特别说明:
对于算法,重在理解其思想、解决问题的方法,思路。因此,以下内容全都假定待排序序列的存储结构为:顺序存储结构。
完全二叉树概要
完全二叉树的定义,不知道者请自行查阅相关书籍。由完全二叉树的性质可知,树的高度也就 ,即:从根节点到达任何叶子节点的时间复杂度最多也就
,完全二叉树的存储结构有多种形式,其中一种便是顺序存储结构,参考图示如下:
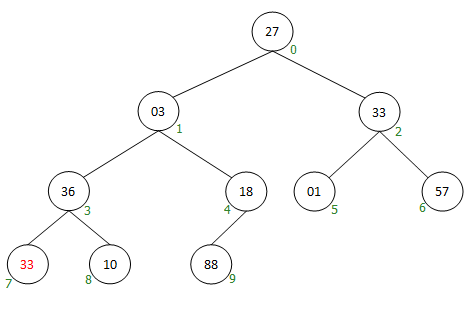
假设有如上一棵完全二叉树,则其对应的顺序存储结构为:

注意:上面顺序存储结构的下标是从 0 开始的,之所以这么约定也是方便下文堆排序的介绍!
对上面图示的说明:
01.上图中树的每个节点底下都有绿色的编号脚标。如上图树根节点编号为 0;
02.对应的顺序存储结构的索引下标起始值也是从0开始;
03.根据完全二叉树的性质可知:任何节点(假设编号为 )的左子节点(如果有的话)的编号(其实也是顺序存储结构的下标)值为:
左子节点编号 =
04.根据完全二叉树的性质可知:任何节点(假设编号为 )的右子节点(如果有的话)的编号(其实也是顺序存储结构的下标)值为:
右子节点编号 =
05.根据完全二叉树性质可知:任何节点(假设编号为 )的父节点(如果有的话)的编号为(其实也是顺序存储结构的下标)值为:
父节点编号 =
06.一棵 个节点的完全二叉树,其叶子节点个数为
,非叶子节点个数为
( 其实就是
) 个
堆概要
堆性质(堆定义)
堆,是一树完全二叉树,但其还满足性质:堆中的任何节点,其(关键字)值必不大于(或不小于)它的任何子节点的(关键字)值。因此,在堆中,最小(或最大)节点必在堆顶节点,即:从一个堆中取最小(或最大)元素的操作时间复杂度为 。但如果堆顶元素被取走后,为维持堆的性质,就必需要对堆进行重新调整,此时可将最后一个叶子节点取出来替补堆顶,并从此时的堆顶向下下溯。因此,取堆顶元素需要的时间复杂度主要耗在堆顶的下溯操作上。由完全二叉树的性质可知,该操作耗时最多为
。如果将 n 个元素构成的堆的堆顶元素全取走,则最多耗时
。
堆分类
堆分为大根堆与小根堆。当堆中任何节点都不大于其任何子节点时,此种堆为小根堆;当堆中任何节点都不小于其任何子节点时,此种堆为大根堆。
堆下溯
特别说明:此处以建大根来说明堆的下溯操作。
设当前待执行下溯操作的节点为 currNode,且其直接的左、右子节点分别为 LChild、RChild,则该节点的下溯操作:
01.如果 currNode 为叶子节点,或 currNode 的关键字比 LChild、RChild 的关键字都大,则下溯操作完成;
02.取出 LChild、RChild 中关键字较大者;
03.将前一步取出的拥有较大关键字的那个节点与 currNode 节点的数据交换。然后回到 01 点重复执行这些步骤;
由堆的下溯操作可看出,下溯操作目的是为了保持堆的性质。(如果有不理解的同学,可参照上面的那棵完全二叉树自行推演一遍)
堆构建
对于一个顺序存储的序列,如何将其构建成一个二叉堆呢?由前文介绍可知,对堆中的任何节点执行下溯操作即可保持该节点的堆的性质。因此,如果对所有节点都执行一遍下溯操作,则整个序列对应的二叉堆即构建完成。
设总共节点个数为 ,则构建大根堆(此处就以大根堆构建为例)过程如下:
01.设置当前正在处理的节点编号 =
;
02.对编号为 的节点执行下溯操作;
03.如果 = 0,则退出,堆构建完成;否则重新设置
=
- 1,重新执行 02 步骤;
以上便是堆构建过程。这边有同学可能会疑问为什么初始时处理的节点编号是 =
?而不是
=
?因为前文在介绍完全二叉树性质时已经说过,对于一棵完全二叉树,其非叶子节点个数为
,因此,编号最大的非叶子节点编号即为
。而对于所有叶子节点来说,因为它们没有任何子节点,所以它们自己本身就可认为是一个“完整的堆”,所以没必要对它们执行下溯操作,它们即可保持堆的性质。所以刚开始时,当前处理节点可直接设置为
=
。
至此,我们分析一下堆的构建的时间复杂度。由堆构建过程可知,整个构建过程中,时间几乎全耗在了节点的下溯操作上。由于堆的根节点是深度最深的,下溯操作也是最为耗时的,因此,粗略上统计,似乎建堆的时间复杂为应当为 。但经过仔细分析,其实根本用不了这么多时间。因为根节点毕竟只有一个,随着深度层次的加深,越来越多的节点的深度都小于
。
所以建的时间复杂度应当分别对每个节点进行统计,如下:
设堆的最大层数(即:堆(树)的深度)为 (注意:其实
=
), 对于第
层(注意:其实
编号为
=
