一、Linux基础知识
1.内核基本架构
图1 GNU/Linux 操作系统的基本体系结构

最上面是用户(或应用程序)空间。这是用户应用程序执行的地方。用户空间之下是内核空间,Linux 内核正是位于这里。
GNU C Library (glibc)也在这里。它提供了连接内核的系统调用接口,还提供了在用户空间应用程序和内核之间进行转换的机制。这点非常重要,因为内核和用户空间的应用程序使用的是不同的保护地址空间。每个用户空间的进程都使用自己的虚拟地址空间,而内核则占用单独的地址空间。
Linux 内核可以进一步划分成 3 层。最上面是系统调用接口,它实现了一些基本的功能,例如 read 和 write。系统调用接口之下是内核代码,可以更精确地定义为独立于体系结构的内核代码。这些代码是 Linux 所支持的所有处理器体系结构所通用的。在这些代码之下是依赖于体系结构的代码,构成了通常称为 BSP(Board Support Package)的部分。这些代码用作给定体系结构的处理器和特定于平台的代码。
2.Linux 内核的属性
在讨论大型而复杂的系统的体系结构时,可以从很多角度来审视系统。体系结构分析的一个目标是提供一种方法更好地理解源代码,这正是本文的目的。
Linux 内核实现了很多重要的体系结构属性。在或高或低的层次上,内核被划分为多个子系统。Linux 也可以看作是一个整体,因为它会将所有这些基本服务都集成到内核中。这与微内核的体系结构不同,后者会提供一些基本的服务,例如通信、I/O、内存和进程管理,更具体的服务都是插入到微内核层中的。每种内核都有自己的优点,不过这里并不对此进行讨论。
随着时间的流逝,Linux 内核在内存和 CPU 使用方面具有较高的效率,并且非常稳定。但是对于 Linux 来说,最为有趣的是在这种大小和复杂性的前提下,依然具有良好的可移植性。Linux 编译后可在大量处理器和具有不同体系结构约束和需求的平台上运行。一个例子是 Linux 可以在一个具有内存管理单元(MMU)的处理器上运行,也可以在那些不提供 MMU 的处理器上运行。Linux 内核的 uClinux 移植提供了对非 MMU 的支持。
3.Linux 内核的主要子系统
现在使用图 2 中的分类说明 Linux 内核的主要组件。
图 2. Linux 内核的一个体系结构透视图

3.1系统调用接口
SCI 层提供了某些机制执行从用户空间到内核的函数调用。正如前面讨论的一样,这个接口依赖于体系结构,甚至在相同的处理器家族内也是如此。SCI 实际上是一个非常有用的函数调用多路复用和多路分解服务。在 ./linux/kernel 中您可以找到 SCI 的实现,并在 ./linux/arch 中找到依赖于体系结构的部分。
3.2进程管理
进程管理的重点是进程的执行。在内核中,这些进程称为线程,代表了单独的处理器虚拟化(线程代码、数据、堆栈和 CPU 寄存器)。在用户空间,通常使用进程这个术语,不过 Linux 实现并没有区分这两个概念(进程和线程)。内核通过 SCI 提供了一个应用程序编程接口(API)来创建一个新进程(fork、exec 或 Portable Operating System Interface [POSIX] 函数),停止进程(kill、exit),并在它们之间进行通信和同步(signal 或者 POSIX 机制)。
进程管理还包括处理活动进程之间共享 CPU 的需求。内核实现了一种新型的调度算法,不管有多少个线程在竞争 CPU,这种算法都可以在固定时间内进行操作。这种算法就称为 O(1) 调度程序,这个名字就表示它调度多个线程所使用的时间和调度一个线程所使用的时间是相同的。 O(1) 调度程序也可以支持多处理器(称为对称多处理器或 SMP)。您可以在 ./linux/kernel 中找到进程管理的源代码,在 ./linux/arch 中可以找到依赖于体系结构的源代码。
3.3内存管理
内核所管理的另外一个重要资源是内存。为了提高效率,如果由硬件管理虚拟内存,内存是按照所谓的内存页 方式进行管理的(对于大部分体系结构来说都是 4KB)。Linux 包括了管理可用内存的方式,以及物理和虚拟映射所使用的硬件机制。
不过内存管理要管理的可不止 4KB 缓冲区。Linux 提供了对 4KB 缓冲区的抽象,例如 slab 分配器。这种内存管理模式使用 4KB 缓冲区为基数,然后从中分配结构,并跟踪内存页使用情况,比如哪些内存页是满的,哪些页面没有完全使用,哪些页面为空。这样就允许该模式根据系统需要来动态调整内存使用。
为了支持多个用户使用内存,有时会出现可用内存被消耗光的情况。由于这个原因,页面可以移出内存并放入磁盘中。这个过程称为交换,因为页面会被从内存交换到硬盘上。内存管理的源代码可以在 ./linux/mm 中找到。
3.4虚拟文件系统
虚拟文件系统(VFS)是 Linux 内核中非常有用的一个方面,因为它为文件系统提供了一个通用的接口抽象。VFS 在 SCI 和内核所支持的文件系统之间提供了一个交换层(请参看图 3)。
图 3. VFS 在用户和文件系统之间提供了一个交换层

在 VFS 上面,是对诸如 open、close、read 和 write 之类的函数的一个通用 API 抽象。在 VFS 下面是文件系统抽象,它定义了上层函数的实现方式。它们是给定文件系统(超过 50 个)的插件。文件系统的源代码可以在 ./linux/fs 中找到。
文件系统层之下是缓冲区缓存,它为文件系统层提供了一个通用函数集(与具体文件系统无关)。这个缓存层通过将数据保留一段时间(或者随即预先读取数据以便在需要是就可用)优化了对物理设备的访问。缓冲区缓存之下是设备驱动程序,它实现了特定物理设备的接口。
3.5网络堆栈
网络堆栈在设计上遵循模拟协议本身的分层体系结构。回想一下,Internet Protocol (IP) 是传输协议(通常称为传输控制协议或 TCP)下面的核心网络层协议。TCP 上面是 socket 层,它是通过 SCI 进行调用的。
socket 层是网络子系统的标准 API,它为各种网络协议提供了一个用户接口。从原始帧访问到 IP 协议数据单元(PDU),再到 TCP 和 User Datagram Protocol (UDP),socket 层提供了一种标准化的方法来管理连接,并在各个终点之间移动数据。内核中网络源代码可以在 ./linux/net 中找到。
3.6设备驱动程序
Linux 内核中有大量代码都在设备驱动程序中,它们能够运转特定的硬件设备。Linux 源码树提供了一个驱动程序子目录,这个目录又进一步划分为各种支持设备,例如 Bluetooth、I2C、serial 等。设备驱动程序的代码可以在 ./linux/drivers 中找到。
3.7依赖体系结构的代码
尽管 Linux 很大程度上独立于所运行的体系结构,但是有些元素则必须考虑体系结构才能正常操作并实现更高效率。./linux/arch 子目录定义了内核源代码中依赖于体系结构的部分,其中包含了各种特定于体系结构的子目录(共同组成了 BSP)。对于一个典型的桌面系统来说,使用的是 i386 目录。每个体系结构子目录都包含了很多其他子目录,每个子目录都关注内核中的一个特定方面,例如引导、内核、内存管理等。这些依赖体系结构的代码可以在 ./linux/arch 中找到。
