sort命令用于对文本文件的内容,以行为单位进行排序
参数说明:
-b 忽略每行前面开始出的空格字符。
-c 检查文件是否已经按照顺序排序,如未排序则会输出诊断信息,提示从哪一行开始乱序。
-d 排序时处理英文字母、数字及空格字符外,忽略其他的字符。
-f 排序时将小写字母视为大写字母。
-i 排序时除了040~176之间的ASCII字符外,忽略其他的字符。
-m 将几个排序好的文件进行合并。
-n 依照数值的大小排序,除了能识别负号”-“,其他非数字字符均无法识别。
-u对输出的结果进行去重(unique)。
-r 以相反的顺序来排序。
-t<delimiter> 指定排序时所用的栏位分隔字符。
-k 通过key值进行排序,key必须给出位置和类型。
使用示例:
cat /etc/passwd | sort -t ':' -k3 –n # 以”:”为分隔符,第3个域值进行排序,并且按照数值大小进行排序。
sort test.txt –u –r # 将test.txt的内容以相反的顺序进行排序,并去重。
uniq命令用于检查文本文件中重复出现的行,一般与sort命令结合使用
参数说明:
-c 在每列旁边显示该行重复出现的次数。
-d 仅显示重复出现的行列。
-u 仅显示出一次的行列。
cat test.txt | uniq –c # 去重并显示重复行的次数
uniq –c test.txt # 去重并显示重复行的次数
当重复的行不相邻时,uniq并不能完全去重:
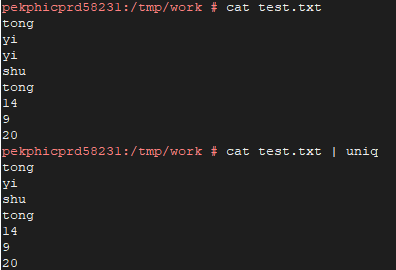
这时需要结合sort命令才能去重:
uniq –c test.txt # 去重并显示重复行的次数