的节点所在的层数)的节点
,首先将其与左、右子节点比较,找出最大节点,如果最大节点不是节点
,则将节点
与 该最大节点交换,然后再进行递归类似处理。而这一过程最多只会执行
-
层,每层进行两次比较,总共最多进行
次比较。而第
层的节点数为
,因此,处理第
层的节点最多需要进行
=
次比较。
所以整个建堆过程所需要的时间比较总次数为:
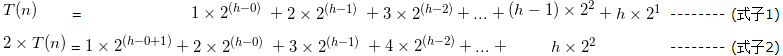
将上面 式子2 减去 式子1,得到建时间复杂度为:
进一步整理得
因为 =
,所以
,代入上式得
,因此建堆时间复杂度为
。
堆排序思想
01.构建堆。即将待排序序列 重新构建成一个二叉堆(提示:按需要,可构建大根堆或小根堆),具体建堆细节可参阅前文介绍;
02.取走堆顶,并重新调整堆结构以保持堆性质。调整后的堆暂且称之为新堆;
说明:其实该步骤可以按如下顺序完成即可
a) 直接将堆顶元素与此时堆的最后一个叶子节点元素互换位置;
b) 由于互换位置后,堆顶元素不能保证堆的性质,于是对新生成的堆(即:互换位置后的堆)的堆顶元素执行一次下溯操作即可保证堆的性质;
c) 由于取走堆顶元素后,新堆的元素个数就减少 1;
03.如果新堆为空,则排序完成;否则回到 02 步骤执行直到新堆为空为止;
堆排序分析
由前文介绍,其实堆排序并不算复杂,就只需要两步即可:建堆 -> 重复执行:取堆顶元素,然后下溯调整以重新保证堆性质,直到所有节点都处理完即可。因此,堆排序的时间复杂度主要是有两部分组成:建堆耗时 + 取堆顶并下溯操作上。建堆耗时前文已详细分析过,其时间复杂度为 。取堆顶元素只有常量耗时,其时间复杂度为
。下溯操作时间复杂度为
,如果要完成整个排序过程,则至少需要执行
次下溯操作,因此,总的下溯操作的时间复杂度为
。注意:在下溯操作过程中,由于每次堆的元素个数都减少 1,于是下溯操作的耗时其实也是会越来越少的。
综上所述,堆排序的时间复杂度为:建堆 + (n - 1) 次的取堆顶元素时间 + (n - 1) 次的下溯操作时间 = +
+
,所以堆排序(最坏情况下)的时间复杂度为:
。
由前文介绍可知,堆排序只需要一个额外辅助空间即可。因此,空间复杂度为 。
堆排序是不稳定排序算法,是属于选择类型的排序算法。堆排序算法效率还是很高的,像在 STL 的 Introsort 算法就用到了堆排序,再如像 A* 算法中,也多采纳应用堆排,等等。
堆排序算法编码实现
根据堆排序思想,堆排序算法编码参考如下:


1 // 2 // summary : 以 nParentIdx 为父节点的索引,取得该父节点及其两个(也有可能只有一个或零个)子节点中,关键字最小/大的那个节点的索引. 3 // in param : seqlist 序列列表 4 // in param : nLen 序列长度 5 // in param : nParentIdx 父节点索引.值范围 [0, nLen) 6 // out param : nMinIdx 存储关键最小/大的那个节点的索引值.值范围 [0, nLen) 7 // return : -- 8 // !!!note : 01.以下实现均假设一切输入数据都合法.即:内部不对参数全法性进行校验,默认它们全都合法有效. 9 void getMinIndex(int seqlist[/*nLen*/], const int nLen, const int nParentIdx, int& nMinIdx) { 10 nMinIdx = nParentIdx; 11 auto nChildIdx = nParentIdx << 1; 12 if (++nChildIdx >= nLen) { 13 return; 14 } else if (seqlist[nChildIdx] < seqlist[nMinIdx]) { 15 nMinIdx = nChildIdx; 16 } 17 if (++nChildIdx >= nLen) { 18 return; 19 } else if (nChildIdx < nLen && seqlist[nChildIdx] < seqlist[nMinIdx]) { 20 nMinIdx = nChildIdx; 21 } 22 } 23 24 void getMaxIndex(int seqlist[/*nLen*/], const int nLen, const int nParentIdx, int& nMaxIdx) { 25 nMaxIdx = nParentIdx; 26 auto nChildIdx = nParentIdx << 1; 27 if (++nChildIdx >= nLen) { 28 return; 29 } else if (seqlist[nChildIdx] > seqlist[nMaxIdx]) { 30 nMaxIdx = nChildIdx; 31 } 32 if (++nChildIdx >= nLen) { 33 return; 34 } else if (seqlist[nChildIdx] > seqlist[nMaxIdx]) { 35 nMaxIdx = nChildIdx; 36 } 37 } 38 39 // 40 // summary : 交换两个元素. 41 // in param : seqlist 序列列表 42 // in param : nIndexA 节点A索引.值范围 [0, nLen) 43 // in param : nIndexB 节点A索引.值范围 [0, nLen) 44 // return : -- 45 // !!!note : 01.以下实现均假设一切输入数据都合法.即:内部不对参数全法性进行校验,默认它们全都合法有效. 46 void swapTwoItems(int seqlist[/*nLen*/], const int nIndexA, const int nIndexB) { 47 const auto nTemp = seqlist[nIndexA]; 48 seqlist[nIndexA] = seqlist[nIndexB]; 49 seqlist[nIndexB] = nTemp; 50 } 51 52 // 53 // summary : 上溯. 54 // in param : seqlist 待排序列表.同时也是排完序列表. 55 // in param : nLen 列表长度 56 // out param : -- 57 // return : -- 58 // !!!note : 01.以下实现均假设一切输入数据都合法.即:内部不对参数全法性进行校验,默认它们全都合法有效. 59 // 02.其实上溯操作在此暂时是不需要的,但在某些应用中,却是很必要的.只要理解堆排序思想,则上溯 60 // 操作的实现将是容易的.(具体可参考如下编码). 61 // void upAdjustment(int seqlist[/*nLen*/], const int nLen, const int nIndex) { 62 // auto nCurrIdx = nIndex; 63 // auto nParentIdx = 0; 64 // auto nMinIndex = 0; 65 // while (nCurrIdx > 0) { 66 // nParentIdx = (nCurrIdx - 1) >> 1; 67 // //getMinIndex(seqlist, nLen, nParentIdx, nMinIndex); 68 // getMaxIndex(seqlist, nLen, nParentIdx, nMinIndex); 69 // if (nMinIndex == nParentIdx) { 70 // break; 71 // } 72 // swapTwoItems(seqlist, nParentIdx, nMinIndex); 73 // nCurrIdx = nParentIdx; 74 // } 75 // } 76 77 // 78 // summary : 下溯. 79 // in param : seqlist 待排序列表.同时也是排完序列表. 80 // in param : nLen 列表长度 81 // out param : -- 82 // return : -- 83 // !!!note : 01.以下实现均假设一切输入数据都合法.即:内部不对参数全法性进行校验,默认它们全都合法有效. 