4.中断处理
中断根据不同角度可以分为外中断和内中断,也分为硬中断和软中断,是指由于接收到来自外围硬件(相对于中央处理器和内存)的异步信号或来自软件的同步信号,而进行相应的硬件/软件处理。硬件中断导致处理器切换上下文来保存当前进程的状态和切换到下一个进程的状态,主要包括CPU上的寄存器,、PC和PSW、页表等;软件中断当前执行指令引起,比如缺页中断,以可编程的方式直接指示这种上下文切换,并将处理导向一段中断处理代码。
4.1中断的作用
中断是多道程序实现的基础,可以让单个进程不能独占CPU,从而实现并发,提高系统资源利用率。
4.2中断分类
Linux把中断过程中的要执行的任务分为紧急、 非紧急、非紧急可延迟三类。在中断处理程序中只完成不可延迟的部分以达到快速响应的目的,并把可延迟的操作内容推迟到内核的下半部分执行,在一个更合适的时机调用函数完成这些可延迟的操作。Linux内核提供了软中断softirq、tasklet和工作队列work queue等方法进行实现。
softirq
软件中断(softIRQ)是内核提供的一种延迟执行机制,它完全由软件触发,虽然说是延迟机制,实际上,在大多数情况下,它与普通进程相比,能得到更快的响应时间。
tasklet
tasklet是IO驱动程序实现可延迟函数的首选,建立在HI_SOFTIRQ和TASKLET_SOFTURQ等软中断之上,tasklet和高优先级的tasklet分别存放在tasklet_vec和tasklet_hi_vec数组中,分别由tasklet_action和tasklet_hi_action处理。
work queue
work queue工作队列把工作推后,交给一个内核线程执行,工作队列允许被重新调度甚至睡眠。在Linux中的数据结构是workqueue_struct和cpu_workqueue_struct。
二、内核任务调度
1.调度器的概述
多任务操作系统分为非抢占式多任务和抢占式多任务。与大多数现代操作系统一样,Linux采用的是抢占式多任务模式。这表示对CPU的占用时间由操作系统决定的,具体为操作系统中的调度器。调度器决定了什么时候停止一个进程以便让其他进程有机会运行,同时挑选出一个其他的进程开始运行。
2.调度策略
在Linux上调度策略决定了调度器是如何选择一个新进程的时间。调度策略与进程的类型有关,内核现有的调度策略如下:
#define SCHED_NORMAL 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_BATCH 3
/* SCHED_ISO: reserved but not implemented yet */
#define SCHED_IDLE 5
0: 默认的调度策略,针对的是普通进程。
1:针对实时进程的先进先出调度。适合对时间性要求比较高但每次运行时间比较短的进程。
2:针对的是实时进程的时间片轮转调度。适合每次运行时间比较长得进程。
3:针对批处理进程的调度,适合那些非交互性且对cpu使用密集的进程。
SCHED_ISO:是内核的一个预留字段,目前还没有使用
5:适用于优先级较低的后台进程。
注:每个进程的调度策略保存在进程描述符task_struct中的policy字段
3.调度器中的机制
内核引入调度类(struct sched_class)说明了调度器应该具有哪些功能。内核中每种调度策略都有该调度类的一个实例。(比如:基于公平调度类为:fair_sched_class,基于实时进程的调度类实例为:rt_sched_class),该实例也是针对每种调度策略的具体实现。调度类封装了不同调度策略的具体实现,屏蔽了各种调度策略的细节实现。
调度器核心函数schedule()只需要调用调度类中的接口,完成进程的调度,完全不需要考虑调度策略的具体实现。调度类连接了调度函数和具体的调度策略。
- 调度类就是代表的各种调度策略,调度实体就是调度单位,这个实体通常是一个进程,但是自从引入了cgroup后,这个调度实体可能就不是一个进程了,而是一个组
4.schedule()函数
linux 支持两种类型的进程调度,实时进程和普通进程。实时进程采用SCHED_FIFO 和SCHED_RR调度策略,普通进程采用SCHED_NORMAL策略。
preempt_disable():禁止内核抢占
cpu_rq():获取当前cpu对应的就绪队列。
prev = rq->curr;获取当前进程的描述符prev
switch_count = &prev->nivcsw;获取当前进程的切换次数。
update_rq_clock() :更新就绪队列上的时钟
clear_tsk_need_resched()清楚当前进程prev的重新调度标志。
deactive_task():将当前进程从就绪队列中删除。
put_prev_task() :将当前进程重新放入就绪队列
pick_next_task():在就绪队列中挑选下一个将被执行的进程。
context_switch():进行prev和next两个进程的切换。具体的切换代码与体系架构有关,在switch_to()中通过一段汇编代码实现。
post_schedule():进行进程切换后的后期处理工作。
5.pick_next_task函数
选择下一个将要被执行的进程无疑是一个很重要的过程,我们来看一下内核中代码的实现
对以下这段代码说明:
当rq中的运行队列的个数(nr_running)和cfs中的nr_runing相等的时候,表示现在所有的都是普通进程,这时候就会调用cfs算法中的pick_next_task(其实是pick_next_task_fair函数),当不相等的时候,则调用sched_class_highest(这是一个宏,指向的是实时进程),这下面的这个for(;;)循环中,首先是会在实时进程中选取要调度的程序(p = class->pick_next_task(rq);)。如果没有选取到,会执行class=class->next;在class这个链表中有三种类型(fair,idle,rt)。也就是说会调用到下一个调度类。
static inline struct task_struct *
pick_next_task(struct rq *rq)
{
const struct sched_class *class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in
* the fair class we can call that function directly:
*/
//基于公平调度的普通进程
if (likely(rq->nr_running == rq->cfs.nr_running)) {
p = fair_sched_class.pick_next_task(rq);
if (likely(p))
return p;
}
//基于实时调度的实时进程
