https://ai.51cto.com/art/202102/644214.htm
问题1:CTR 模型缺乏个性化
问题:
快手认为,DNN, DeepFM这一类简单的全连接深度模型,在全局用户的共建语义模式下缺乏个性化。
目标:
在网络参数上为不同用户学习一个独有的个性化偏差。
借鉴:
LHUC,为每个说话人学习一个 hidden unit contribution。
快手的做法:
PPNET,parameter personalized net。一种 gating 机制,可以增加DNN网络参数个性化,并加速模型收敛。
快手的效果:
2019年全量上线,显著提升CTR 目标的预估能力。
具体做法:
1. gateNN:
- 输入
id 类特征,包括, user_id, photo_id, atyhor_id。
原始输入给模型的所有特征的 embedding。
这两类特征的 embedding 会拼接在一起,作为 gateNN 的输入
- 结构
2层神经网络
第二层的激活函数是 2*sigmoid。目的是将约束控制在 【0, 2】,默认值是1。当默认值是1时,等价于原始的模型。
2. 每一层神经网络的输入,多增加了和 gatenn 的 element-wise product,以此作为个性化偏置。
3. gateNN 不对原始网络做梯度下降,以防防止收敛。

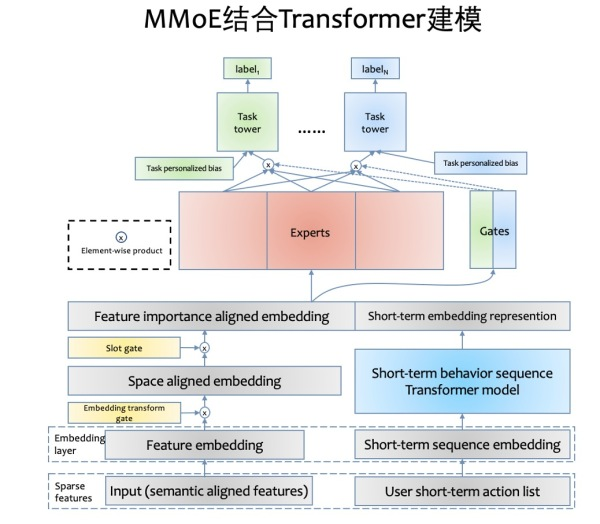
多目标模型
背景: 训练数据里面包含双列发现页和全屏精选页两种异构数据。
快手认为:单列交互行为都是基于 show 发生的 (很像我们的 feed),并没有像双列那样有非常重要的点击行为(很像我们的push)。
快手做的工作:
- 模型层面,尝试拆解出单列的数据,单独优化。
- 特征层面,复用双列模型特征,只是针对单列的目标,需要额外添加个性化偏置特征和统计特征。
- embedding 层面,前期单列的数据少,不能保证收敛。
- 最初使用双列数据主导训练
- 后面改用单列用户数据主导训练
- 网络结构
- 基于 shared-bottom,不相关的目标独占一个 tower。
- 暴露的问题
- 没有考虑到单双列的 embedding 分布差异,造成了 embedding 学习不充分。
快手的改进工作
- 模型层面,将 shared-bottom 网络替换成 mmoe 的 expert 层
- 特征层面,进行了语义统一,修正在单双列业务中语义不一致特征(click_history feed流里面用的是全部的点击历史,push只用了push的 show history 是不是要统一)
- embeeding 层面,空间映射,设计了 embedding transform layer。帮助单双列 embedding映射到统一空间分布。
- 特征重要性层面,slot-gating layer,为不同业务做特征重要性选择?
这四个方面,总归是为了多任务,提取不同表征。
特征淘汰机制
背景: 每个ID 单独映射一个 embedding 会使得机器内存很快炸掉。传统的 lru, lfu 只考虑了频率信息,主要是为了最大化缓存的命中率。
方案:全局共享的嵌入表 gset, 每个特征定制 feature score进行淘汰。
思想:针对低频 ID,为防止这些特征无意义的进入和淘汰,设置准入门槛!
改进:
- 新的存储器件, INTEL AEP。
- 实现底层的 kv引擎
短期行为序列模型
背景:用户的行为特征丰富且多变。
常见解决方案:
- 对于用户历史的行为进行 weighted sum
快手 baseline 是所有用户行为简单的做 sum pooling。在单列场景下,show 是被动接受的,用户需要观看一段时间之后再做反馈。
- 通过 RNN 之类的模型,进行时序建模
- 改进!借鉴 transformer (encoder + decoder)