1. HBase安装部署操作
a) 解压HBase安装包
tar –zxvf hbase-0.98.0-hadoop2-bin.tar.gz
b) 修改环境变量 hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_71/
c) 修改配置文件 hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration>
<property> <name>hbase.cluster.distributed</name>
<value>true</value> </property>
<property> <name>hbase.rootdir</name> <value>hdfs://master:9000/hbase</value>
</property> <property>
<name>hbase.zookeeper.quorum</name>
<value>master</value> </property>
</configuration>
d) regionservers
将文件中的localhost改为slave
e) 设置环境变量
vi .bash_profile
export HBASE_HOME=hbase的安装路径
export HADOOP_CLASSPATH=$HBASE_HOME/lib/*
f) 复制HBase安装文件到slave节点
g) 验证启动 start-hbase.sh
http://master:60010 访问HBase集群
jps 查看进程
1. 查询HBase版本信息
hbase > version

2. 查询服务器状态信息
hbase> status

3. 列出所有表
list --类似于show tables;

4. 创建一张表table1(包含两个列族)
create ‘table1’, ‘columnsfamily1’, ‘columnsfamily2’
5. 查看表的描述信息
describe ‘table1’

6. 修改表的模式,删除列族columnsfamily1
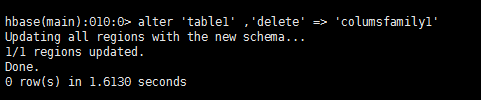
alter ‘table1’ , ‘delete’ => ‘columnsfamily1’
注意:修改表模式之前请将表disable
disable ‘table1’
7. 删除一张表
disable ‘table1’
drop ‘table1’
8. 查询表的状态
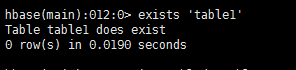
exists ‘table1’
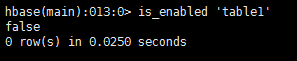
is_enabled ‘table1’
is_disabled ‘table1

9. 插入若干行数据(创建一张学生表,包含两个列族)
put ‘student’, ‘95001’, ‘cf1:name’, ‘xiaoming’
put ‘student’, ‘95001’, ‘cf1:gender’, ‘male’
put ‘student’, ‘95001’, ‘cf2:address’, ‘zhanjiang’
put ‘student’, ‘95002’, ‘cf1:name’, ‘wangli’
put ‘student’, ‘95002’, ‘cf2:address’, ‘guangzhou’
10.获取数据
get ‘student’ , ‘95002’
get ‘student’, ‘95002’, ‘cf1’

get ‘student’, ‘95001’, ‘cf1:name’

11. 更新数据
put ‘student’, ‘95001’, ‘cf2:address’ , ‘maoming’
可通过时间戳查看修改前的数据(两条都还在)

get ‘student’,’95001’, {COLUMN =>’cf1:address’, TIMESTAMP =>29837173123}

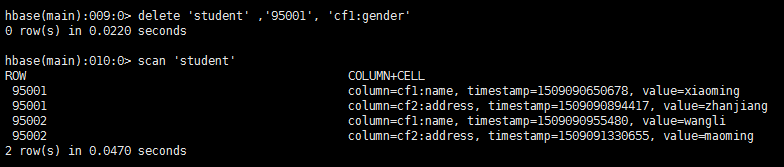
12. 全表扫描
scan ‘student’

13.删除95001的性别字段值
delete ‘student’ ,’95001’, ‘cf1:gender’
14. 删除整行
deleteall ‘student’,’95002’

15. 查询表中的行数
count ‘student’

16. 清空表
truncate ‘student’