class = sched_class_highest;
for ( ; ; ) {
p = class->pick_next_task(rq); //实时进程的类
if (p)
return p;
/*
* Will never be NULL as the idle class always
* returns a non-NULL p:
*/
class = class->next; //rt->next = fair; fair->next = idle
}
}
在这段代码中体现了Linux所支持的两种类型的进程,实时进程和普通进程。回顾下:实时进程可以采用SCHED_FIFO 和SCHED_RR调度策略,普通进程采用SCHED_NORMAL调度策略。
在这里首先说明一个结构体struct rq,这个结构体是调度器管理可运行状态进程的最主要的数据结构。每个cpu上都有一个可运行的就绪队列。刚才pick_next_task函数中看到了在选择下一个将要被执行的进程时实际上用的是struct rq上的普通进程的调度或者实时进程的调度,那么具体是如何调度的呢?在实时调度中,为了实现O(1)的调度算法,内核为每个优先级维护一个运行队列和一个DECLARE_BITMAP,内核根据DECLARE_BITMAP的bit数值找出非空的最高级优先队列的编号,从而可以从非空的最高级优先队列中取出进程进行运行。
我们来看下内核的实现:
struct rt_prio_array {
DECLARE_BITMAP(bitmap, MAX_RT_PRIO+1); /* include 1 bit for delimiter */
struct list_head queue[MAX_RT_PRIO];
};
数组queue[i]里面存放的是优先级为i的进程队列的链表头。在结构体rt_prio_array 中有一个重要的数据构DECLARE_BITMAP,它在内核中的第一如下:
define DECLARE_BITMAP(name,bits)
unsigned long name[BITS_TO_LONGS(bits)]
5.1对于实时进程的O(1)算法
这个数据是用来作为进程队列queue[MAX_PRIO]的索引位图。bitmap中的每一位与queue[i]对应,当queue[i]的进程队列不为空时,Bitmap的相应位就为1,否则为0,这样就只需要通过汇编指令从进程优先级由高到低的方向找到第一个为1的位置,则这个位置就是就绪队列中最高的优先级(函数sched_find_first_bit()就是用来实现该目的的)。那么queue[index]->next就是要找的候选进程。
如果还是不懂,那就来看两个图
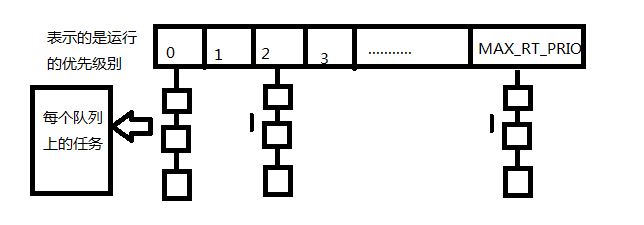
注:在每个队列上的任务一般基于先进先出的原则进行调度(并且为每个进程分配时间片)
在内核中的实现为:
static struct sched_rt_entity *pick_next_rt_entity(struct rq *rq,
struct rt_rq *rt_rq)
{
struct rt_prio_array *array = &rt_rq->active;
struct sched_rt_entity *next = NULL;
struct list_head *queue;
int idx;
idx = sched_find_first_bit(array->bitmap); //找到优先级最高的位
BUG_ON(idx >= MAX_RT_PRIO);
queue = array->queue + idx; //然后找到对应的queue的起始地址
next = list_entry(queue->next, struct sched_rt_entity, run_list); //按先进先出拿任务
return next;
}
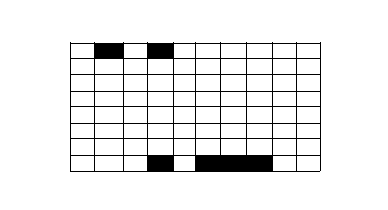
那么当同一优先级的任务比较多的时候,内核会根据
位图:
将对应的位置为1,每次取出最大的被置为1的位,表示优先级最高:
5.2 关于普通进程的CFS算法:
我们知道,普通进程在选取下一个需要被调度的进程时,是调用的pick_next_task_fair函数。在这个函数中是以调度实体为单位进行调度的。其最主要的函数是:pick_next_entity,在这个函数中会调用wakeup_preempt_entity函数,这个函数的主要作用是根据进程的虚拟时间以及权重的结算进程的粒度,以判断其是否需要抢占。看一下内核是怎么实现的:
wakeup_preempt_entity(struct sched_entity *curr, struct sched_entity *se)
{
s64 gran, vdiff = curr->vruntime - se->vruntime;//计算两个虚拟时间差
//如果se的虚拟时间比curr还大,说明本该curr执行,无需抢占
if (vdiff <= 0)
return -1;
gran = wakeup_gran(curr, se);
if (vdiff > gran)
return 1;
return 0;
}
gran为需要抢占的时间差,只有两个时间差大于需要抢占的时间差,才需要抢占,这里避免太频繁的抢占
wakeup_gran(struct sched_entity *curr, struct sched_entity *se)
{
unsigned long gran = sysctl_sched_wakeup_granularity;
if (cfs_rq_of(curr)->curr && sched_feat(ADAPTIVE_GRAN))
gran = adaptive_gran(curr, se);
/*
* Since its curr running now, convert the gran from real-time
* to virtual-time in his units.
*/
if (sched_feat(ASYM_GRAN)) {
/*
* By using 'se' instead of 'curr' we penalize light tasks, so
* they get preempted easier. That is, if 'se' < 'curr' then
* the resulting gran will be larger, therefore penalizing the
* lighter, if otoh 'se' > 'curr' then the resulting gran will
* be smaller, again penalizing the lighter task.
*
* This is especially important for buddies when the leftmost
* task is higher priority than the buddy.
