0.前言
本博客主要使用了VS Code+GCC工具局,编译调试使用了孟宁老师的课程项目案例menu。并同时结合代码分析其中的软件工程方法、规范或软件工程思想。
1.编译和环境配置
首先我们必须下载gcc,因为我使用的是mac版本,所以安装还算简单,直接使用
brew install gcc即可
完成之后,我们使用VSCode,在扩展部分安装C/C++插件:

为了测试我们的配置有没有起作用,我们编写一个经典的程序
#include<stdio.h>
int main()
{
printf("hello world
");
return 0;
}
编译并且运行这个文件
我们看到正确的输出,证明我们成功了。
2.代码分析
2.1 模块化设计
模块化(Modularity)是在软件系统设计时保持系统内各部分相对独立,以便每一个部分可以被独立地进行设计和开发。模块化实现了高内聚、低耦合,使软件更容易升级和修改。一般我们使用耦合度(Coupling)和内聚度(Cohesion)来衡量软件模块化的程度。
我们现在可以阅读源码的lab3.2和lab3.3
3.2的数据结构和逻辑实现被分离出来了。
我们可以发现内部实现的逻辑代码其实没有什么差别,但是通过将数据结构和函数声明放到了linklist.h文件并且具体实现在linklist.c文件中。可能这时候我们还不太明白,但是看了老师的PPT。我们得知
进行了模块化设计之后我们往往将设计的模块与实现的源代码文件有个映射对应关系,因此我们需要将数据结构和它的操作独立放到单独的源代码文件中,这时就需要设计合适的接口,以便于模块之间互相调用。
linklist.h文件和linklist.c文件
结合实际代码和下图:
typedef struct DataNode { char* cmd; char* desc; int (*handler)(); struct DataNode *next; } tDataNode; /* find a cmd in the linklist and return the datanode pointer */ tDataNode* FindCmd(tDataNode * head, char * cmd); /* show all cmd in listlist */ int ShowAllCmd(tDataNode * head); tDataNode* FindCmd(tDataNode * head, char * cmd) { //具体实现 } int ShowAllCmd(tDataNode * head) { //具体实现 }
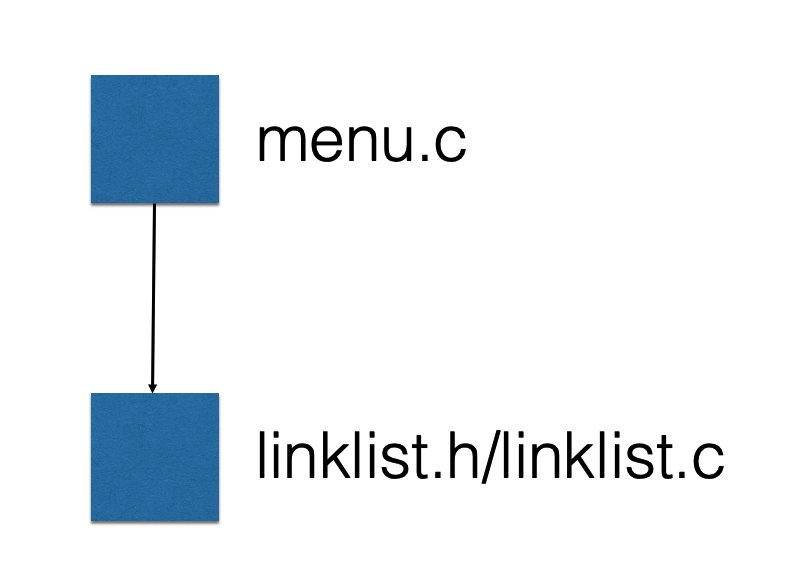
从而初步实现了模块化的思想.