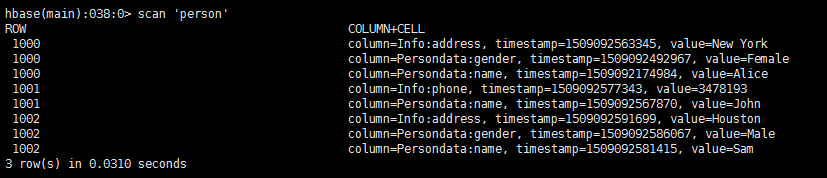
2. 使用Hbase shell完成下列表格的创建和值的输入(要求能查看最近三个版本的数据);
Row Key Persondata Info
name gender address phone
1000 Alice female T3: New York
T2: Boston
T1: Los Angels
1001 John T2:3478193
T1:3749274
1002 Sam Male Houston
Shell脚本如下:
create 'person', 'Persondata','Info'
put 'person','1000', 'Persondata:name','Alice'
put 'person','1000', 'Persondata:gender','Female'
put 'person','1000', 'Info:address','Los Angels'
put 'person','1000', 'Info:address','Boston'
put 'person','1000', 'Info:address','New York'
put 'person','1001', 'Persondata:name','John'
put 'person','1001', 'Info:phone','3749274'
put 'person','1001', 'Info:phone','3478193'
put 'person','1002', 'Persondata:name','Sam'
put 'person','1002', 'Persondata:gender','Male'
put 'person','1002', 'Info:address','Houston'
输出结果:
3. Spark的安装
1)解压安装包
tar –zxvf spark-1.5.2-bin-2.5.2.tar.gz
2)配置环境变量
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
3)验证Spark安装
./spark-submit –class org.apache.spark.examples.SparkPi
--master yarn-cluster
--num-executors 3
--driver-memory 1g
--executor-memory 1g
--executor-cores 1
spark-examples-1.5.2-hadoop2.5.2.jar 10
4)查看3)的应用运行结果
5)使用scala shell完成下述操作
scala>val test= sc.textFile(“hdfs://node1:9000/input/ Shakespeare.txt”)
//读取hdfs上的文件,将其创建为一个名为test的RDD
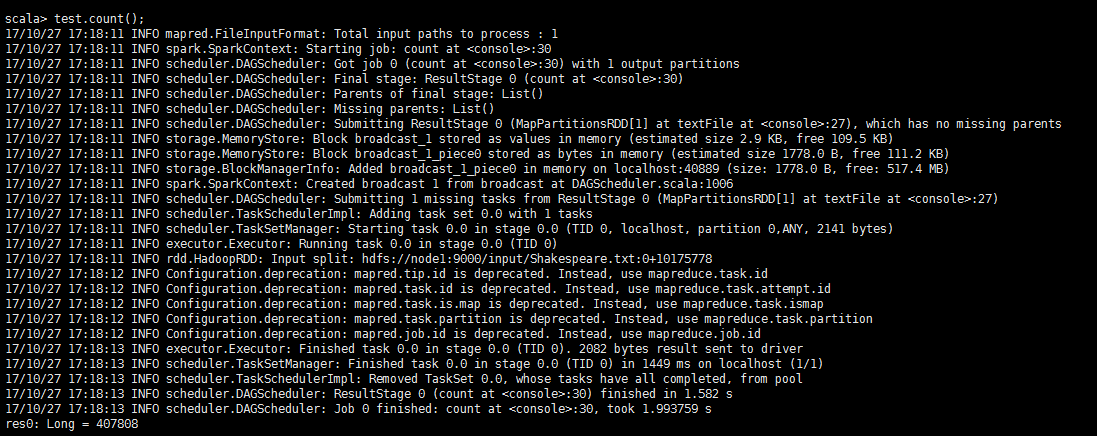
scala>test.count()
//输出test的行数
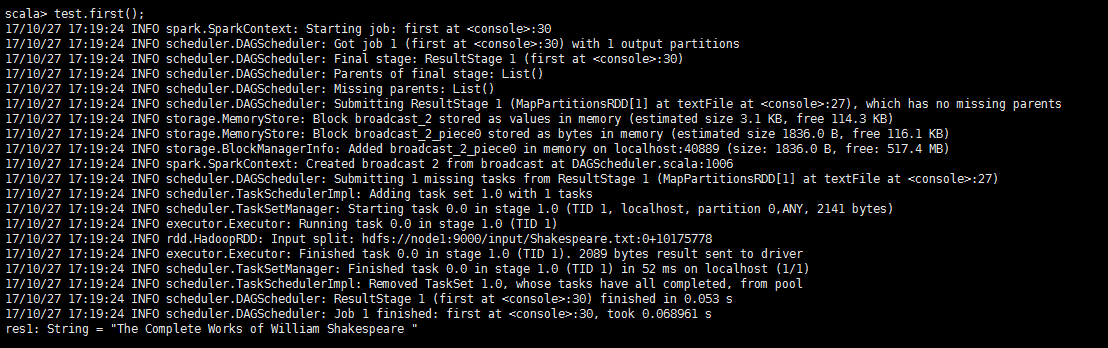
scala>test.first()
6)使用Spark完成上述文件中wordcount统计;
val test= sc.textFile("hdfs://node1:9000/input/Shakespeare.txt)
val wordCount = test.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
scala> wordCount.collect()
wordCount.collect()
相关资料:
链接:http://pan.baidu.com/s/1dFD7mdr 密码:xwu8