*/
if (unlikely(se->load.weight != NICE_0_LOAD))
gran = calc_delta_fair(gran, se);
} else {
if (unlikely(curr->load.weight != NICE_0_LOAD))
gran = calc_delta_fair(gran, curr);
}
return gran;
}
6.调度中的nice值
首先需要明确的是:nice的值不是进程的优先级,他们不是一个概念,但是进程的Nice值会影响到进程的优先级的变化。

通过命令ps -el可以看到进程的nice值为NI列。PRI表示的是进程的优先级,其实进程的优先级只是一个整数,它是调度器选择进程运行的基础。
普通进程有:静态优先级和动态优先级。
静态优先级:之所有称为静态优先级是因为它不会随着时间而改变,内核不会修改它,只能通过系统调用nice去修改,静态优先级用进程描述符中的static_prio来表示。在内核中/kernel/sched.c中,nice和静态优先级的关系为:
#define NICE_TO_PRIO(nice) (MAX_RT_PRIO + (nice) + 20)
#define PRIO_TO_NICE(prio) ((prio) - MAX_RT_PRIO - 20)
动态优先级:调度程序通过增加或者减小进程静态优先级的值来奖励IO小的进程或者惩罚cpu消耗型的进程。调整后的优先级称为动态优先级。在进程描述中用prio来表示,通常所说的优先级指的是动态优先级。
由上面分析可知,我们可以通过系统调用nice函数来改变进程的优先级。
#include <stdlib.h>
#include <stdio.h>
#include <math.h>
#include <unistd.h>
#include <sys/time.h>
#define JMAX (400*100000)
#define GET_ELAPSED_TIME(tv1,tv2) (
(double)( (tv2.tv_sec - tv1.tv_sec)
+ .000001 * (tv2.tv_usec - tv1.tv_usec)))
//做一个延迟的计算
double do_something (void)
{
int j;
double x = 0.0;
struct timeval tv1, tv2;
gettimeofday (&tv1, NULL);//获取时区
for (j = 0; j < JMAX; j++)
x += 1.0 / (exp ((1 + x * x) / (2 + x * x)));
gettimeofday (&tv2, NULL);
return GET_ELAPSED_TIME (tv1, tv2);//求差值
}
int main (int argc, char *argv[])
{
int niceval = 0, nsched;
/* for kernels less than 2.6.21, this is HZ
for tickless kernels this must be the MHZ rate
e.g, for 2.6 GZ scale = 2600000000 */
long scale = 1000;
long ticks_cpu, ticks_sleep;
pid_t pid;
FILE *fp;
char fname[256];
double elapsed_time, timeslice, t_cpu, t_sleep;
if (argc > 1)
niceval = atoi (argv[1]);
pid = getpid ();
if (argc > 2)
scale = atoi (argv[2]);
/* give a chance for other tasks to queue up */
sleep (3);
sprintf (fname, "/proc/%d/schedstat", pid);//读取进程的调度状态
/*
在schedstat中的数字是什么意思呢?:
*/
/* printf ("Fname = %s
", fname); */
if (!(fp = fopen (fname, "r"))) {
printf ("Failed to open stat file
");
exit (-1);
}
//nice系统调用
if (nice (niceval) == -1 && niceval != -1) {
printf ("Failed to set nice to %d
", niceval);
exit (-1);
}
elapsed_time = do_something ();//for 循环执行了多长时间
fscanf (fp, "%ld %ld %d", &ticks_cpu, &ticks_sleep, &nsched);//nsched表示调度的次数
t_cpu = (float)ticks_cpu / scale;//震动的次数除以1000,就是时间
t_sleep = (float)ticks_sleep / scale;
timeslice = t_cpu / (double)nsched;//除以调度的次数,就是每次调度的时间(时间片)
printf ("
nice=%3d time=%8g secs pid=%5d"
" t_cpu=%8g t_sleep=%8g nsched=%5d"
" avg timeslice = %8g
",
niceval, elapsed_time, pid, t_cpu, t_sleep, nsched, timeslice);
fclose (fp);
exit (0);
}
说明: 首先说明的是/proc/[pid]/schedstat:在这个文件下放着3个变量,他们分别代表什么意思呢?
- 第一个:该进程拥有的cpu的时间
- 第二个:在对列上的等待时间,即睡眠时间
- 第三个:被调度的次数

由结果可以看出当nice的值越小的时候,其睡眠时间越短,则表示其优先级升高了。
7.关于获取和设置优先级的系统调用
sched_getscheduler()和sched_setscheduler:
#include <sched.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#define DEATH(mess) { perror(mess); exit(errno); }
void printpolicy (int policy)
{
/* SCHED_NORMAL = SCHED_OTHER in user-space */
if (policy == SCHED_OTHER)
printf ("policy = SCHED_OTHER = %d
", policy);
if (policy == SCHED_FIFO)
printf ("policy = SCHED_FIFO = %d
", policy);
if (policy == SCHED_RR)
printf ("policy = SCHED_RR = %d
", policy);
}
int main (int argc, char **argv)
{
int policy;
struct sched_param p;
/* obtain current scheduling policy for this process */
//获取进程调度的策略
policy = sched_getscheduler (0);
printpolicy (policy);
/* reset scheduling policy */
printf ("
Trying sched_setscheduler...
");
policy = SCHED_FIFO;
printpolicy (policy);
p.sched_priority = 50;
//设置优先级为50
if (sched_setscheduler (0, policy, &p))
DEATH ("sched_setscheduler:");
printf ("p.sched_priority = %d
", p.sched_priority);
exit (0);
}
输出结果:
[root@wang schedule]# ./get_schedule_policy
policy = SCHED_OTHER = 0
Trying sched_setscheduler...
