动,因为es要访问大量的文件、并且可以接收用户的脚本来执行,因此为了安全不允许使用root用户启动,最好的办法是创建一个普通用户,然后把相关目录的操作权限赋给这个新用户。
useradd xxx
passwd xxx
chown -R xxx:xxx elasticsearch目录
然后修改配置文件,只需要改一个即可。至于端口,默认有两个端口9200和9300,当然也是可以改的,我们这里就不改了。
# 在config里面有一个elasticsearch.yml,这就是我们修改的配置文件
# 但是里面全部被注释掉了,所以我们就不把注释打开了,直接在文件尾部添加即可
network.host: 0.0.0.0 # 为了能够让其他机器通过web访问
# 至于其他的参数可以参考这个配置文件
我们使用新创建的用户启动,如果直接启动还是会报出错误。
ERROR: [2] bootstrap checks failed
[1]: max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536]
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
意思就是用户可以配置的文件数量太少、可使用的最大虚拟内存太小,我们还需要改一下。
-
vim /etc/security/limits.conf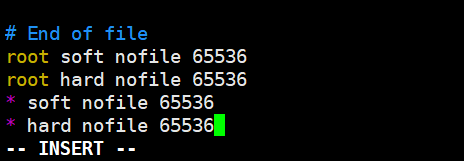
-
vim /etc/sysctl.conf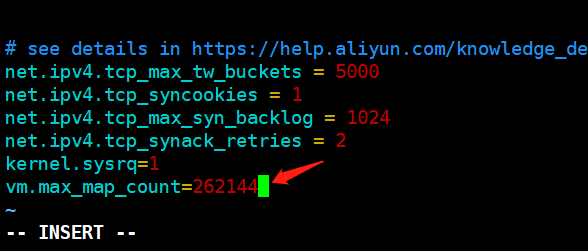
-
然后执行sysctl -p即可
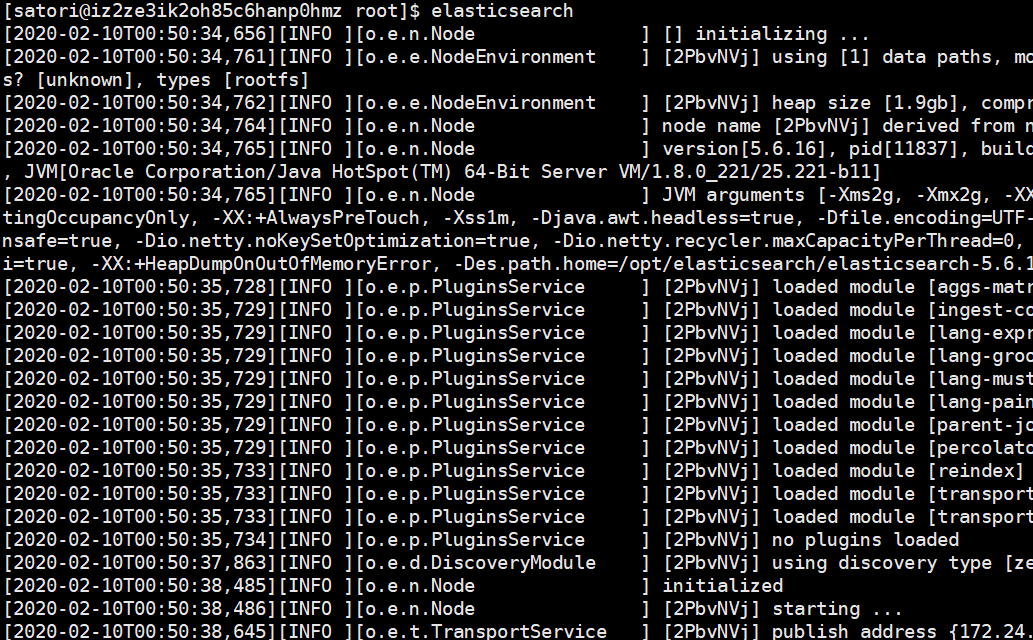
此时以普通用户satori启动就成功了,我们来通过web页面查看一下,端口是9200
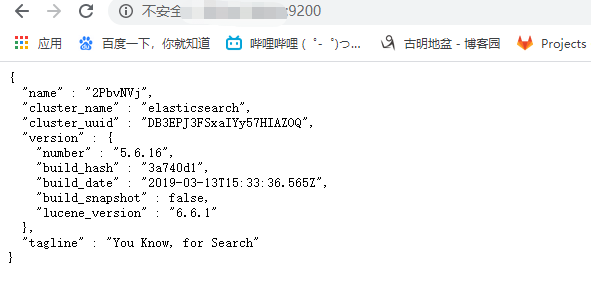
如果能够出现如下内容,说明安装成功。所以es的安装还是比较简单的,我们总结一下流程。
安装jdk安装es包,解压修改配置文件,将network.host: 192.168.0.1改成network.host: 0.0.0.0,这样其它机器才可以访问但是es对可打开的文件数量和可使用的虚拟内存有要求,所以我们需要再改两个系统的配置文件最后创建一个新用户,或者已有的也行,总之不能是root。因为root的权限太高,es要操作大量文件的时候不能有太高的权限,更何况它还可以执行用户自己编写的脚本。总之就是以一个不是root的用户启动就行。
es相关概念
es是基于Lucene开发的分布式全文检索框架,存入es中的数据、和从es中查询得到的数据都是json格式的。首先在es中有几个概念我们必须要知道:
索引:Index,相当于数据库的database类型:Type,相当于数据库的table主键:id,相当于数据库的主键
因此我们往es中存储和查询数据,其实就是往es的Index下的Type中存储和查询。
es支持restful风格api,至于什么restful可以网上搜索一下,这是一套工业标准。总之我们可以使用http的方式来对数据进行增删改查
查询数据:http的get请求插入数据:http的put/post请求修改数据:http的put/post请求删除数据:http的delete请求
安装python的airflow
Linux安装python的airflow
首先创建一个airflow目录:mkdir ~/airflow
配置环境变量:export AIRFLOW_HOME=~/airflow
安装airflow包、以及相关组件
pip3 install apache-airflow
pip3 install apache-airflow[celery,crypto,mysql,password,redis]
然后执行airflow version 产生配置文件
然后修改配置文件,我们刚才创建的airflow目录里面有一个airflow.cfg,所有的配置都在里面。因为airflow默认使用sqlite,这里我们换成PostgreSQL,当然其它数据库也是可以的。

这里我们指定的数据库是airflow,所以我们PostgreSQL中必须要先创建一个名为airflow的数据库
然后执行airflow initdb即可初始化数据库
再执行airflow webserver -D即可开启webUI,我们通过web页面就可以进行调度。默认监听8080端口,当然监听的端口也可以在$AIRFLOW_HOME/airflow.cfg中修改
基本使用
# test_dag1.py
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.utils import dates
from airflow.utils.helper import chain
from datetime import datetime, timedelta
default_args = {
'owner': 'airflow', # 任务所有者
'depends_on_past': False, # 是否依赖于过去。如果为True,那么必须要昨天的任务执行成功了,今天的才能执行
'start_date': dates.days_ago(1), # 任务的开始时间。这个参数会影响到部署上线时回填任务的数量。一般建议写成上线时间的前一天
'email_on_failure': True, # 任务失败且重试次数用完时是否发送Email
'email_on_retry': False, # 任务重试时是否发送Email
'retries': 1, # 任务失败后的重试次数 默认1
'retry_delay': timedelta(minutes=5), # 任务失败后启动重试的时间间隔
}
dag = DAG(
'HANSER', # dag名字,我们必须创建一个dag
default_args=default_args, # 参数
schedule_interval=timedelta(days=1)) # 调度的时间间隔
def func1(**kwargs):
print("执行func1", kwargs)
def func2(**kwargs):
print("执行func2", kwargs)
def func3(**kwargs):
print("执行func3", kwargs)
# 定义任务,每个任务都会附属在dag上面
t1 = PythonOperator(
task_id='t1_id', # 任务的id
provide_context=True, # 外界可以传递参数,需要使用PythonOperator 的provide_context=True 来获取外界参数。
# 所以我们在函数中定义了**kwargs来进行接收
python_callable=func1, # 执行的函数,传入名字
dag=dag # dag
)
t2 = PythonOperator(
task_id='t2_id',
provide_context=True,
python_callable=func2,
dag=dag)
t3 = PythonOperator(
task_id='t3_id',
provide_context=True,
python_callable=func3,
dag=dag)
# 我们希望三个任务依次执行,那么就可以使用
chain(t1, t2, t3)
# 或者使用t1 >> t2 >> t3也可以实现
# 也等价于
"""
t1.set_downstream(t2)
t2.set_downstream(t3)
"""
然后看一些常用命令
-
python3 test_dag1.py如果没有报错,那么证明该文件在语法上没有错误,airflow是可以调度的 -
airfow list_dags:查看所有的dag

