Spark作业调度
对RDD的操作分为transformation和action两类,真正的作业提交运行发生在action之后,调用action之后会将对原始输入数据的所有transformation操作封装成作业并向集群提交运行。这个过程大致可以如下描述:
- 由DAGScheduler对RDD之间的依赖性进行分析,通过DAG来分析各个RDD之间的转换依赖关系
- 根据DAGScheduler分析得到的RDD依赖关系将Job划分成多个stage
- 每个stage会生成一个TaskSet并提交给TaskScheduler,调度权转交给TaskScheduler,由它来负责分发task到worker执行
接下来,理解 Spark 中RDD的依赖关系.
RDD依赖关系
Spark中RDD的粗粒度操作,每一次transformation都会生成一个新的RDD,这样就会建立RDD之间的前后依赖关系,在Spark中,依赖关系被定义为两种类型,分别是窄依赖和宽依赖
- 窄依赖,父RDD的分区最多只会被子RDD的一个分区使用,
- 宽依赖,父RDD的一个分区会被子RDD的多个分区使用(宽依赖指子RDD的每个分区都要依赖于父RDD的所有分区,这是shuffle类操作)
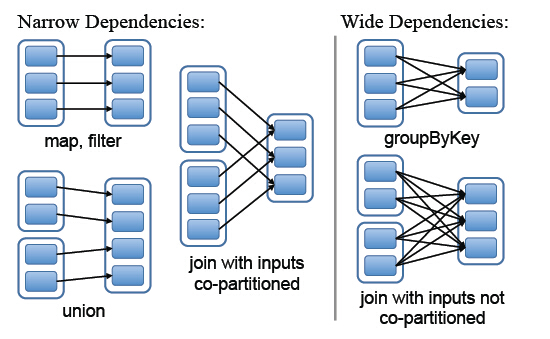
图中左边都是窄依赖关系,可以看出分区是1对1的。右边为宽依赖关系,有分区是1对多。(map,filter,union属于第一类窄依赖)
stage的划分
stage的划分是Spark作业调度的关键一步,它基于DAG确定依赖关系,借此来划分stage,将依赖链断开,每个stage内部可以并行运行,整个作业按照stage顺序依次执行,最终完成整个Job。实际应用提交的Job中RDD依赖关系是十分复杂的,依据这些依赖关系来划分stage自然是十分困难的,Spark此时就利用了前文提到的依赖关系,调度器从DAG图末端出发,逆向遍历整个依赖关系链,遇到ShuffleDependency(宽依赖关系的一种叫法)就断开,遇到NarrowDependency就将其加入到当前stage。stage中task数目由stage末端的RDD分区个数来决定,RDD转换是基于分区的一种粗粒度计算,一个stage执行的结果就是这几个分区构成的RDD。
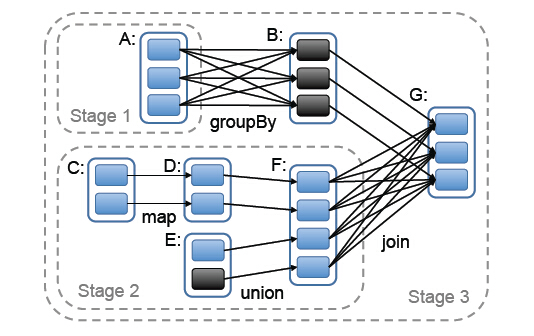
图中可以看出,在宽依赖关系处就会断开依赖链,划分stage,这里的stage1不需要计算,只需要计算stage2和stage3,就可以完成整个Job。
总结:遇到一个宽依赖就分一个stage
参考博客:https://blog.csdn.net/mahuacai/article/details/51919615