结构

从 expert 角度
1. experts 其实是一个个小兵,将不同的输入数据映射到不同的空间,只 fit 这一部分的 "local" 数据。
reference: https://www.cs.toronto.edu/~hinton/csc321/notes/lec15.pdf
所以我理解 expert 一定要用非线性激活函数。
从 gate 角度
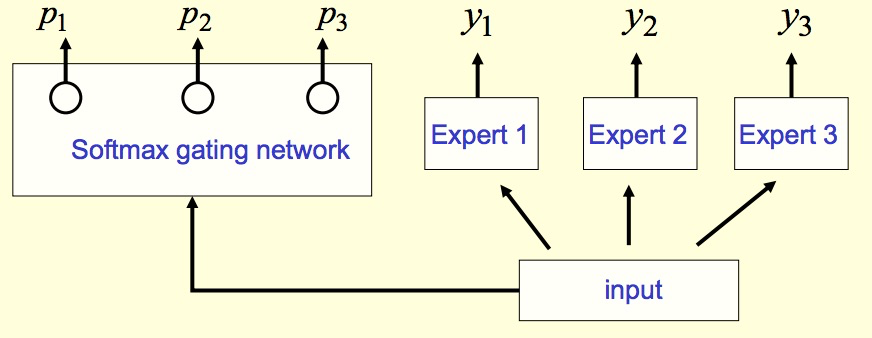
why gate 输入 input
gate 之所以也要以 input 作为输入,就是因为他要去判断,针对当前的输入数据,哪个 expert 表现的更好。一种 'stack model' 的感觉。
softmax真的好嘛
使用 softmax 起到了 weighted_sum stack 多模型的效果。
但是从实践和paper的说法,因为 softmax 有 exp的操作,会让 gate 输出的分数之间差距越来越大,最后就只让一个 expert 起到作用,即“极化”现象。
论文里面的操作是加入 dropout。我还想过,gradient clip,去掉 softmax 直接用 linear 映射,以及调整 learning rate。
mmoe
几个任务对应几个 gate,于是,不同任务可以有完全不同的 experts 组合方式。
softmax的梯度推导
reference: http://www.adeveloperdiary.com/data-science/deep-learning/neural-network-with-softmax-in-python/

多种组合方式

Reference: https://t.cj.sina.com.cn/articles/view/2674405451/9f68304b01900tidf