84 void downAdjustment(int seqlist[/*nLen*/], const int nLen, const int nIndex) { 85 if (nLen <= 1) { 86 return; 87 } 88 const auto nHalfIndex = nLen >> 1; 89 auto nCurrIdx = nIndex; 90 auto nMinIndex = 0; 91 while (nCurrIdx < nHalfIndex) { 92 //getMinIndex(seqlist, nLen, nCurrIdx, nMinIndex); 93 getMaxIndex(seqlist, nLen, nCurrIdx, nMinIndex); 94 if (nMinIndex == nCurrIdx) { 95 break; 96 } 97 swapTwoItems(seqlist, nCurrIdx, nMinIndex); 98 nCurrIdx = nMinIndex; 99 } 100 } 101 102 // 103 // summary : 建堆. 104 // in param : seqlist 待排序列表.同时也是排完序列表. 105 // in param : nLen 列表长度 106 // out param : -- 107 // return : -- 108 // !!!note : 01.以下实现均假设一切输入数据都合法.即:内部不对参数全法性进行校验,默认它们全都合法有效. 109 // 02.建堆思路:从seqlist序列的一半位置处一直往前走,对每个元素执行下溯操作,直到走到第一个元素为止. 110 void make_heap(int seqlist[/*nLen*/], const int nLen) { 111 if (nLen <= 1) { 112 return; 113 } 114 auto nMinIndex = 0; 115 for (auto nCurrIdx = (nLen >> 1); nCurrIdx >= 0; --nCurrIdx) { 116 downAdjustment(seqlist, nLen, nCurrIdx); 117 } 118 } 119 120 // 121 // summary : 弹堆顶元素 122 // in param : seqlist 待排序列表.同时也是排完序列表. 123 // in param : nLen 列表长度 124 // out param : -- 125 // return : -- 126 // !!!note : 01.以下实现均假设一切输入数据都合法.即:内部不对参数全法性进行校验,默认它们全都合法有效. 127 void heap_pop(int seqlist[/*nLen*/], const int nLen) { 128 if (nLen <= 1) { 129 return; 130 } 131 swapTwoItems(seqlist, 0, nLen - 1); 132 downAdjustment(seqlist, nLen - 1, 0); 133 } 134 135 // 136 // summary : 堆排序. 137 // in param : seqlist 待排序列表.同时也是排完序列表. 138 // in param : nLen 列表长度 139 // out param : -- 140 // return : -- 141 // !!!note : 01.以下实现均假设一切输入数据都合法.即:内部不对参数全法性进行校验,默认它们全都合法有效. 142 // 02.排序开始前 seqlist 是无序的,排序结束后 seqlist 是有序的. 143 void heap_sort(int seqlist[/*nLen*/], const int nLen) { 144 make_heap(seqlist, nLen); 145 auto nSeqLength = nLen; 146 while (nSeqLength > 1) { 147 heap_pop(seqlist, nSeqLength); 148 --nSeqLength; 149 } 150 }
测试用例参考:
1 { // 堆排序 2 const int nLen = 10; 3 int seqlist[nLen] = { 27, 3, 33, 36, 18, 1, 57, 33, 10, 88 }; 4 print(seqlist, nLen); 5 heap_sort(seqlist, nLen); 6 print(seqlist, nLen); 7 printf("------------------------------------------------------------------------ "); 8 }