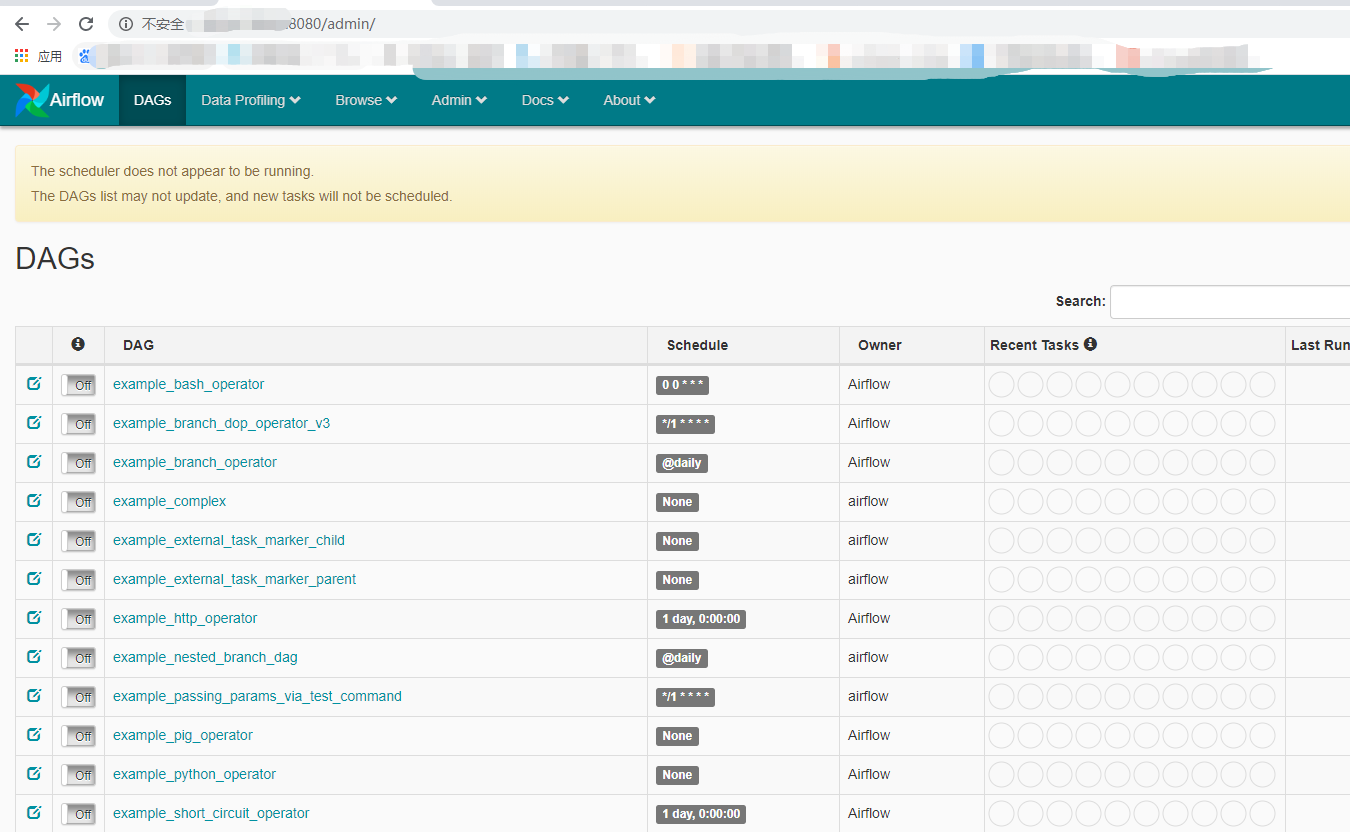
我们看到创建的dag显示在上面了,当然airflow本身还有默认的dag
airflow list_tasks <dag_id>:查看某个dag的所有task

