楔子
什么是词云?在网络上我们经常可以看到一张图片,上面有一大堆大小不一的文字,便是词云。词云一般是根据输入的大量词语生成的,如果某个词语出现的次数越多,那么相应的大小就会越大。我们后面演示的时候就知道了
安装
python中有一个专门用来生成词云的模块:wordcloud,如果在linux上直接pip install wordcloud即可,但是在Windows上会失败,我们可以去https://www.lfd.uci.edu/~gohlke/pythonlibs/这个官网下载合适的版本,然后安装即可。
生成词云
我们词云的主要实现是用过 wordcloud 模块中的 WordCloud 类实现的,我们先来了解一下这个 WordCloud 类。
# 导入模块
from wordcloud import WordCloud
# 准备文本数据,是一个字符串,单词之间用空格分割
sentence = "hello satori hello mashiro hello satori"
# 创建词云对象
wc = WordCloud()
# 根据文本生成词云
wc.generate(sentence)
# 保存为图片
wc.to_file("1.png")

我们看到单词就显示在了图片上,如果单词一多就像天空的云彩一样漂浮着,并且如果单词出现的频率越高,那么该单词在图片上大小就越大。
虽然词云生成了,但是风格是固定的,我们可不可以调整呢,显然是可以的。
可以向WordCloud里面传入参数来调整风格,我们先看看这个类里面都支持哪些参数,后面会演示
width:词云的宽,默认是400像素height:词云的高,默认是200像素background_color:词云的背景颜色,默认是黑色font_path:生成的词云所使用的字体,传入一个字体所在的路径mask:词云背景图片,接收一个numpy中的数组。可以使用PIL或者cv2读取图片,然后生成数组stopwords:要屏蔽的词语,接收一个集合,生成词云的时候会忽略掉屏蔽的词语max_font_size:字体的最大大小,默认为Nonemin_font_size:字体的最小大小,默认为Nonemax_words:要显示的词的最大个数,默认为200。比如我们的文本数据有10000个单词不重复单词,肯定不可能全部显示,而是按照出现的频率高低排序,选择出现频率高的N个单词,默认是200个contour_width:轮廓粗细contour_color:轮廓颜色scale:用来控制生成的图片大小的,默认为1。如果我们改成了10,那么生成的图片大小会扩大10倍。这个参数不用管,没太大用,默认为1即可
我们来演示一下这些参数
from wordcloud import WordCloud
sentence = "She is neither heterosexual nor homosexual She is sapiosexual"
wc = WordCloud(
width=500, # 设置宽度为500px
height=300, # 设置高度为300px
background_color='pink', # 设置背景为粉色
stopwords={"heterosexual", "homosexual"}, # 设置禁用词,在生成的词云中不会出现set集合中的词
max_font_size=100, # 设置最大的字体大小,所有词都不会超过100px
min_font_size=10, # 设置最小的字体大小,所有词都会超过10px
max_words=10 # 最多生成10个词,当然这里单词比较少,看不出来什么
)
wc.generate(sentence)
wc.to_file("2.png")
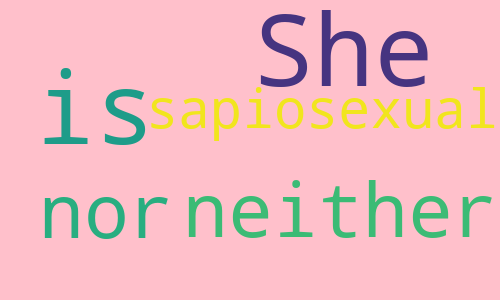
我们看到图片变宽了、变高了,背景变成粉色了,并且也没有出现我们禁用的单词
但是这个图片是正方形的,而我们平常见到词云是有形状的,可以是一个圆形、或者一个人的形状等等。显然那是根据图片生成的,而wordcloud也支持我们这么做,下面来演示一下
from wordcloud import WordCloud
from PIL import Image
import numpy as np
# 一篇英文文章
sentence = open("1.txt").read()
# 加载一张图片,转化成numpy中的数组
mask = np.array(Image.open("哆啦A梦.png"))
# 传入mask
wc = WordCloud(mask=mask)
wc.generate(sentence)
wc.to_file("3.png")

下面是我们原始的图片,"多啦A梦.png"

会自动将周围的白色区域给忽略掉,因此选择的图片建议最好是白底的。
我们目前生成词云所使用的单词都是英文的,那中文可不可以呢?我们来看一下
from wordcloud import WordCloud
wc = WordCloud()
wc.generate("古明地觉真的是世界上最可爱的美少女")
wc.to_file("4.png")
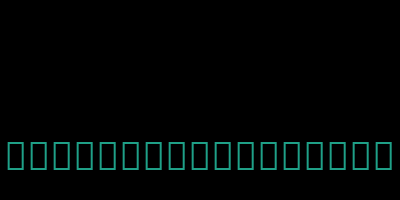
显然默认是不支持的,显示的是一个个的矩形。那怎么解决呢,很简单,指定一个支持中文的字体就可以了
from wordcloud import WordCloud
wc = WordCloud(font_path="msyh.ttc")
wc.generate("古明地觉真的是世界上最可爱的美少女")
wc.to_file("5.png")

但是显示的是一整句话,很正常,因为wordcloud默认是以空格分隔单词的,所以对于英文我们不需要做什么处理,因为英文单词之间就是以空格分隔的。但是中文,则是所有的汉字都连在一起,因此整体被当成了一个词。因此这个时候推荐使用jieba分词,将单词进行分隔,但是jieba怎么使用我们就不细致讲解了,我的其它随笔里面有介绍。
这里以出师表为例,演示一下
from wordcloud import WordCloud
import jieba
sentence = open("1.txt").read()
# 分词得到列表,手动使用空格拼接
sentence = " ".join(jieba.cut(sentence))
wc = WordCloud(font_path="msyh.ttc")
wc.generate(sentence)
wc.to_file("6.png")
