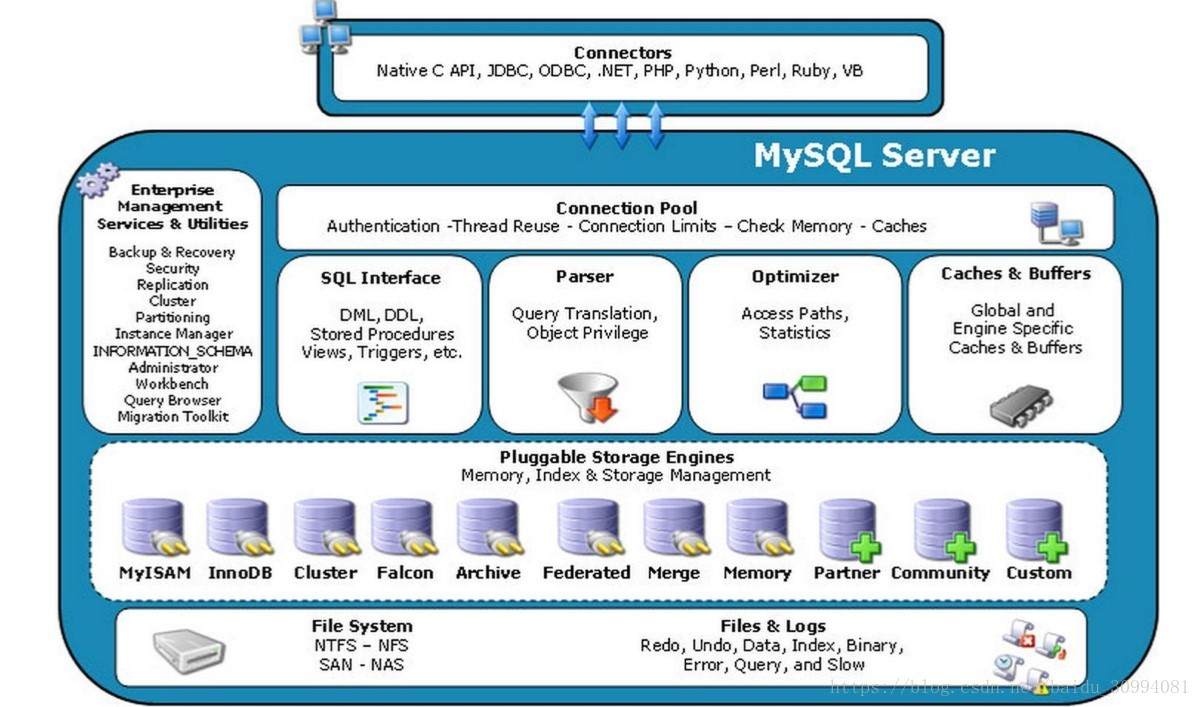
一:体系结构
mysql服务和客户端的通信是半双工的
(1) Connectors:不同语言中与SQL的交互
(2)Management Serveices & Utilities: 系统管理和控制工具,例如备份恢复、Mysql复制、集群等
(3)Connection Pool: 连接池(管理缓冲用户连接、用户名、密码、权限校验、线程处理等需要缓存的需求)
(4)SQL Interface: SQL接口:接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface
(5)Parser: 解析器,SQL命令传递到解析器的时候会被解析器验证和解析。
(6)Optimizer: 查询优化器,SQL语句在查询之前会使用查询优化器对查询进行优化。
(7) Cache和Buffer(高速缓存区): 查询缓存,如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。 通过LRU算法将数据的冷端溢出,未来得及时刷新到磁盘的数据页,叫脏页。
(8)Engine :存储引擎。存储引擎是MySql中具体的与文件打交道的子系统。Mysql的存储引擎是插拔式的。它根据MySql公司提供的文件访问层的一个抽象接口来定制一种文件访问机制(这种访问机制就叫存储引擎) 。
2.sql的执行顺序
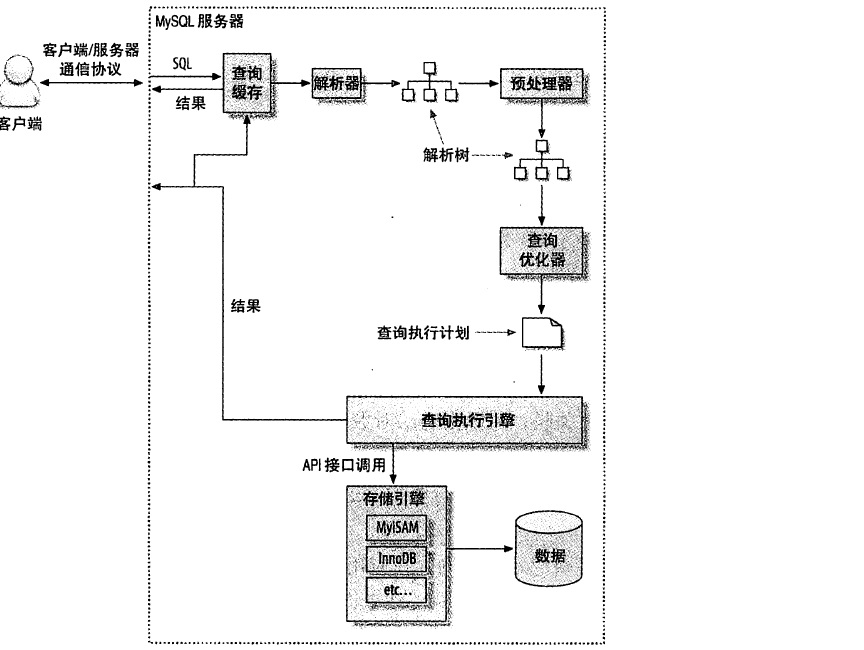
1、客户端发送一条查询给服务器
2、服务器先检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果。
3、服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划。
4、MySQL根据优化器生成的执行计划,调用存储引擎的API执行查询。
5、返回结果给客户端