练习一:
第一步:打入课本代码如下:
assume cs:code,ds:data,ss:stack
data segment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
data ends
stack segment
dw 0,0,0,0,0,0,0,0
stack ends
code segment
start: mov ax,stack
mov ss,ax
mov sp,16
mov ax,data
mov ds,ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
code ends
end start
在文本文档中打入代码之后对代码进行分析:
由代码第一行看出在这个代码中定义了三个段:代码段,数据段,栈段。
在代码中标红色的是对数据段的定义(由开始到结束ends):定义数据段用来放入程序中用到的数据,需要处理的数据。
标绿色的是栈段的定义(由开始到结束ends):其中注意:既然要定义一个栈段,那么就一定要定从哪到哪是这个栈,就是要得到一段空间,然后通过ss,sp的指向来让计算机认为它是作为栈来使用的,这一段空间的获取方法就是使用define word伪指令来获得,通过dw命令向内存中放入所需个数的字型垃圾值,便可以获得指定大小的栈空间。
标蓝色的是代码段的定义:在代码段定义中的第一行有一个start标号与代码最后一行呼应,实现了规定程序入口(即在程序执行时让command知道如何设置cs:ip的值,从而能从start标号开始执行程序)的功能。
总结:在对段的定义中的data,stack,code这三个名称,并非计算机规定,而是人为起的名字,这三个名字完全可以改成其他名字(如a,b,c等),这就说明计算机将哪一段作为什么段来进行处理并不是凭借我们人为给他起的名字,之所以计算机会将这三个人为定义的段作为我们需要的段来进行处理,是因为:在程序执行的时候,CPU从程序的入口处开始执行程序,而在程序的入口及以后的代码中,我们使用data,stack这两个段名(也是定义段的段地址)分别对实际的ds,ss进行了赋值,以此CPU就知道要把data这个段作为数据段,把stack这个段作为栈段。
第二步:
对源文件进行汇编、连接: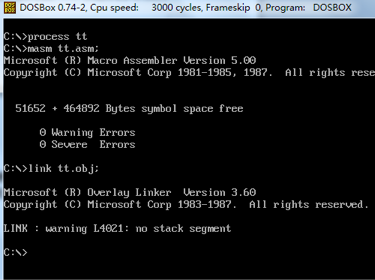
第三步:
对tt.exe进行debug:
从第一条要执行的指令来看,start标号确实起了作用,让程序从code段的第一行开始执行。
反汇编: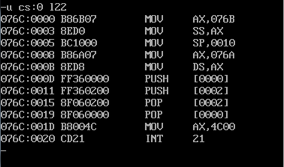
让代码执行到mov ax,4c00h之前:
查看数据段中的值:
观察发现:
程序返回之前:data中的数据没有发生改变。
程序返回前:cs=076c,ss=076b,ds=076a。
程序加载后,code段的段地址为x,则data段的段地址为x-2,stack段的段地址为x-1。
练习二:
第一步:打入课本代码如下:
assume cs:code, ds:data, ss:stack
data segment
dw 0123h, 0456h
data ends
stack segment
dw 0, 0
stack ends
code segment
start: mov ax,stack
mov ss, ax
mov sp,16
;刚开始我注意到此处的sp的值和栈的长度的对比,正常情况sp应该赋值为十进制5
;我感觉压栈的位置不太对
mov ax, data
mov ds, ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
code ends
end start
第二步:汇编,连接。
第三步:debug:
对比上一题中的cx的值发现两个程序所占总字节数是一样的,可是从字面上看两者的栈段和数据段所分配的空间并不一样。在做反汇编的操作时,我仍然像之前那样通过cx的值来得到总字节数,然后在用字节数减去数据段和栈段的长度(在这一个练习中我用0042h减去4再减去4得到003a),然后我使用这个长度从cs开始反汇编,发现结果是不对的,这说明,我之前所算出的长度是错误的。
于是我进行了如下一些尝试:
改变数据段和栈段中定义数据dw的长度后,查看代码占的总字节数:
我发现:
一、不管是:
只改变栈段中dw定义的字数据的个数。
只改变数据段中dw定义的字数据的个数。
还是同时改变两个段中dw定义的长度。
最终总字节数都是0042h个。
二、但是:
1) 当我只改变栈段中的dw略超过8个字后,总字节数就变成了0042h+10h=0052h
2) 当我只改变数据段中的dw略超过8个字后,总字节数也变成了0042h+10h=0052h
3) 当我在改变栈段中的dw略超过8个字的前提下,我再将数据段中的dw改变使其略超过8个字后,发现总字节数变成了0042h+10h+10h=0062h
第一点和第二点说明了:在使用dw来给栈段或者数据段分配空间的时候只要分配长度不超过十进制16个字节(8个字),那么栈段或者数据段所占的空间就是16个字节,另外,当
使用dw来给栈段或者数据段分配空间时,若长度超过8个字,则栈段或者数据段所占空间直接增加16个字节。
所以练习二的反汇编操作中对代码段反汇编从cs开始的字节数L就可以根据结论得到等于0042h-10h-10h=0022h(和上一题一样)。
反汇编: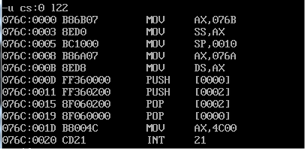
将程序执行到返回之前:
可见在返回之前cs=076c,ss=076b,ds=076a。
通过cs,ds,ss中值的关系得到code段的段地址减一等于stack段的段地址,减二等于data段的段地址。
查看data段中的数据:
发现没有改变。
对于书上的第三问(拓展到了任意的段):在任意一个段中,程序加载之后,该段实际占有空间是(N除以16向下取余再加1)*16(单位:字节)或者是(N+16)/16向下取余再加1(单位:16个字节)。
练习三:
第一步:打入课本代码如下:
assume cs:code, ds:data, ss:stack
code segment
start: mov ax,stack
mov ss, ax
mov sp,16
mov ax, data
mov ds, ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
code ends
data segment
dw 0123h, 0456h
data ends
stack segment
dw 0,0
stack ends
end start
注意到:这个代码和练习二的代码的区别只在于书写顺序的不同,即定义栈段和数据段的地方有所不同。
第二步:汇编,连接。
第三步:debug:
此处发现问题:发现cx的值和之前练习二的值有了不同:多了两个字节。暂时先不管。
对程序进行反汇编并用g命令执行到返回之前以及查看data段中的数据: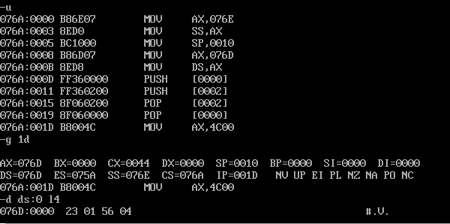
发现data段中的数据没有改变。
在程序返回前cs=076a,ds=076d,ss=076e
所以在练习三的代码中code若设code段的段地址为x,那么data段的段地址为x+3,stack段的段地址为x+4。
练习四:将练习1、2、3中的最后一条伪指令改为end即将标记入口的start去掉,查看程序的运行状况。
对练习一操作并debug: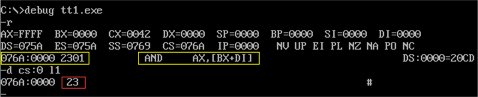
发现所执行的第一条语句显然不是我想要执行的语句,可以看出因为没有指定程序的入口而导致了CPU直接把数据段的第一个数据当成指令来处理了,这样执行的话显然不符合要求,因为我要对数据段中的数据进行操作,我的指令写在别的地方。
对练习二进行操作并debug:
显然也是不对的。
对练习三进行操作并debug:
指令正确。
综上:实验三的代码可以正确执行。
下面对代码进行比较分析:
实验一和实验二的代码有一个共同的特点:就是它们的栈段和数据段均是在代码段之前定义的,这也是它们和实验三代码的共同区别。
经过分析发现如果整个代码不标明程序的入口的话,默认是从第一条开始执行的,而实验三的代码恰好第一行就是从指令段开始的,所以代码三可以正确执行。
练习五:
第一步:设计代码(如下):
assume cs:code
a segment
db 1,2,3,4,5,6,7,8
a ends
b segment
db 1,2,3,4,5,6,7,8
b ends
c segment
db 8 dup(0)
c ends
code segment
start:
mov cx,8 ;下划线的这一段是为了依次查看进入循环之前a,b,c段中的数据
mov bx,0
mov ax,a
mov ds,ax
mov ax,b
mov ds,ax
mov ax,c
mov ds,ax
;进入循环
s:
mov ax,a
mov ds,ax
mov ax,0
;将数据段寄存器中的值改为a段的段地址,改完之后再置ax的值为0备用
add al,[bx]
;将a段中偏移地址为bx的字节型数据加到al中
mov dx,b
mov ds,dx
;将数据段寄存器中的值改为b段的段地址
add al,[bx]
;将b段中偏移地址为bx的字节型数据加到al中
mov dx,c
mov ds,dx
;将数据段寄存器中的值改为c段的段地址
add [bx],al
;将al中加好的字节型数据放到c段中偏移地址为bx的地方,第一次循环bx=0
inc bx
;将bx自加
loop s
mov ax,4c00h
int 21h
code ends
end start
代码思想:
中转的思想:实验要求将a段和b段的数据依次相加,再将结果放入c段中。所以我想到用循环来实现,并且每一次循环都要进行如下操作:
使用一个8位寄存器来储存加好的值和对ds值得设置。
不得不多使用一个寄存器来实现将c段的段地址来赋值给ds,从而才能将加好的值送到c段中。
每次进入循环都要将用来储存加好的值得8位寄存器置零。
第二步:汇编连接。
第三步:debug查看结果:
查看进入循环操作之前a段中的数据: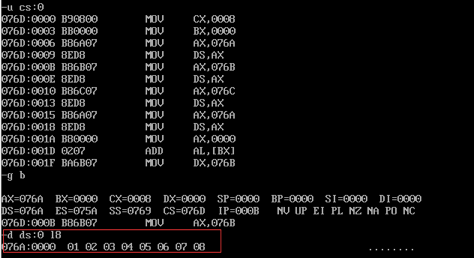
可以发现的确是1~8的字节型数据。
查看进入循环操作之前b段中的数据:
可以发现也是1~8的字节型数据。
查看进入循环操作之前c段中的数据:
正确,因为我再进入循环之前没有对c段进行任何赋值操作。
接着执行程序一直到返回之前并查看c段中的前8个字节的数据: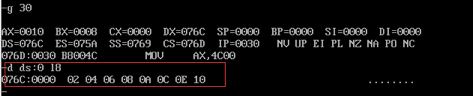
c段中的数据已经被更改为a段和b段相加之和,正确。
练习六:
第一步:设计代码:
assume cs:code
a segment
dw 1,2,3,4,5,6,7,8,9,0ah,0bh,0ch,0dh,0eh,0fh,0ffh
a ends
b segment
dw 8 dup(0)
b ends
code segment
start:
mov ax,b
mov ss,ax
mov sp,10h
mov ax,a
mov ds,ax
mov bx,0
mov cx,8
s: push [bx]
add bx,2
loop s
mov ax,4c00h
int 21h
code ends
end start
代码思想:将a段中的前8个字数据逆序存储到b段中,就是将b段看成栈段,然后进行压栈。
第二步:汇编连接。
第三步:debug查看结果:
查看压栈之前b段中的数据: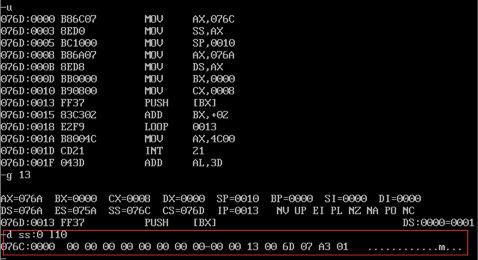
查看压栈之后b段中的数据: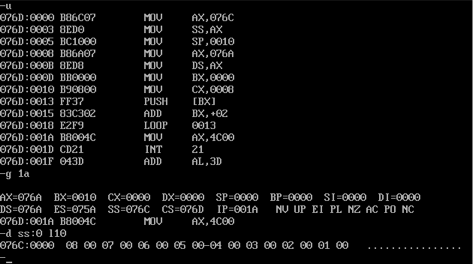
发现已经实现了将a段中的前8个字数据逆序放入到了b段中。
实验感悟:
实验一到实验四让我了解到:代码是如何被执行的,以及程序入口的使用,以及一个“段”的字节数和它在内存中具体所占空间大小的关系。以及在未定义程序入口位置时程序默认从第一行(可以是栈段,数据段或者代码段)开始的特点、定义三个段分别和三个寄存器cs,ss,ds联系在一起的时候这三个段的段地址之间的关系。
实验五和六只要让我了解到较多数据的存储使用循环来处理,在使用我定义的段之前一定要将其和具体的寄存器联系起来。以及在使用栈段(即给ss,sp赋值的时候,sp应该赋值成什么)。