policy = SCHED_FIFO = 1
p.sched_priority = 50
可以看出进程的优先级已经被改变。
三、TCP/IP协议
1.OSI模型
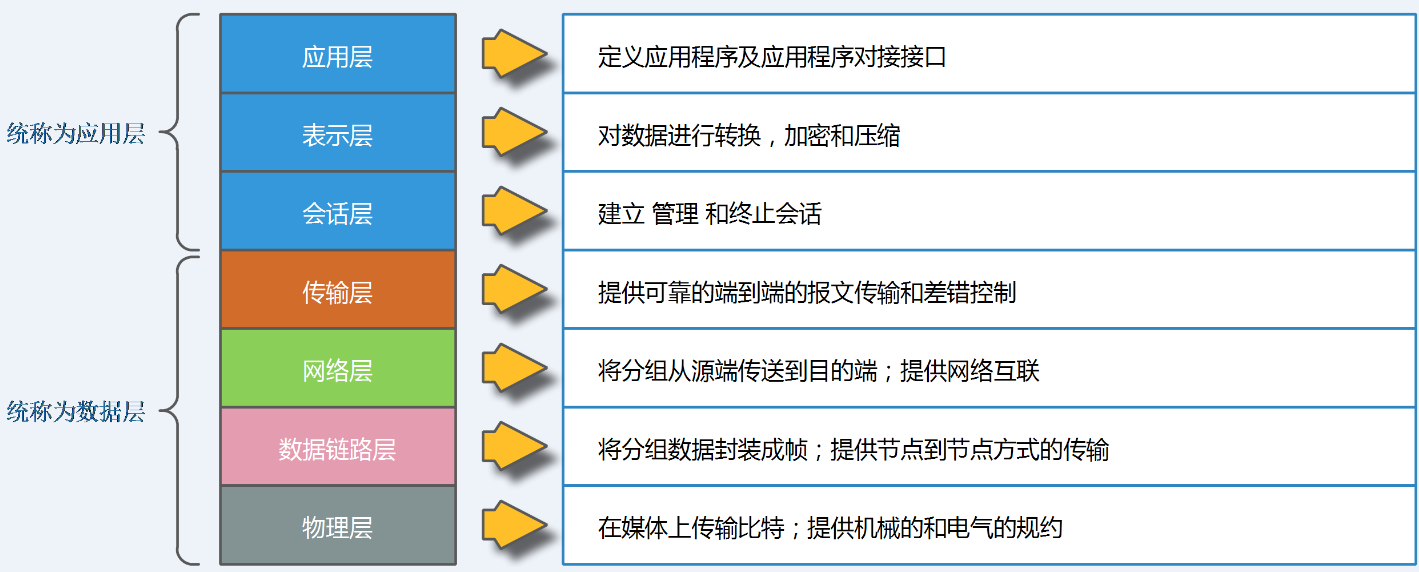
OSI参考模型,是由ISO(国际标准化组织)定义的一个灵活的稳健的和可互操作的模型,并不是协议,是用来了解和设计网络体系结构的。使用网络参考模型的目的是规范不同系统的互联标准,使两个不同的系统能够较容易的通信,而不需要改变底层的硬件或者软件的逻辑,每一层指定了不同协议标准。
OSI把网络按照层次分为七层,由下到上分别为物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。每个层次对应了相应的标准或者协议,功能如图所示:
-
应用层:文件传输,电子邮件,文件服务,虚拟终端 TFTP,HTTP,SNMP,FTP,SMTP,DNS,TELNENET;
-
表示层:数据格式化,代码转换,数据加密,没有协议;
-
会话层:解除或者建立与别的节点的联系 没有协议;
-
传输层:提供端到端的接口 TCP、UDP;
-
网络层:数据包选择路由,就是选择数据包转发的路径以及网络的检测和控制,IP,ICMP,RIP,OSPF,BGP,IGMP;
-
数据链路层:传输有地址的帧及错误检测功能 SLIP,CSLIP,PPP,ARP,PARP,MTU;
-
物理层:以二进制的形式在屋里媒体上传输ISO2110,IEEE802,IEEE802.2;
2.TCP/IP网络模型
OSI七层模型简化四层TCP/IP模型,应用层、表示层、会话层统称为应用层,传输层称为主机到主机层,网络层即为因特网层,数据链路层和网络层统称为网络接入层。网络层次模型组成部分如图3所示:
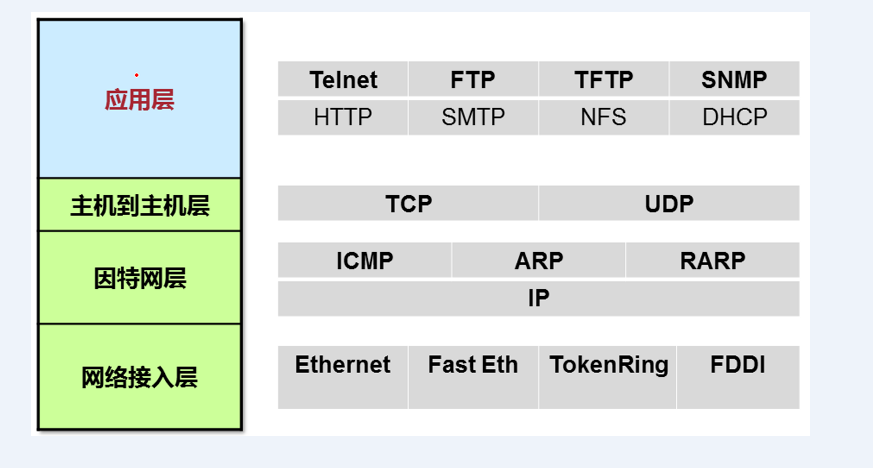
3.Linux网络结构
对于Linux系统来讲,在具体实现网络传输中,主要有Linux协议栈来完成。Linux协议栈主要实现了四层结构:
- 应用层:HTTP
- 传输层:TCP
- 网络层:IP
- 链路层:Ethernet driver
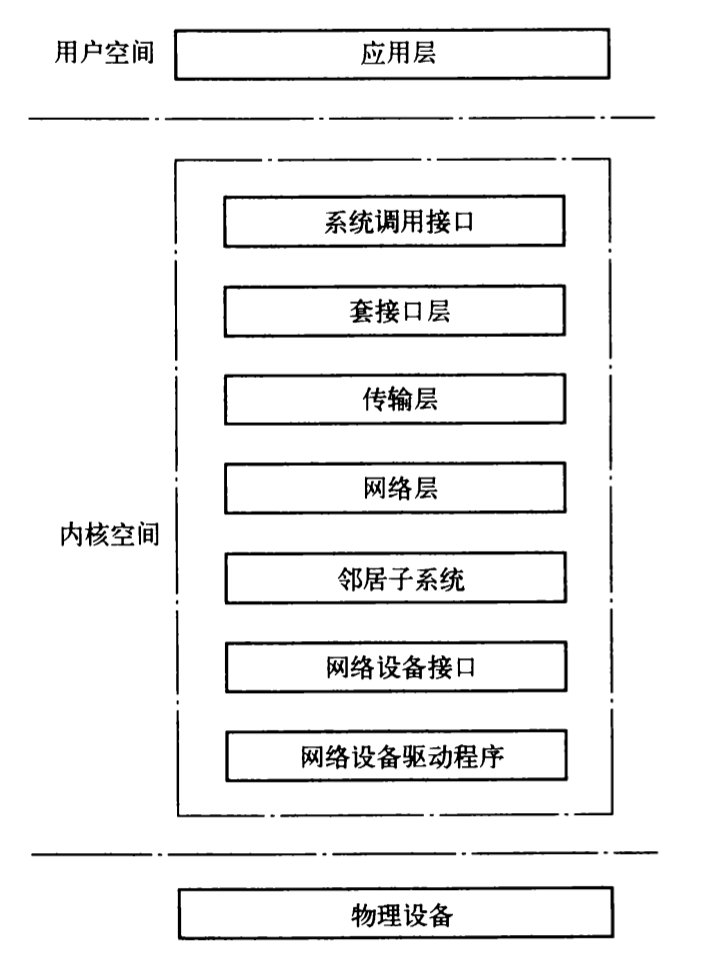
应用层主要在用户空间,用户空间的各个APP模块实现了Linux设备的各种不同的功能。例如对于一台Linux路由器来讲,用户空间实现了路由协议、mpls协议、dhcp协议等一些具体应用功能的模块。
Linux的内核空间为应用层的各协议模块提供收发数据包的功能,上层协议统一都由Linux内核协议栈提供的系统调用接口。Linux协议栈只要完成的就是内核空间的各个网络子系统的实现。
在网络协议栈内部流动的是套接字缓冲区(SKB),用于协议栈的底层、上层以及应用层之间传递报文数据。
物理设备,提供对网络的链接能力。例如网卡收发包交换芯片等。
下面介绍内核空间的子模块的功能:
- 系统调用接口:所谓系统调用就是内核提供给用户的调用api接口。网络子系统调用接口为用户空间提供两种的调用接口给用户。一种是提供特有的调用进入系统内核,然后进一步调用sys_socketcall结束该进程。sys_socketcall根据系统调用号调用具体功能。另一种是通过socket系统调用,通过普通的文件操作来访问子系统。常用的系统调用socket、send、accept、connect、listen、read、write等。
- 套接口层:套接口是一个与协议无关的接口,他提供了一组接口来支持各种协议。例如他支持典型的TCP和UDP,同时还支持RAW套接口、RAW以太网和其他协议。
- 传输层的协议:传输层使用传输控制块存放套接口所需的信息,包括TCP传输块、UDP传输块、RAW传输控制块。例如传输层控制块包括两个方向的序列号、窗口大小、重传次数。传输层的控制块tcp_sock结构在inet_sock结构基础上构成的,而inet_sock在sock基础上创建。套接口的ops字段指向特定传输协议的操作集接口,proto_ops结构中定义的函数就是套接口调用到传输层调用接口,整个proto_ops是一张套接口系统调用跳转表。
- 套接口的缓存:套接口缓存用来存储数据的缓冲区,该缓冲区可以处理可变长数据,通过在数据区添加和移除数据,避免数据的复制。该缓冲区传递网络驱动程序和应用程序之间的数据包。
- 设备无关接口:网络协议栈的底部是一个与硬件无关的接口层,它提供了一组通用的函数供底层设备和上层协议栈进行调用,从而使得上层协议栈和底层驱动设备都不必关心对方的实现,屏蔽掉差异性。NAPI技术是一种中断和轮询机制的混合体,在网络负载严重时,减少由于收包产生的中断,对高频小数据包的处理很有效。
- 设备驱动程序:网络设备可以动态的注册到系统中,提高了驱动设备的灵活性。register_netdevice和unregister_netdevice是驱动设备注册和解注册的函数。net_device结构中的hard_start_xmit在初始化时设置该接口,实现向网络设备输出数据包。
四、send和resv
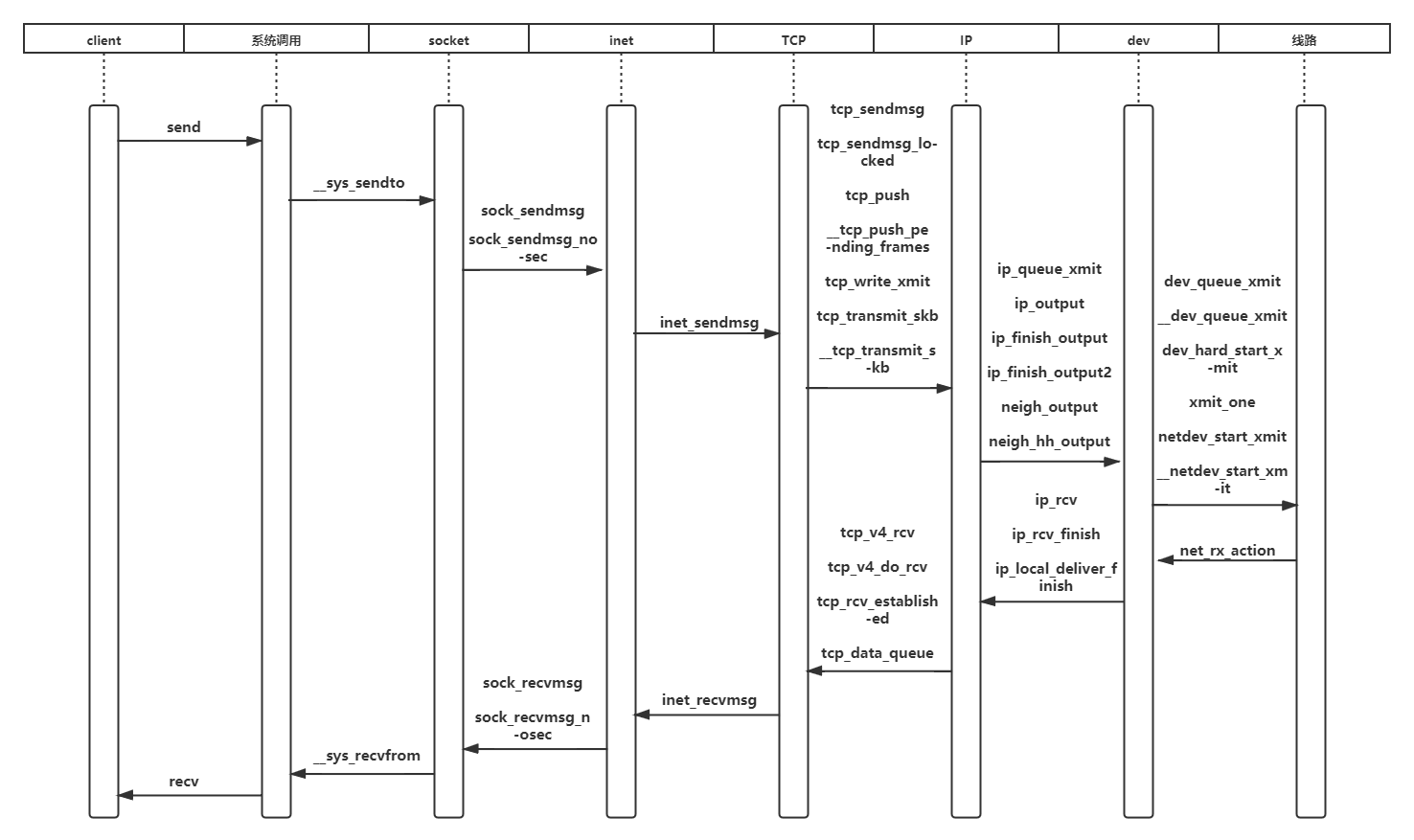
1.send调用过程分析
1.1 应用层
send函数首先通过系统调用sys_sendto函数
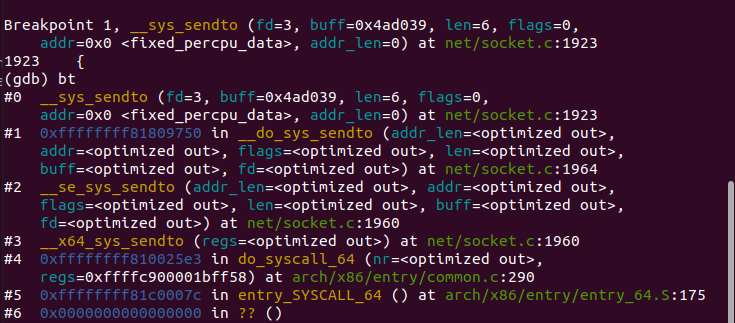
在Linux中,处处皆文件,socket也不例外。这个函数通过fd寻找对应的socket结构体,然后发送数据包的相关信息给内核,该消息结构体为msghdr,最后调用sock_sendmsg。
一直运行到调用inet_sendmsg:
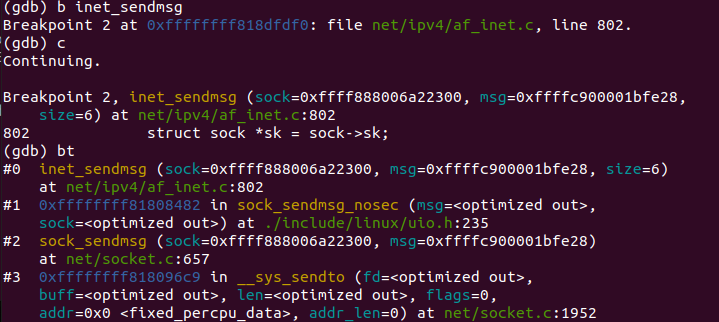
该函数具体到tcp_sendmsg和udp_sendmsg,这也是应用层的最后一个调用。
1.2 传输层
传输层负责数据包传输,分为TCP和UDP,本次采用TCP,所以调用tcp_sendmsg负责发送,该函数给sk加锁后调用tcp_sendmsg_locked函数。该函数要完成的工作就是将应用程序要发送的数据组织成skb,然后尽可能的发出去。
主要流程包括获取当前的MSS、网络设备支持的最大数据长度size_goal;遍历用户层的数据块数组,获取发送队列的最后一个skb,如果是尚未发送的,且长度尚未达到size_goal,那么可以往此skb继续追加数据,否则需要申请一个新的skb来装载数据。接下来就是拷贝消息头中的数据到skb中了,如果skb的线性数据区已经用完了,那么就使用分页区,拷贝成功后更新:送队列的最后一个序号、skb的结束序号、已经拷贝到发送队列的数据量,尽可能的将发送队列中的skb发送出去。
之后是TCP具体传输方式的实现tcp_write_xmit,如图:

tcp_write_xmit()将发送队列上的SBK发送出去,返回值为0表示发送成功。函数执行过程主要有判断正在网络上传输的包数目是否超过拥塞窗口,如果超过了,则不发送;判断当前报文完全到达发送窗口;判断发送算法是否为nagle算法;通过以上判断后将该skb发送出去;更新发送窗口状态发送下一个skb。最终调用的是tcp_transmit_skb函数,又调用了__tcp_transmit_skb函数传输到IP协议相关参数。
tcp_transmit_skb复制或者拷贝skb,构造skb中的tcp首部,并将调用主机到主机层的发送函数发送skb;在发送前,首先需要克隆或者复制skb,因为在成功发送到网络设备之后,skb会释放,而tcp层不能真正的释放,是需要等到对该数据段的ack才可以释放;然后构造tcp首部和选项;最后调用该层提供的发送回调函数发送skb,ip层即因特网层的回调函数为ip_queue_xmit。
1.3 网络层
本层的功能主要与IP有关,包括路由,IP数据报等。之前的ip_queue_xmit函数调用__ip_queue_xmit函数以完成面向连接套接字的包输出。如图:
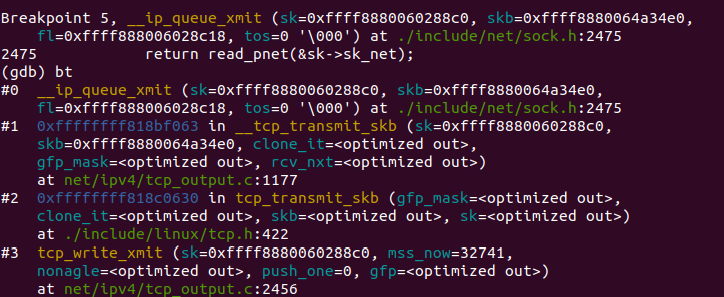
当套接字处于连接状态时,所有从套接字发出的包都具有确定的路由, 无需为每一个输出包查询它的目的入口,可将套接字直接绑定到路由入口上, 这由套接字的目的缓冲指针(dst_cache)来完成。ip_queue_xmit()首先为输入包建立IP包头, 经过本地包过滤器后,再将IP包分片输出(ip_fragment)。检查完分片之后,则会调用邻居子系统的输出函数neigh_output进行输出,输出则分为有二层头缓存和没有两种情况,有缓存时调用neigh_hh_output进行快速输出,没有缓存时,则调用邻居子系统的输出回调函数进行慢速输出。
1.4 网络接入层
Linux 用户想要使用网络功能,不能通过直接操作硬件完成,而需要直接或间接的操作一个 Linux 为我们抽象出来的设备,既通用的 Linux 网络设备来完成。本层的工作就是对抽象的网络设备进行选择传输。neigh_hh_output调用dev_queue_xmit函数,当前调用栈如图12:

而dev_queue_xmit实际返回函数__dev_queue_xmit。该函数是设备驱动程序执行传输的接口。也就是所有的数据包在填充完成后,最终发送数据时,都会调用该函数。从此函数可以看出,当驱动使用发送队列的时候会循环从队列中取出包向外发出,而不使用队列的时候只发送一次,如果没发送成功就直接丢弃。经过队列选择后,如图:

最后根据驱动配置相应的硬件进行传输。
2.recv过程源代码分析
2.1 网络接入层
Linux内核2.4以后,整个协议栈主要使用软中断softirq。软中断softirq优势明显,可以同时在多个 CPU 上执行。这一阶段会根据协议的不同来处理数据分组。CPU开始处理软中断 do_softirq,接着net_rx_action处理前面标记的NET_RX_SOFTIRQ,把出队列的skb送入相应列表处理(根据协议不同到不同的列表)。比如,IP分组交给ip_rcv处理,ARP分组交给 arp_rcv处理等,如图:
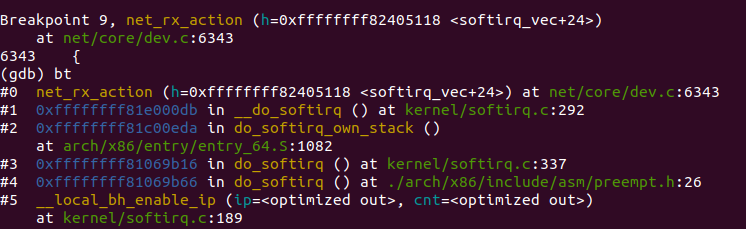
该函数调用设备的poll方法(默认为process_backlog),而process_backlog函数将进一步调用netif_receive_skb将数据包传上协议栈,如果设备自身注册了poll函数,也将调用netif_receive_skb函数。网桥的处理入口netif_receive_skb里面,针对IP协议,ip_rcv函数被调用。
2.2 因特网层
ip_rcv函数验证IP分组,比如目的地址是否本机地址ß,校验和是否正确等。若正确,则交给netfilter的NF_IP_PRE_ROUTING钩子,否则就丢弃。到了ip_rcv_finish函数,数据包就要根据skb结构的目的或路由信息判断数据包的去向。如图:
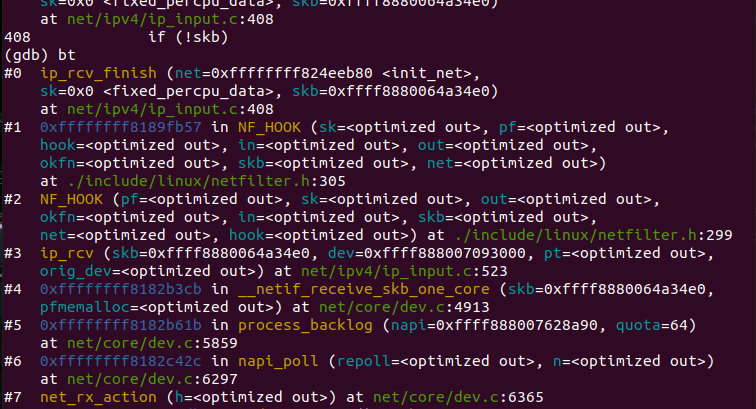
ip_local_deliver处理到本机的数据分组;ip_forward处理需要转发的数据分组;ip_mr_input转发组播数据包。如果是转发的数据包,还需要找出出口设备和下一跳。具体来说,从skb->nh(IP头,由netif_receive_skb初始化)结构得到IP地址;而skb->dst 或许包含了数据分组到达目的地的路由信息,如果没有,则需要查找路由,如果最后结果显示目的地不可达,那么就丢弃该数据包。ip_rcv_finish函数最后执行dst_input,决定数据包的下一步的处理。
2.3 传输层
由上一步ip_local_deliver得到协议为TCP,调用tcp_v4_rcv。tcp_v4_rcv函数主要做以下几个工作:
(1)设置TCP_CB
(2)查找控制块
(3)根据控制块状态做不同处理,包括TCP_TIME_WAIT状态处理,TCP_NEW_SYN_RECV状态处理,TCP_LISTEN状态处理
(4)接收TCP段。
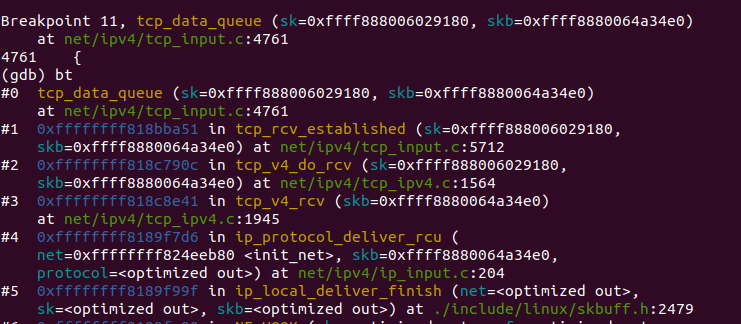
tcp_v4_rcv之后调用tcp_v4_do_rcv函数,该函数检查是否已连接套接字,若是已连接则调用tcp_rcv_established处理,其过程根据首部预测字段分为快速路径和慢速路径,区别在于检查的细致程度。
再由tcp_data_queue分多种情况接收处理数据段,当前函数调用栈如图16所示:
recvmsg系统调用在tcp层的实现是tcp_recvmsg函数,该函数完成从接收队列中读取数据复制到用户空间的任务:
函数在执行过程中会锁定控制块,避免软中断在tcp层的影响;
函数会涉及从接收队列receive_queue,预处理队列prequeue和后备队列backlog中读取数据;
其中从prequeue和backlog中读取的数据,还需要经过sk_backlog_rcv回调,该回调的实现为tcp_v4_do_rcv,实际上是先缓存到队列中,然后需要读取的时候,才进入协议栈处理。
此时,是在进程上下文执行的,因为会设置tp->ucopy.task=current,在协议栈处理过程中,会直接将数据复制到用户空间。
2.4 应用层
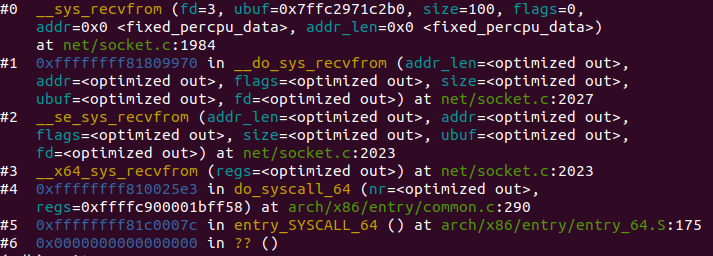
recv过程的该层函数调用与send过程类似,内核函数为__sys_recvfrom,通过调用sock_recvmsg来对数据进行接收,该函数实际调用的是sock->ops->recvmsg(sock, msg, msg_data_left(msg), flags);同样类似send过程中,调用的实际上是socket在初始化时赋值给结构体struct proto tcp_prot的函数tcp_rcvmsg,由此与下层函数相连,如图:
五、时序图