airflow test <dag_id> <task_id> <execution_date>:测试某一个任务

任务t1开始执行了,而且还给我们传递了很多额外的参数,这些参数就是通过**kwargs传递的
里面有两个时间参数比较重要:execution_date:airflow的执行时间,就是我们在命令行中传递的时间。prev_execution_date:执行时间的上一天
-
airflow run <dag_id> <task_id> <execution_date>:运行某个任务,和airflow test类似,但是我们的print没有输出了 -
airflow backfill <dag_id> -s 2015-06-01 -e 2015-06-07:在一个时间段内运行,-s开始时间、-e结束时间 -
airflow clear <dag_id>:清空任务状态 -
airflow trigger_dag <dag_id>:运行某个dag,所有任务一起运行,当然也可以通过webUI进行操作。
但是如果运行我们刚才的dag的话,是会报错的,显示找不到这个dag
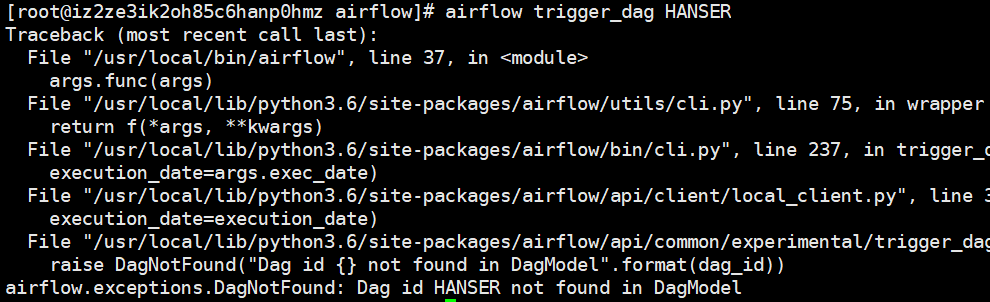
之所以出现这个错误,是因为还没有对dag进行更新,我们需要开启调度器,更新创建的dag
airflow scheduler -D:运行调度器

此时就运行成功了,只不过打印信息没有显示。除此之外,我们还可以通过webUI来进行调度,和airflow trigger_dag是一样的。
离线安装PostgreSQL
首先进入到https://www.postgresql.org/ftp/source/中,会看到各种不同版本的PostgreSQL,这里我们选择的版本为10.12,首先10表示大版本,后面12属于小版本。大版本一定选择10,因为大版本不同,会导致相关操作不太一样,但是小版本的话没有太大影响。总共有13个小版本,这里我们就选择靠后一些的。