2.2 可重用接口
软件模块接口在面向过程的语言中一般是定义一些数据结构和函数接口API,在面向对象的编程语言中一般在类或接口类中定义一些公有的(public)属性和方法。
尽管已经做了初步的模块化设计,但是分离出来的数据结构和它的操作还有很多菜单业务上的痕迹,我们要求这一个软件模块只做一件事,也就是功能内聚,那就要让它做好链表数据结构和对链表的操作,不应该涉及菜单业务功能上的东西;同样我们希望这一个软件模块与其他软件模块之间松散耦合,就需要定义简洁、清晰、明确的接口。
让我们继续精读代码,我们在lab4之后可以发现一个新的数据结构。
typedef struct LinkTableNode { struct LinkTableNode * pNext; }tLinkTableNode;
代表链接的链表,而没有具体的值。同时新增了一些函数API,我们拿一个来举例:
/* * get LinkTableHead */ tLinkTableNode * GetLinkTableHead(tLinkTable *pLinkTable);
该接口的目标是从链表中取出链表的头节点,函数名GetLinkTableHead清晰明确地表明了接口的目标;
•该接口的前置条件是链表必须存在使用该接口才有意义,也就是链表pLinkTable != NULL;
•使用该接口的双方遵守的协议规范是通过数据结构tLinkTableNode和tLinkTable定义的;
•使用该接口之后的效果是找到了链表的头节点,这里是通过tLinkTableNode类型的指针作为返回值来作为后置条件,C语言中也可以使用指针类型的参数作为后置条件;
•该接口没有特别要求接口的质量属性,如果搜索一个节点可能需要在可以接受的延时时间范围内完成搜索;
通过孟宁老师的举例我们应该明白了接口的作用,在高内聚低耦合上更近了一步。
另外,如果读到lab5,你会发现一个方法。
/* * Search a LinkTableNode from LinkTable * int Conditon(tLinkTableNode * pNode,void * args); */ tLinkTableNode * SearchLinkTableNode(tLinkTable *pLinkTable, int Conditon(tLinkTableNode * pNode, void * args), void * args);
孟宁老师说过,利用callback函数参数使Linktable的查询接口更加通用,有效地提高了接口的通用性.这样可以有效地隐藏软件模块内部的实现细节,为外部调用接口的开发者提供更加简洁的接口信息,同时也减少外部调用接口的开发者有意或无意的破坏软件模块的内部数据。相信你已经感受到了可重用接口的便利和方便性。
2.3 线程安全
在多线程环境下,为了提高效率,多个线程可能执行同一段代码,由此引起了并发安全问题。如果多线程运行和单线程运行没有任何区别,就是线程安全的。线程安全问题都是由对共享变量的写操作引起的。若每个线程中对共享变量只有读操作,而无写操作;若有多个线程同时执行读写操作,一般都需要考虑线程同步,否则就可能影响线程安全。
总的来说呢,就是要利用读写锁来实现线程安全
我们使用老师的lab7的一个代码块来解读一下:
/* * Add a LinkTableNode to LinkTable */ int AddLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode) { if(pLinkTable == NULL || pNode == NULL) { return FAILURE; } pNode->pNext = NULL; pthread_mutex_lock(&(pLinkTable->mutex)); //加锁 if(pLinkTable->pHead == NULL) { pLinkTable->pHead = pNode; } if(pLinkTable->pTail == NULL) { pLinkTable->pTail = pNode; } else { pLinkTable->pTail->pNext = pNode; pLinkTable->pTail = pNode; } pLinkTable->SumOfNode += 1 ; pthread_mutex_unlock(&(pLinkTable->mutex)); //释放锁 return SUCCESS; }
我们可以看到,这个函数主要是用来添加一个结点,因为可能有多个线程同时在运行,所以为了保证数据不被破坏,在对数据修改的时候使用了锁。这样就可以保证数据的成功添加。
2.4 代码规范和代码风格
在孟宁老师的PPT里,强调了代码的风格和注释的重要性,一个好的代码风格和注释能给予人焕然一新的感觉。

我们可以发现:
•注释和版权信息:注释也要使用英文,不要使用中文或特殊字符,要保持源代码是ASCII字符格式文件;
•不要解释程序是如何工作的,要解释程序做什么,为什么这么做,以及特别需要注意的地方;
•每个源文件头部应该有版权、作者、版本、描述等相关信息。
此外还有其他的应该注意的方法,这些规则我们应该尽量应用到我们今后的代码风格中,养成良好习惯
•缩进:4个空格;
•行宽:< 100个字符;
•代码行内要适当多留空格,如“=”、“+=” “>=”、“<=”、“+”、“*”、“%”、“&&”、“||”、“<<”,“^”等二元操作符的前后应当加空格。对于表达式比较长的for语句和if语句,为了紧凑起见可以适当地去掉一些空格,如for (i=0; i<10; i++)和if ((a<=b) && (c<=d));
•在一个函数体内,逻揖上密切相关的语句之间不加空行,逻辑上不相关的代码块之间要适当留有空行以示区隔;
•在复杂的表达式中要用括号来清楚的表示逻辑优先级;
•花括号:所有 ‘{’ 和 ‘}’ 应独占一行且成对对齐;
•不要把多条语句和多个变量的定义放在同一行;
•命名:合适的命名会大大增加代码的可读性;
•类名、函数名、变量名等的命名一定要与程序里的含义保持一致,以便于阅读理解;
•类型的成员变量通常用m或者来做前缀以示区别;
•一般变量名、对象名等使用LowerCamel风格,即第一个单词首字母小写,之后的单词都首字母大写,第一个单词一般都表示变量类型,比如int型变量iCounter;
•类型、类、函数名等一般都用Pascal风格,即所有单词首字母大写;
•类型、类、变量一般用名词或者组合名词,如Member
•函数名一般使用动词或者动宾短语,如get/set,RenderPage;
3.总结
我们开发软件的时候,要遵循软件开发的一般流程。通过孟宁老师这个课程,我们能更深刻的理解软件开发过程的方法,在模块化,可重用,线程安全,代码规范上理解更深一步。
参考资料:
1.孟宁老师的gitee:https://gitee.com/mengning997
2.工程化编程实战--代码中的软件工程:https://mp.weixin.qq.com/s/KJ4oU5ggccu1f5mMaEo1eg