03. 结构化机器学习项目
第一周 机器学习策略(一)
1.1 动机
当我们想要改进机器学习项目的时候,面临着诸多选择:
- 收集更多数据
- 收集更多样化的数据集
- 使用梯度下降法训练模型更久一些
- 用Adam算法代替梯度下降
- 尝试更大的网络
- 尝试更小的网络
- 尝试dropout
- 增加(L_2)正则化
- 修改网络结构:激活函数、隐藏单元数等
如果选择不对将会浪费大量时间,机器学习策略就是帮助我们去做出正确的选择。
1.2 正交化
在进行调节的时候要尽可能选择正交化的措施,何为正交化呢?吴恩达老师举了一个很好的例子,比如驾驶汽车,方向盘、油门和刹车各自控制一个功能,不存在一个操纵杆同时控制方向和速度,这种设置方法就可以成为正交化。正交化措施使得调节更为简单。
在机器学习中存在以下的流程,而且每一步都有相应的调节措施:
- 用代价函数拟合训练集——更大的网络,Adam算法,……
- 用代价函数拟合验证集——正则化,更大的训练集,……
- 用代价函数拟合测试集——更大的验证集,……
- 在现实世界中成功应用——更改验证集,更改损失函数,……
非正交化的措施,比如早停(early stopping)用来应对过拟合,但这样同时影响训练集和验证集上的表现,并不是一个好的方法。
1.3 & 1.4 单一指标
机器学习就是要不停的做实验、看结果、调节、再实验,有一个单一的实数指标来衡量算法的表现对算法的快速调试很有帮助。
比如分类问题的评价指标有查准率(precision)、查全率(recall),两者经常是矛盾的,所以不如采用统一的评估标准即 F1 score:
( F_1 = frac{2}{frac{1}{P} + frac{1}{R}} )
是前面两者的调和平均数。所以选择一个单一的评价指标很重要!
然而一个机器学习模型有那么多指标需要满足,很难都把他们统一起来。一种方法是将这些指标进行区分,分为满足指标(satisficing metric)和优化指标(optimizing metric),满足指标的意思是只要满足某个范围或者低于某个阈值即可,而优化指标则要求尽可能的减小。
例如:模型的准确率和运行时间两个指标很难统一,那么可以设定运行时间为满足指标,因为大约运行时间低于100ms时,再减少其实对用户的影响不大;而准确率就要设为优化指标,尽可能的优化。所以再调试模型时,我们可以选择运行时间低于100ms中准确率最高的。
1.5 & 1.6 数据集划分
这个问题其实在之前已经提过,我们在训练集上训练模型,在验证集上评估不同的设置,同时继续训练,最后在测试集上进行无偏的估计。训练/开发(验证)/测试集的划分要注意的问题:同分布;深度学习时代验证集和测试集的比例可以相应的减少,不一定是7:3, 6:2:2等。
1.7 更改指标的时机
当进行一个深度学习项目时,要先按照前面讲的设立一个指标,这个指标可能不是最合适的,但是有助于团队工作的快速迭代,否则没有目标的工作可能只是浪费时间。
但当项目取得一定进展之后,可能会发现原来的指标并不是十分合适,比如一个推送猫片(吴恩达老师对猫片情有独钟)的应用,错误率更低的模型有可能将色情图片识别为猫并推送给客户,而另一个错误率高一些的模型不会出现这种情况。显然,用户不想收到色情图片(并不:P),这时候错误率高的模型就成了更好的模型,说明错误率这个指标不再合适,需要更换指标。
1.8 & 1.9 & 1.10 & 1.11 人类的表现水平
现在有很多深度学习方法在一些任务上的表现已经超过人类了,但是在超越人类之后往往提升变得很慢。主要有两个原因:
- 人类的表现接近于贝叶斯最优,所以超越人类之后的提升空间不大;
- 当模型表现比人类表现差的时候,有很多方法可以用来提升性能,比如标注更多数据、人工误差分析等,但超越人类之后这些方法都不再适用,毕竟青出于蓝而胜于蓝,爱莫能助。
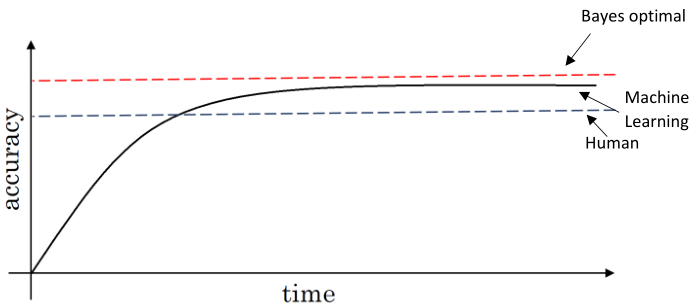
在知道人类可以达到的水平之后,我们可以将其近似为贝叶斯最优去评判一个模型的表现。
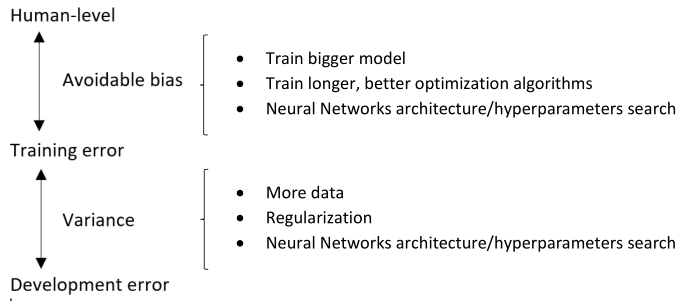
比如,当一个模型的分类错误率非常接近人类水平时,称为可避免偏差较小,这时候可以着重关注减小方差;如果分类错误率还较高时,还是应当想办法降低错误率。这可以通过比较【训练集错误率 - 人类错误率】(衡量可避免偏差)与【测试集错误率 - 训练集错误率】(衡量方差)的大小来确定。
这和之前的做法不同点主要在于我们不再和零误差比较来衡量偏差。
1.12 改善模型表现
总结以下本周的内容,如下图: