概述
强化学习是一门多学科交叉的技术

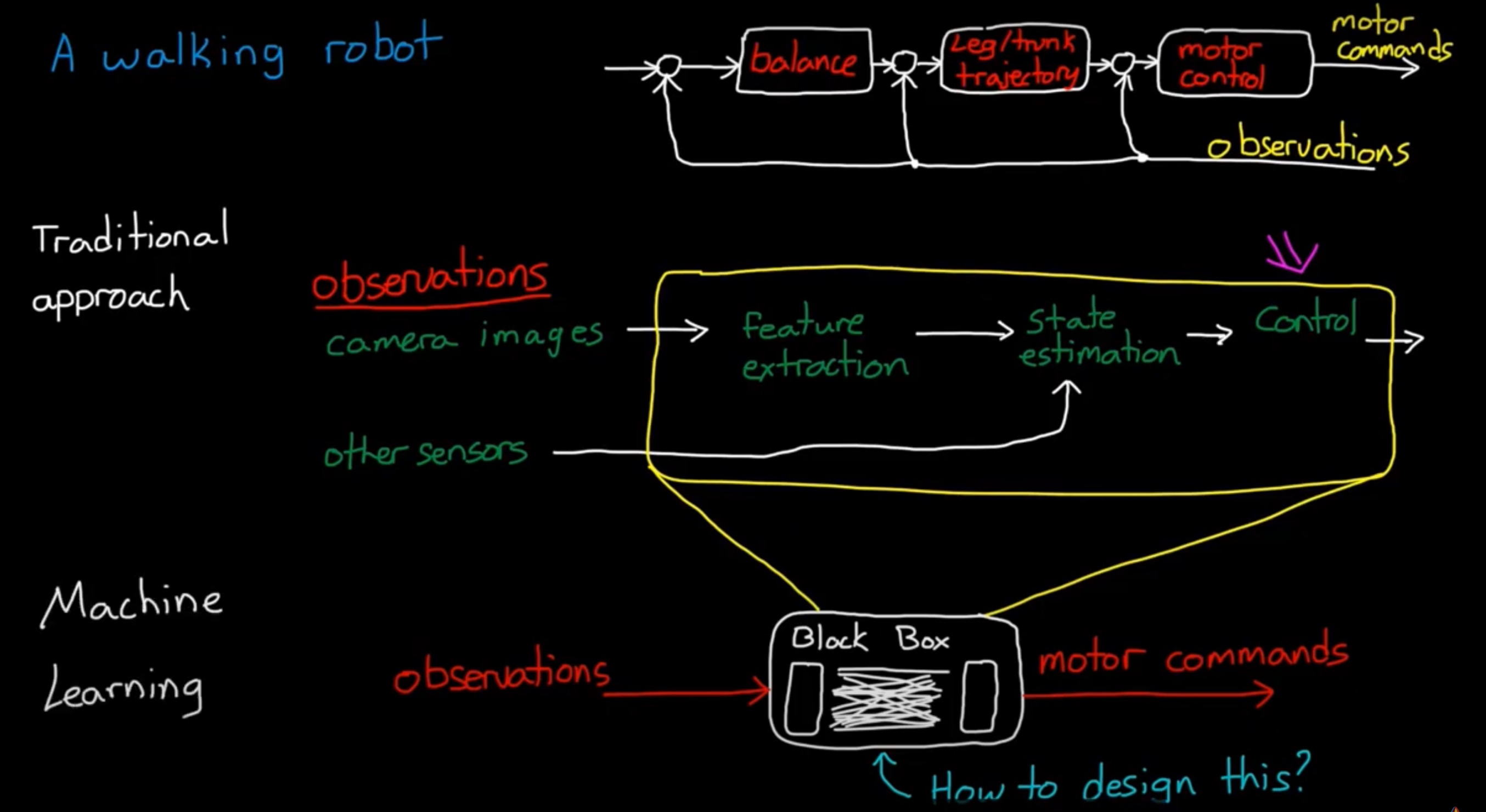
与传统控制的关系:
相似性:
| RL | traditional control |
|---|---|
| agent | controller |
| env | plant + enviroment |
| reward | feedback(error signals) |
| value | optimize function |
不同点:
- 传统的控制:将任务分解成多个任务的串并联,设计(子)控制器
- 机器学习:将控制器压缩成黑盒Black box
强化学习不同于 监督、非监督学习(与静态数据交互),与环境产生交互,产生最优结果的动作序列。
基础概念
RL组成要素Agent、Env
Agent
组成要素:Policy、Value function、Model其中至少一个

策略(Policy):observation to action的映射
- 固定策略:(a = pi(s))给定状态(s),对应fixed的action (a)
- 随机策略:当Agent处于某一个state的时候,它做的Action是不确定的,例如你可以选择study也可以选择game,也就是说你在某一个状态是以一定的概率去选择某一个action。也就是说,策略的选择是一个条件概率(pi(a|s)),这里的(pi)与数序中的(pi)没有任何关系,他只是代表一个函数而已(其实就是(f(a|s)))。
[
pi(a mid s)=Pleft(A_{t}=a mid S_{t}=s ight)
]
函数代表:在状态(s)时采取动作(a)的概率分布。
价值(value function):未来奖励的预测(期望)
前面我们说到过奖励,当Agent在(t)时刻执行某个动作时,会得到一个(mathcal{R_{t+1}})。我们可以想一下蝴蝶效应,这个Action会影响(mathcal{R_{t+1}}),那么他会不会影响(mathcal{R_{t+2}},mathcal{R_{t+3}}...)呢?很可能会的,比如说在电游中,你所做的某个选择肯定会对接下来的游戏产生影响,这个影响可以深远,也可以没那么深渊(对,我说的就是隐形守护者,mmp),因此状态价值函数可以表示为:
[
v_{pi}(s)=mathbb{E}_{pi}left(R_{t+1}+gamma R_{t+2}+gamma^{2} R_{t+3}+ldots mid S_{t}=s
ight)
]
(v_{pi}(s))与策略函数(pi)有关,可以理解为当Agent以策略(pi)运行时,状态(s)的价值是多少。也就是在此状态下,我能够得到多少回报。

模型Model:对env的预测
预测状态:s->s'的概率
[
mathcal{P}_{s s^{prime}}^{a} =mathbb{P} left(S_{t+1}=s^{prime} mid S_{t}=s, A_{t}=a
ight)
]
预测奖励:R的期望
[
mathcal{R}_{s}^{a} =mathbb{E}
R_{t+1} left( mid S_{t}=s, A_{t}=a
ight)
]
(gamma)奖励衰减因子
在上面的价值函数中,有一个变量(gamma) ,即奖励衰减因子,在[0,1]之间。如果为0,则是贪婪法,即价值只由当前的奖励决定,如果是1,则所有的后续状态奖励和当前奖励一视同仁。一般来说取0到1之间的数。
环境的状态转化模型
由于在某个状态下,执行一定的action,能够达到新的一个状态(S_{t+1}),但是(S_{t+1})不一定是唯一的。环境的状态转化模型,可以理解为一个概率状态机,它是一个概率模型,即在状态(t)下采取动作(a),转到下一个状态(s')的概率,表示为(P^a_{ss'})。
探索率(epsilon)
怎么说的探索率呢?它主要是为了防止陷入局部最优。比如说目前在(s_1)状态下有两个(a_1,a_2)。我们通过计算出,发现执行(a_1)的动作比较好,但是为了防止陷入局部最优,我们会选择以(epsilon)的概率来执行(a_2),以(1-epsilon)的概率来执行(a_1)。一般来说,(epsilon) 随着训练次数的增加而逐渐减小。