点击进去,再点击后缀为tar.gz的,即可开始源码包的下载,我同样放在了software目录下

安装完毕之后丢到服务器上面,我们的软件统一安装在/opt下面,所以首先要mkdir -p /opt/postgres创建相应目录,然后执行tar -zxvf postgresql-10.12.tar.gz -C /opt/postgres加压到该目录中。
编译安装
PostgreSQL的编译安装方式和Python有些类似,进入到/opt/postgres/postgresql-10.12之后
chmod 755 configure
# 我们直接安装在/opt/postgres/下面, 可以避免污染环境
./configure -prefix=/opt/postgres/ --without-readline
# 编译安装
make && make install
然后我们在cd到contrib目录中,执行make && make install,这里安装contrib目录下的一些第三方组织的一些工具代码
cd contrib
make && make install
创建目录
因为PostgreSQL会默认将数据写在data目录下,所以执行
mkdir -p /opt/postgres/data
但是PostgreSQL不允许使用root用户初始化数据库,所以需要创建一个新用户,就叫postgres吧
# 创建组和用户
groupadd postgres
useradd -g postgres postgres
可以的话,也可以设置用户postgres的密码,我这里没有设置。通过passwd postgres即可设置
然后将/opt/postgres/的权限交给postgres用户
chown postgres:postgres /opt/postgres -R
chown postgres:postgres /opt/postgres/data -R
通过命令su postgres切换至postgres用户,在其~/.bashrc中加入如下内容,并进行source
export PGHOME=/opt/postgres/
export PGDATA=/opt/postgres/data
export PATH=$PGHOME/bin:$PATH
export PATH=$PATH:/opt/postgres/bin
export MANPATH=$PGHOME/share/man:$MANPATH
export LANG=en_US.utf8
export DATE=`date +"%Y-%m-%d %H:%M:%S"`
export LD_LIBRARY_PATH=$PGHOME/lib:$LD_LIBRARY_PATH
alias rm='rm -i'
alias ll='ls -lh'
#alias pg_start='pg_ctl start -D $PGDATA'
#alias pg_stop='pg_ctl stop -D $PGDATA -m fast'
初始化数据库
initdb -D /opt/postgres/data
如果出现如下信息,说明执行成功

启动服务
安装PostgreSQL提供的信息,启动服务
pg_ctl -D /opt/postgres/data -l logfile start

启动成功
登录测试
# 输入psql进入默认数据库postgres中
psql
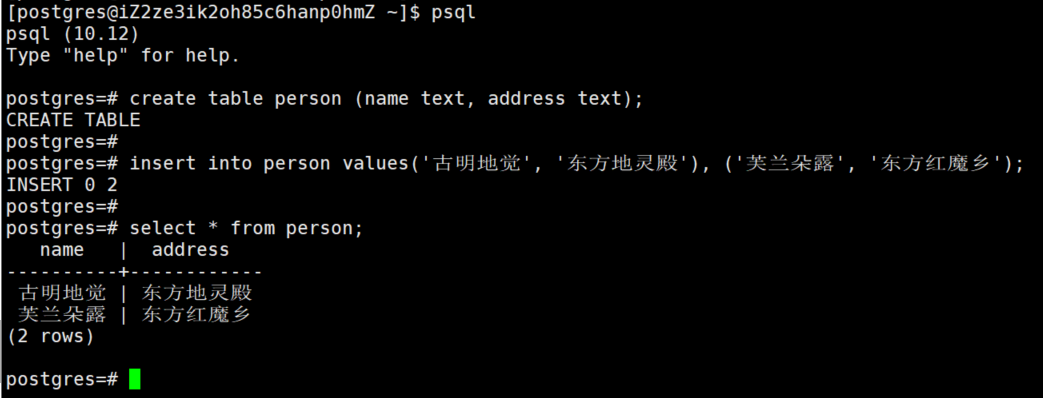
# 创建一个表吧
create table person (name text, address text);
# 插入数据
insert into person values('古明地觉', '东方地灵殿'), ('芙兰朵露', '东方红魔乡');
# 查询数据
select * from person;
配置设置
我们可以通过/opt/postgres/data/postgresql.conf、/opt/postgres/data/pg_hba.conf来进行设置
服务启动与与停止
# 重启
pg_ctl -D /opt/postgres/data -l /opt/postgres/logfile restart
# 停止
pg_ctl -D /opt/postgres/data -l /opt/postgres/logfile stop
# 查看端口是否启用
netstat -anp | grep 5432